Eu vi no Twitter oficial da OpenLedger que a mainnet PoA estava funcionando, era mais de duas da manhã, e eu fiquei totalmente acordado. Sério, faz tempo que eu não acordava só para conferir as novidades de um projeto por causa do lançamento da mainnet.
A história começa no ano passado. A Polychain e a Borderless, duas instituições tradicionais, deram à OpenLedger 8 milhões de dólares na rodada seed. Naquela época, coloquei na minha watchlist. Mas o que realmente me deixou pilhado foi quando, após o lançamento da mainnet em novembro deste ano, passei dois dias revisando toda a documentação e o whitepaper do projeto do zero.
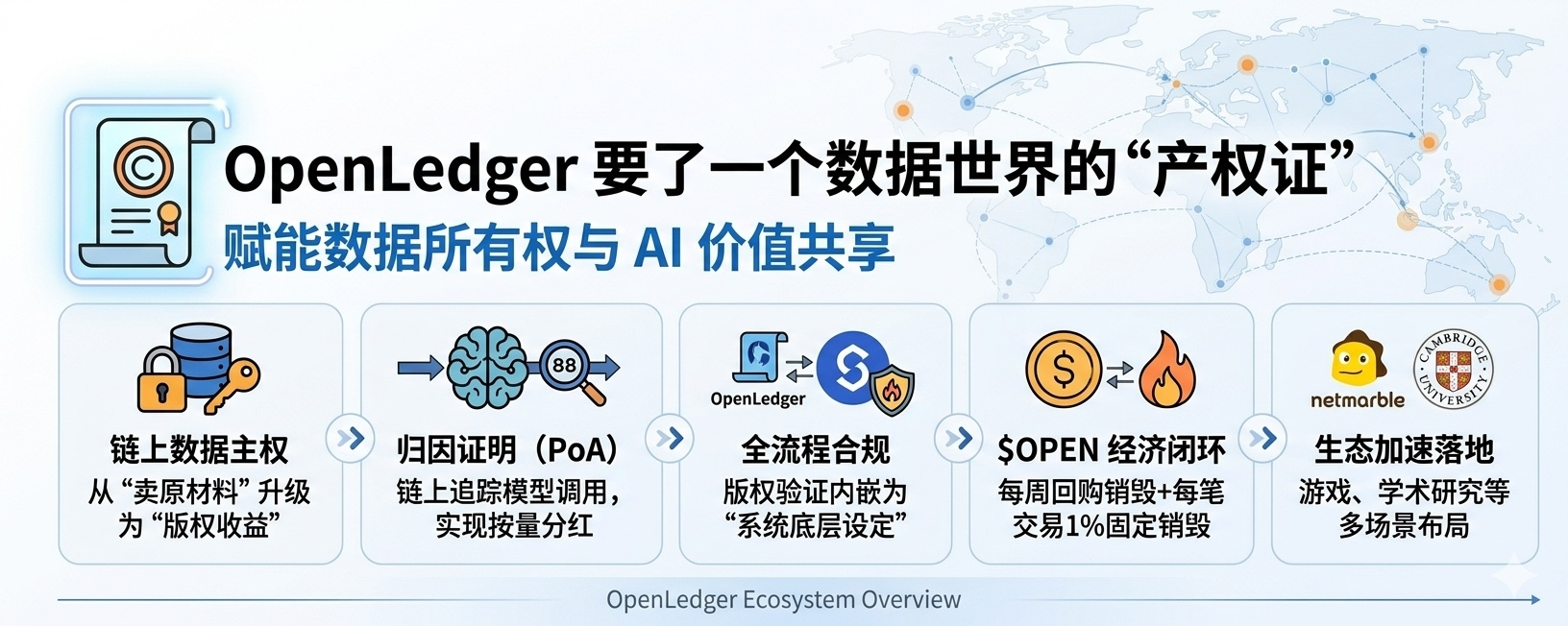
Esse mecanismo de Proof of Attribution da OpenLedger, falando de forma simples, quer resolver um problema que atormenta a indústria de IA há muito tempo: como os provedores de dados conseguem receber o que merecem. Não é uma recompensa única, mas sim que você consiga rastrear em blockchain qual modelo usou seus dados, quantas vezes, e receber uma parte com base no uso real. Um amigo meu, que está mergulhado na pista de dados Web3 há um bom tempo, me contou que tentou rodar o SDK da Datanets e achou que o suporte para conjuntos de dados atualizados continuamente é especialmente amigável, diferente de alguns projetos que só permitem uploads únicos. Isso me faz pensar em uma analogia: vender matérias-primas é uma venda única, mas direitos autorais podem gerar aluguel repetido. O que a OpenLedger quer é esse “certificado de propriedade”, fazendo com que seus dados realmente se tornem um ativo que pode gerar receita continuamente.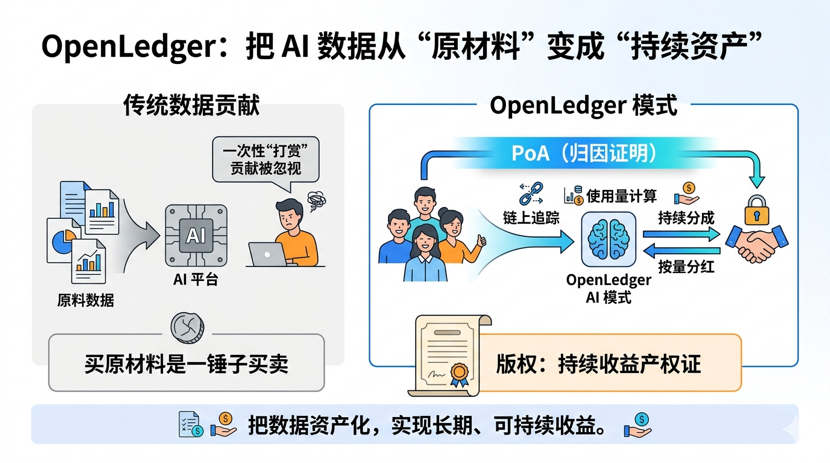
A colaboração com o Story Protocol em conformidade de IP me parece um design bastante inteligente. A Story levantou mais de 100 milhões de dólares da a16z, e o que eles estão fazendo é automatizar registro de direitos autorais, licenciamento e distribuição de royalties. A OpenLedger incorporou essa camada em seu pipeline, o que significa que o modelo de IA deve passar por uma verificação de direitos autorais antes de acessar os dados. Eu verifiquei os dados da WIPO, e o tamanho do mercado global de IP realmente assusta, a demanda por conformidade de IA só vai aumentar. Esse design, no atual ambiente regulatório, é muito mais confiável do que brigar na justiça depois.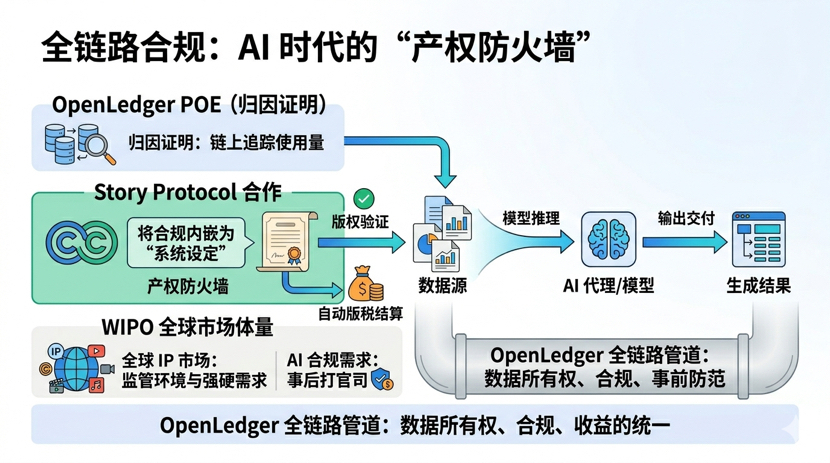
