Lá em 2024, o cripto chegou a um ponto onde adicionar “IA” na bio de um projeto era o suficiente para fazer as avaliações dispararem. Alguns projetos mal tinham infraestrutura funcionando e ainda assim negociavam como se estivessem construindo o futuro da civilização.
No começo, eu honestamente pensei que OpenLedger era apenas mais uma versão dessa história.
Mas quanto mais eu leio sobre @OpenLedger e OPEN, mais percebo que o projeto está mirando algo muito mais específico do que apenas “IA no blockchain.”
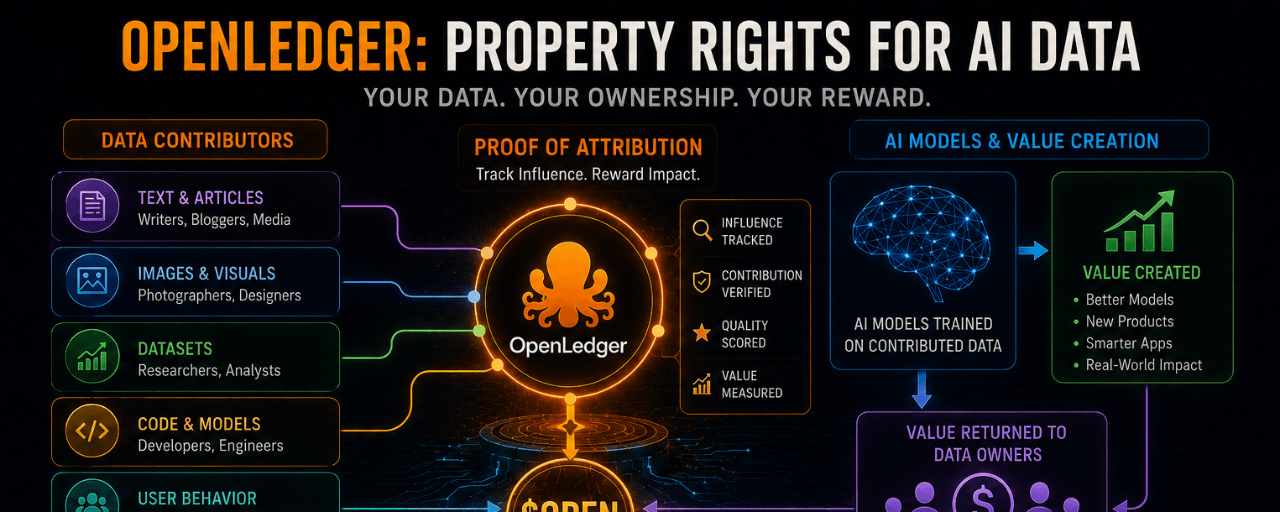
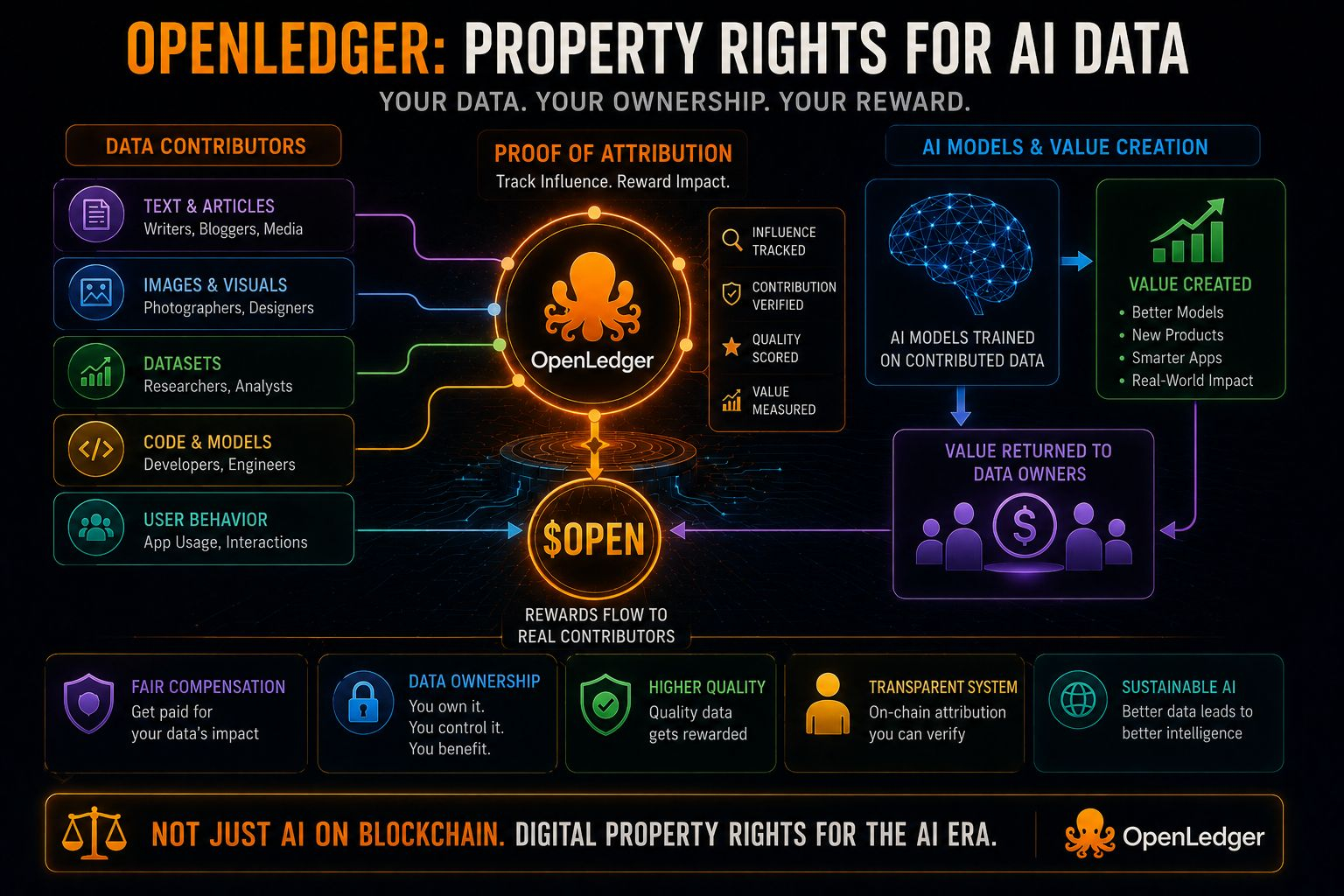
Ele está tentando transformar a propriedade de dados em uma camada econômica real.
E isso muda completamente a conversa.
Agora mesmo, a internet funciona de uma maneira estranha para a IA. Modelos massivos coletam conteúdo, imagens, textos, padrões de comportamento e conjuntos de dados de todos os lugares. Uma vez que o modelo se torna valioso, quase ninguém que contribuiu com os dados originais é remunerado.
A OpenLedger está basicamente tentando resolver isso através de algo que eles chamam de “Prova de Atribuição.”
A maneira mais fácil que posso descrever é assim:
O treinamento moderno de IA é uma sopa gigante de bilhões de pontos de dados misturados. Uma vez que o modelo final produz valor, ninguém sabe qual ingrediente foi o mais importante.
A OpenLedger está tentando rastrear essa influência.
Qual conjunto de dados melhorou a saída?
Qual contribuinte ajudou o modelo a ter um desempenho melhor?
