And Could Not Afford The Subscription To Access It
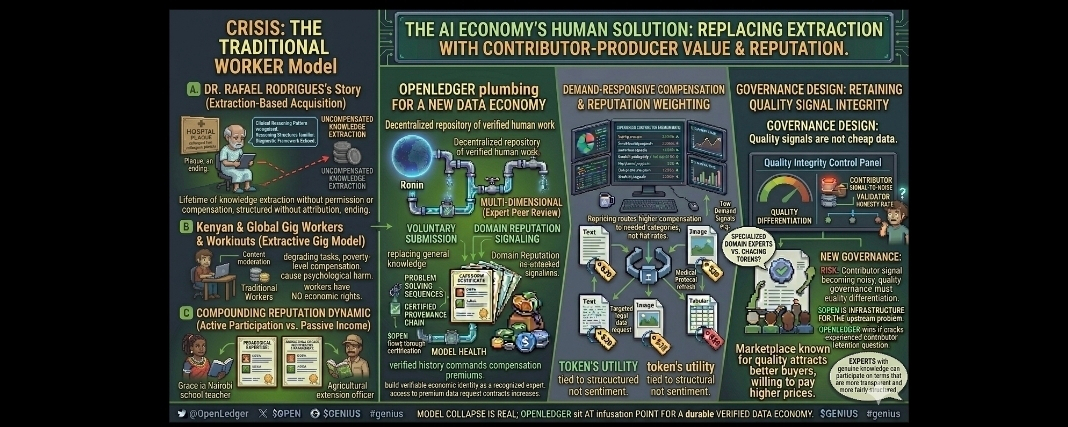
I need to tell you about Dr. Rafael Rodrigues first because his story is the most honest entry point into everything I believe about what OPEN is attempting to fix in the AI economy. Dr. Rodrigues spent forty-one years practicing internal medicine in Sao Paulo and when he retired in 2021 his colleagues threw him a party and his patients sent handwritten letters and his hospital gave him a plaque. Then eighteen months after retirement his granddaughter showed him a popular AI medical assistant and asked him to test it. He spent an hour asking it clinical questions and the experience left him sitting in silence for a long time afterward. The reasoning patterns were familiar. The diagnostic frameworks reflected approaches he recognized. The way it structured differential diagnoses in complex cases echoed the thinking of his generation of Brazilian clinicians specifically. He told his granddaughter that it felt like reading a book written by someone who had studied him without his knowledge and he was not sure whether to feel flattered or violated.
He felt violated. And I think that feeling is the most important feeling in the entire AI economy right now because it is the feeling that millions of professionals around the world have not yet had but will have as AI systems trained on their uncompensated knowledge get deployed into their fields and sold back to them at prices that assume they should be grateful for the access.
This is why I write about @OpenLedger with more personal investment than I write about most projects in this space. The protocol is not solving an abstract infrastructure problem. Its solving the specific human problem that Dr. Rodrigues experienced which is that a lifetime of accumulated expert knowledge was extracted without permission structured without attribution and monetized without compensation and the person who generated that knowledge was left with a plaque on his wall and a subscription paywall between him and the AI that learned everything it knows about internal medicine partially from people exactly like him.
The mechanics of OPEN address this directly in ways I want to explain through another real situation because abstract protocol descriptions do not convey what is actually at stake here. In 2023 a group of Kenyan data workers who had been employed by a contractor working for OpenAI to review and filter harmful content spoke publicly about their working conditions through TIME magazine. They were earning between one and three dollars per hour to review some of the most psychologically damaging content on the internet in order to train content moderation systems used by one of the most valuable AI companies in the world. The work caused documented psychological harm. The compensation was poverty-level by any standard that the technology they were helping build would eventually be sold into. And the workers had no mechanism for asserting any rights over the outputs their labor produced or for building any economic identity from the expertise they were developing through that work.
The OpenLedger contribution model creates a structurally different relationship between workers and the AI training economy. Contributors submit knowledge they actually possess receive OPEN rewards calculated against validated quality rather than time spent performing degrading tasks and build on-chain reputation records that belong to them permanently and compound in value with each subsequent quality contribution. That is not a perfect solution to the labor exploitation problem in AI development. But it is a fundamentally more honest economic architecture than anything those Kenyan workers were offered and the difference between the two models is not cosmetic it is a question of whether the humans who make AI systems function receive anything that respects the genuine value of what they contribute.
