
Eu me lembro quando todo mundo chamou isso de "Apenas uma Jogada de Eficiência"
Eu me lembro de assistir à primeira onda de hype sobre infraestrutura de serviço de modelos e pensando que isso era apenas computação em nuvem com uma marca melhor. GPUs compartilhadas, troca mais rápida, custos mais baixos. Um ganho limpo. Nada mais profundo acontecendo. Eu estava errado, e demorou mais do que eu gostaria de admitir para descobrir por quê.
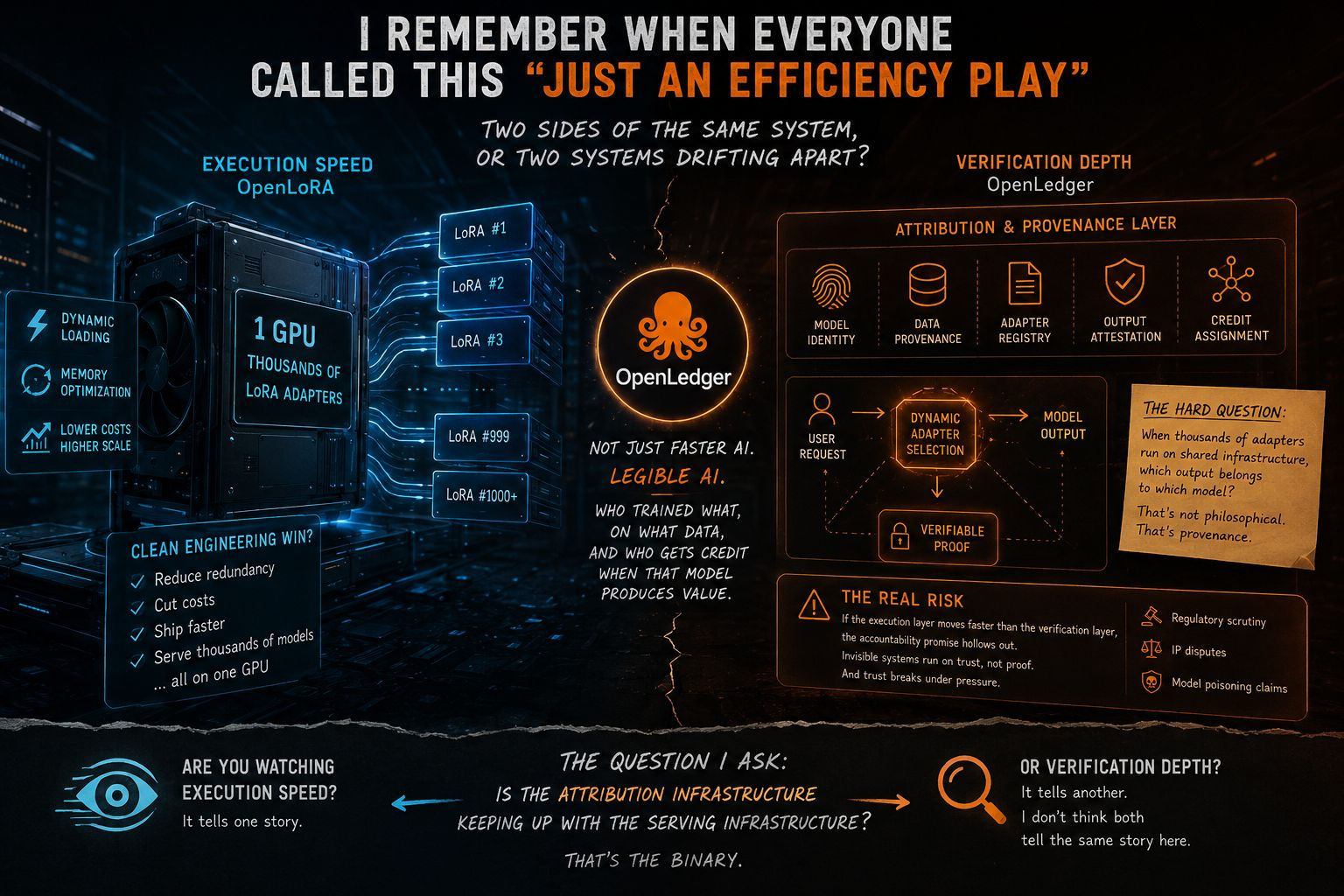
Mas ao longo do tempo, percebi algo que mudou a minha visão sobre toda essa stack. Não se trata apenas de computação. É uma questão de propriedade. A OpenLedger não está tentando tornar a IA mais rápida — está tentando tornar a IA legível. Quem treinou o que, em quais dados, e quem recebe crédito quando esse modelo gera valor. Esse é um problema completamente diferente e, sinceramente, é algo que ninguém estava prestando atenção enquanto todos estavam ocupados avaliando a velocidade de inferência.
A reformulação é importante porque o OpenLoRA realmente impressiona à primeira vista. Uma GPU, milhares de adaptadores LoRA ajustados, carregamento dinâmico, otimização de memória. Quando você lê a arquitetura pela primeira vez, parece uma vitória limpa em engenharia — reduzir redundância, cortar custos, entregar mais rápido. E provavelmente é tudo isso. Mas aqui está o que eu continuei pensando: quando você está alternando dinamicamente entre milhares de adaptadores em uma infraestrutura compartilhada, qual saída pertence a qual modelo? Isso não é uma questão filosófica. É uma questão de proveniência, e em um mundo onde as saídas de IA carregam peso comercial e legal real, isso importa muito.
De uma perspectiva de mercado, é aqui que$OPEN apresenta uma fragilidade real. Se a camada de execução se tornar abstrata o suficiente e o OpenLoRA estiver avançando forte nessa direção, a atribuição se torna genuinamente difícil. Não é difícil politicamente. É difícil tecnicamente. Mudanças de contexto de adaptadores, estados de memória compartilhada, ciclos de carregamento dinâmico... quanto mais rápido o sistema funciona, menos visível se torna a contribuição de cada modelo individual. Sistemas invisíveis funcionam com confiança, não com provas. E a confiança quebra sob pressão de escrutínio regulatório, disputas de propriedade intelectual, alegações de contaminação de modelos. Se a camada de verificação do OpenLedger não conseguir acompanhar o quão abstrata a camada de execução se torna, a promessa de responsabilidade começa a se esvaziar. Esse é o verdadeiro risco. Não a concorrência. Não as liberações de tokens. A coerência interna entre o que o sistema faz e o que pode realmente verificar.

Então, aqui está o que eu realmente observo com$OPEN não o preço, não os anúncios de ecossistema, não os tweets de parcerias. Eu observo se a infraestrutura de atribuição está acompanhando a infraestrutura de execução. Os construtores estão enviando ferramentas de verificação no mesmo ritmo que as ferramentas de eficiência? A camada de coordenação está se tornando mais legível com o tempo ou mais abstrata? Essa é a binária para mim. Ou o OpenLedger está construindo a camada de responsabilidade que torna o OpenLoRA confiável em escala, ou está construindo uma história de verificação em cima de um sistema que já se moveu rápido demais para ser totalmente verificado.
Dois lados do mesmo sistema, ou dois sistemas separados se distanciando? Eu realmente não sei ainda. Mas essa é a pergunta que eu faria a qualquer desenvolvedor construindo sobre esse stack agora.
Você está observando a velocidade de execução ou a profundidade da verificação? Porque eu não acho que ambos contam a mesma história aqui 👇