E se a IA gerar valor mais tarde, esses contribuintes podem teoricamente receber recompensas através do OPEN.
Essa é a parte que eu acho que as pessoas subestimam.
Se isso realmente funcionar em escala, o OPEN para de se comportar como um token utilitário normal e começa a parecer mais uma camada de royalties para economias de IA. Quase como os músicos ganhando quando suas músicas são transmitidas, exceto que aqui a “música” é dado que alimenta a inteligência de máquina.
Mas, honestamente, é aqui que o problema mais difícil começa.
Porque uma vez que as recompensas se tornam valiosas, o spam se torna inevitável.
Um conjunto de dados médicos raro pode valer mais do que milhões de postagens sociais recicladas, mas sistemas que recompensam o volume de contribuição frequentemente lutam para separar qualidade de ruído. Já vimos problemas semelhantes em ecossistemas de DePIN e cripto pesados em incentivos, onde a atividade de farming eventualmente diluiu a real utilidade.
É por isso que eu acho que o futuro da OpenLedger depende menos de atrair mais conjuntos de dados e mais de conseguir construir uma Prova de Qualidade forte o suficiente em torno desses conjuntos de dados.
Caso contrário, o OPEN corre o risco de recompensar a inflação de dados em vez de inteligência real.
E talvez essa seja a verdadeira razão pela qual este projeto parece interessante para mim.
À primeira vista, a OpenLedger parece uma blockchain de IA.
Mas, por baixo, pode estar realmente construindo algo muito maior:
direitos de propriedade digital para a era da IA.