My hot take is something I have been reluctant to say directly because it sounds inflammatory until you examine the evidence carefully. The major AI companies are not unaware that their training data acquisition practices raise serious ethical and legal questions. They are aware. The legal teams are aware. The policy teams are aware. The decision to proceed with extraction-based data acquisition at scale was not made in ignorance of its implications it was made because the economic incentives favored speed over ethics and because the people being extracted from had no immediate mechanism for asserting their rights in a way that created meaningful friction for the extracting organization. What changes that calculus is not more strongly worded terms of service or voluntary industry guidelines. What changes it is the existence of an alternative infrastructure that makes verified compensated contribution economically viable for contributors and practically superior for AI developers who need documented data provenance for regulatory compliance reasons.
The Nairobi school teacher named Grace whose story was documented in a 2024 academic paper about informal knowledge sharing in sub-Saharan African educational communities had spent six years developing teaching materials for students learning mathematics in Swahili and posting them in WhatsApp groups and community Facebook pages serving rural schools without adequate textbooks. The materials were eventually found by a researcher documenting informal educational content online and through a chain of data collection that Grace was never part of those materials ended up in a multilingual AI education dataset used by an edtech company operating in East African markets. Grace found out when a parent at her school showed her an AI tutoring app that was explaining mathematics concepts using approaches and examples that she recognized as her own. The company had a terms of service. Grace had never agreed to it. And there was no mechanism anywhere in that chain of events for her to receive acknowledgment that her work had been used let alone compensation for the value it contributed to a commercial product.
And this is the story that connects most directly to what the OpenLedger validator network creates beyond the immediate quality assurance function. When Grace submits her pedagogical knowledge to @OpenLedger the validators who assess her contribution include people with verified expertise in mathematics education and multilingual learning contexts who can accurately evaluate whether her approaches represent genuine pedagogical insight or surface-level content. That expert peer review of her contribution does something that the informal circulation of her materials through WhatsApp groups never did which is create a formal documented record that her work reflects genuine educational expertise assessed by qualified peers. That documentation is the difference between knowledge that can be extracted without acknowledgment and knowledge that exists in a form that asserts its own value through the verification record attached to it.
The compounding reputation dynamic is what I think most potential contributors underestimate when they first encounter the $OPEN earning mechanics and I want to explain it through a practical example rather than an abstract description. Imagine a contributor who works as an agricultural extension officer in rural India and has spent twelve years advising smallholder farmers on crop disease identification and management in specific regional climate conditions. She begins contributing structured knowledge to the OpenLedger network about the specific pathogen patterns and intervention approaches relevant to her region. Her early submissions earn modest rewards as her reputation score is still being established. But over six months of consistent quality contributions her domain reputation compounds to the point where incoming data requests from AI agricultural development teams get routed preferentially to her as a verified expert in her specific regional context. Her reward weight per submission increases. Her access to premium data request contracts in her domain increases. And she has built something that no conventional employment relationship or credential system would have created for her which is a verifiable economic identity as a recognized expert in a knowledge domain that AI development genuinely needs.
What strikes me most about Dr. Rodrigues and Grace and those Kenyan workers is not that their situations are unusual. Its that their situations are completely ordinary and that the extraction they experienced is the default mode of the AI training economy rather than an exception to a more ethical norm. The norm is extraction. The exception is compensation. And the infrastructure that could change that ratio is what @OpenLedger is building with $OPEN as the economic mechanism that makes the alternative viable at scale.
I think about Dr. Rodrigues sitting with his granddaughter staring at the AI that learned from people like him. I think about what he would have felt differently if those forty-one years of clinical knowledge had been contributed voluntarily compensated transparently and documented on-chain in a form that said clearly this knowledge came from practitioners who chose to share it and were respected for doing so. I think the plaque on his wall would have felt like less of an ending and more like the beginning of a different kind of contribution that his expertise still had the capacity to make.
That is the human case for this protocol and it is more compelling than any technical analysis I have written about it.
