What keeps dragging me back on OpenLedger isn't the model.
Not first.
Its the validator.
... annoying, because the clean story wants me to look later. OpenLedger's ModelFactory. inference. Proof of Attribution. payout. all the shiny parts where the system gets to act like it's doing accounting for intelligence instead of the usual black-box theft with better branding.
Fine.
Still not the first thing.
The first thing is some poor bastard staring at a Datanet before training ever starts and deciding what gets to count as “safe enough” to let through.
That decision is carrying way more of the later mess than people like to admit.
Say a data engineer is reviewing a vertical Datanet before a builder touches ModelFactory. Healthcare, legal, research, DeFi code, whatever. Doesn't matter. The queue looks normal enough. Validation tags. contributor history. source metadata. a few rows look thin, a few look weird, a few are technically fine but smell off. Good luck writing “smells off” into a validation rule by the way. Humans keep inventing systems and then acting surprised when judgment leaks back in through the side door.
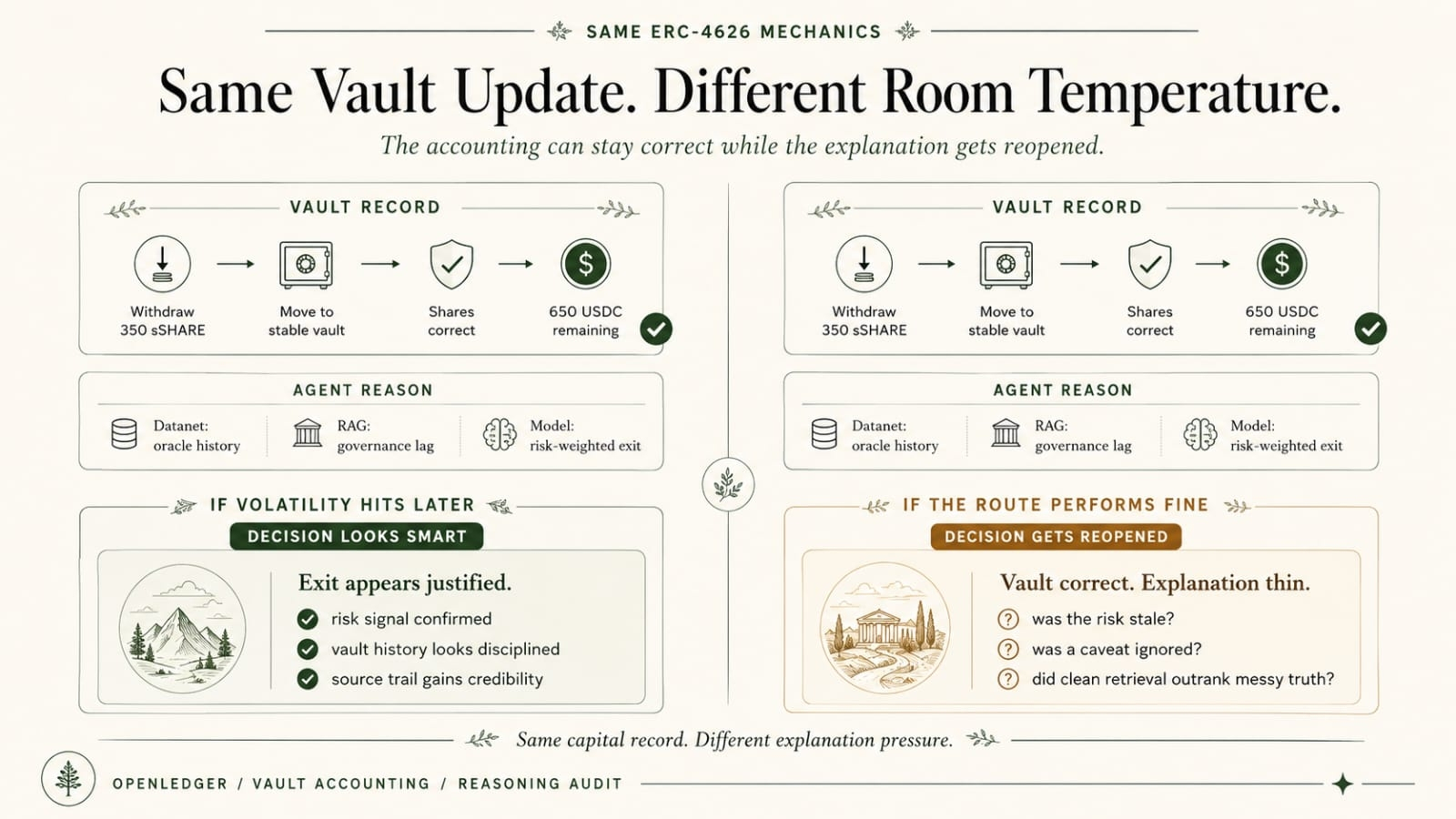
So the engineer filters. approves some. down-ranks some. leaves some out because the source trail is messy or the structure is off or the signal looks too narrow to trust at scale. Routine. boring. invisible. doesn’t feel like model behavior design. feels like hygiene.