Na parte dos tokens, a lógica de design da \u003cc-14/\u003e cobre vários cenários como staking de dados, chamadas de modelos, liquidação de poder computacional, bloqueio de nós de validação e execução de direitos autorais, cada camada gera demanda de consumo. O recompra e queima semanal, além da queima fixa de 1% por transação, estão continuamente restringindo a oferta. Com múltiplos cenários de consumo e um mecanismo deflacionário, essa combinação mostra que a equipe realmente pensou na economia de tokens.
Recentemente, eles também deram 5 milhões de dólares para a Universidade de Cambridge para pesquisa em IA descentralizada, esse sinal é mais sólido do que muitas ações de marketing. Não estou dizendo que uma colaboração acadêmica significa que a tecnologia é infalível, mas pelo menos a equipe está disposta a investir em algo que requer um tempo de maturação, ao invés de despejar tudo em KOLs para gritar ordens de compra.
Além disso, o gigante dos jogos sul-coreano Netmarble, sob sua marca MARBLEX, já entrou na jogada, integrando uma camada de dados transparente na plataforma de jogos, permitindo que a geração de conteúdo de IA e a economia in-game sejam totalmente verificáveis. Somado à colaboração com equipes como Astro AI e Pundi AI, a Datanets realmente está firmando sua posição como camada padrão de dados de IA descentralizada.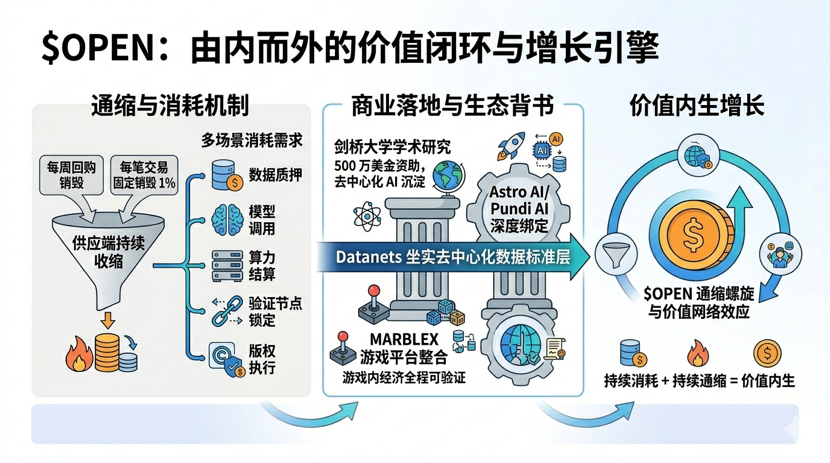
Depois de ver tudo isso, na verdade, não tenho muito o que dizer. Financiamento, tecnologia, colaborações, economia de tokens, respaldo acadêmico, tudo se empilha, a lógica é consistente e a implementação é real. Nos últimos três anos, passei por muitos white papers de projetos, e posso contar com uma mão aqueles que ainda me fazem querer ler letra por letra às duas da manhã. A OpenLedger é um deles.
\u003ct-7/\u003e\u003cm-8/\u003e