That’s the lie.
Because later somebody opens OpenLedger's ModelFactory, picks that Datanet, starts tuning, and thinks they’re choosing data.
They’re not just choosing data.
Theyre inheriting somebody else’s earlier idea of what kind of risk the model is allowed to have.
One validator leaves a weird source out because the provenance is ugly. Another lets a cleaner but flatter one through. Good. Now go call the later model behavior neutral.
That’s the part I keep getting stuck on.
OpenLedger makes the Datanet look cleaner than the actual judgment sitting inside it. That’s useful. Much better than shoving a model into random scraped sludge and praying the output sounds expensive enough to bill for. But once the Datanet starts filtering aggressively enough, it’s not only cleaning signal. It’s shaping which kinds of mistakes survive into training and which ones die upstream without anybody calling that design.
And then later the blame lands on the model like the model invented its own limits out of thin air.
Lovely.
I keep picturing the downstream conversation because it’s always the downstream conversation that gets treated like the first event. Builder says the model is leaning narrow on a certain class of queries. User says retrieval feels repetitive. Some operator looks at inference trace and sees the same sort of source pattern showing up again and again. Payout view later starts concentrating around a thinner contributor band than expected. OpenLedger Proof of Attribution does its job and tracks influence back. Fine.
Then everybody starts asking what’s wrong with the model.
Nobody opens the validation queue first. Of course not.
Maybe.
Or maybe the Datanet decided three steps earlier what kind of model this thing was even allowed to become.
That's way more of the actual OpenLedger job than people like to say out loud. Because the nice version of OpenLedger is “AI but traceable.” Good slogan. The harder version is that once you make the data layer legible, the ugly human judgment upstream becomes legible too, or at least easier to corner.
The validator isn't just cleaning rows there. They’re deciding what kind of model gets to exist later, whether anybody calls it that or not.
Now perfectly. Not alone. Still.
Say the Datanet has borderline rows from contributors with weaker history. Or weird records with ugly provenance but strong edge-case value. Or niche source material that’s structurally messy but actually contains the exact sort of exception logic the model will later need. Somebody has to decide whether “messy but useful” survives. Somebody always does. If that row dies upstream, the later model doesn’t fail because it’s stupid. It fails because the Datanet decided neatness mattered more than that kind of truth.
Then ModelFactory gets blamed for whatever came out clean and thin afterward. Nice little handoff. Very civilized.
And that’s before OpenLoRA even gets involved.
Because once you serve specialization cheaply enough, bad upstream judgment gets to travel farther with lower friction. Adapter loads. specialized path comes online. inference comes back looking tight enough to pass. adapter unloads. beautiful. Meanwhile the thing underneath it may still be inheriting a Datanet that filtered for “safe enough” in a way that quietly cut out the very mess that made the domain real.
Good.
Now the system is efficient at being narrowly wrong.
And OpenLedger is rude enough to leave receipts for that. Which, to be clear, is a good thing. Better this than another AI stack where nobody can see what shaped the output and the whole industry keeps pretending mystery is sophistication. Here at least you can inspect more of the chain. Datanet. contributor history. validation layer. ModelFactory choice. retrieval path. inference trace. Proof of Attribution. reward split. OPEN moving once actual usage turns into settlement.
Useful, sure. It also means the earlier judgment call doesn’t get to hide forever.
I think that’s why this keeps scratching at me. In older systems, validation is easy to romanticize as neutral process. Here it’s harder. Too many later surfaces point back toward it. If a payout row stays flat, if a contributor cluster dominates, if retrieval keeps leaning on the same kind of source, if a model behaves “safely” in exactly the wrong way, the Datanet starts looking less like a dataset and more like an upstream opinion with governance wrappers.
And now somebody has to say that out loud.
Say a validator filters out a bunch of messy DeFi incident reports because the provenance is ugly and the formatting is inconsistent. Fair enough. Nobody wants poison in the training set. Then a builder later fine-tunes through ModelFactory on what survived. Model ships. Queries come in around exploit patterns, weird governance edges, liquidation cascades, the usual cheerful stuff. The model stays neat. Too neat. retrieval log looks thin in exactly the places where ugly history mattered. Inference trace points back to a cleaner Datanet than the real world deserved. Reward split still clears. contributors still get paid. system still looks healthy.
Then somebody finally opens the contributor rows and sees the same narrow part of the Datanet doing more of the work than the clean story implied.
Now the room gets stupid. Was that the training mix, the validator cut, the retrieval layer, or just a builder taking green tags too seriously.
Thats the problem.
The reward path clearing doesn’t prove the earlier judgment was good. It just proves the machine can settle around whatever got through.
And if you don't think that matters, wait until some agent flow sits on top of it. OctoClaw or anything close enough. Then the model isn’t just being narrow in a dashboard. It starts feeding an action trail. A route. A receipt. A sequence somebody might actually rely on. Then the validator’s earlier call on what looked safe enough to train stops being abstract governance housekeeping and starts looking a lot more like hidden product design with money and consequences attached.
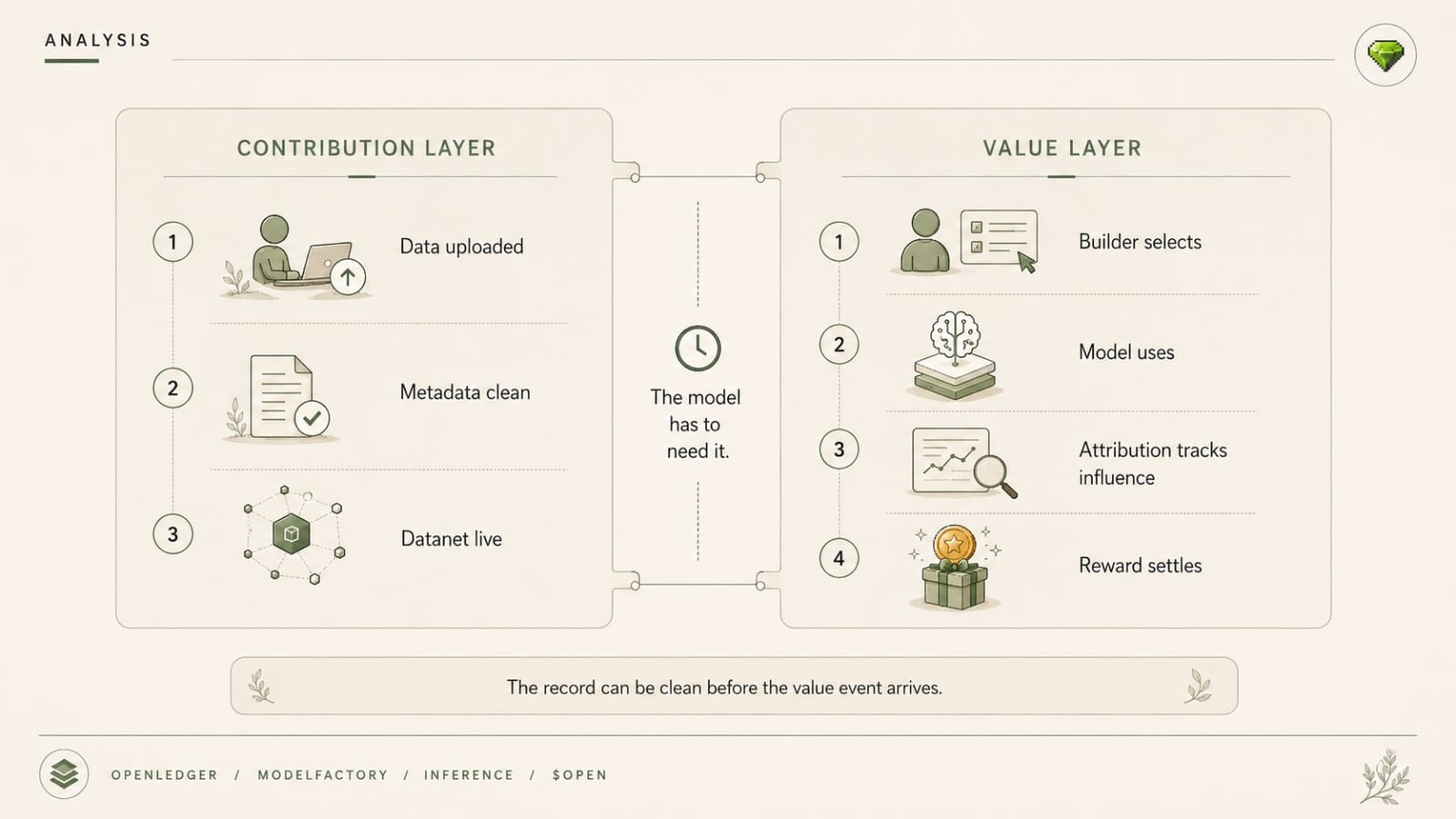
Which is what it was the whole time, honestly.
Everybody wants to argue later about attribution on OpenLedger. Fine. I keep getting stuck earlier than that. When the Datanet is being cleaned up for training, who is deciding what kind of model risk gets to exist later and what kind gets quietly ruled out before the builder even thinks they’re making a choice.
Because once that part sits far enough upstream, everybody downstream gets to act like they’re only reacting to the model.
And maybe they are.
But if the model is already inheriting a validator’s tolerance wearing a cleaner interface and an inference trail, then what exactly is OpenLedger proving later with Proof of Attribution?
The output’s history.
Or the validator’s earlier judgment that quietly decided what kind of model was allowed to exist in the first place.