
One thing that feels both funny and slightly terrifying about the current AI market is this: some of the world’s biggest AI companies are training billion-dollar models using data from people who don’t even realize they contributed anything.
Photos, articles, voice recordings, browsing behavior… all getting absorbed into AI systems like industrial vacuum cleaners running through the internet 24/7.
I remember reading lawsuits from publishers accusing AI companies of scraping content without permission, and that’s when it clicked for me:
The internet today works like an open field where the biggest machine simply harvests the most data.
At first I honestly grouped OpenLedger into the usual “AI + crypto” narrative wave. You know the type. Add “AI” to the bio, throw in some futuristic graphics, and suddenly valuations start moving like real estate during a speculation boom.
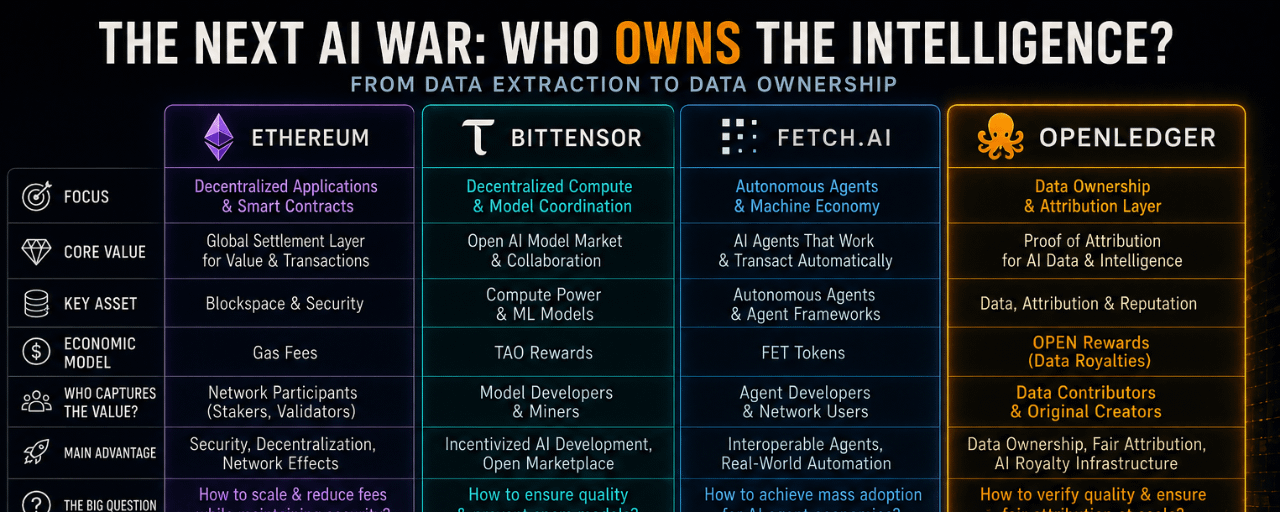
But the more I looked into @OpenLedger and OPEN, the more I realized they are not really competing with Ethereum on smart contracts or trying to out-compute networks like Bittensor.
They’re aiming at something completely different.
Ownership.
That’s the important part.
Ethereum became valuable because it monetized transactions and settlement. Bittensor focuses on decentralized compute and model coordination. Fetch.ai leans into autonomous agents and machine-to-machine interactions.
OpenLedger is trying to build a layer that answers a different question entirely:
Who owns the intelligence created from data?
And honestly, that question feels much bigger than people realize.
Right now the AI economy works in a very one-sided way. Users generate data for free, platforms collect it, AI models transform it into products, and value flows upward. Almost nobody who contributed the original data captures meaningful upside later.
OpenLedger wants to change that through Proof of Attribution.
The simplest way I can explain it is this:
Modern AI training is like throwing billions of ingredients into one giant soup. Once the soup tastes good, nobody knows which ingredient actually created the flavor.
OpenLedger is trying to track that contribution layer.
Which dataset improved the model?
Which contributor added something unique?
And if AI outputs later create value, contributors can theoretically receive OPEN rewards connected to that influence.
That’s why I think comparing OpenLedger directly to Ethereum misses the point.
Ethereum behaves more like a global settlement bank.
OpenLedger feels closer to an intellectual property registry for AI economies.
And if that system actually works, the implications become pretty wild. Because suddenly AI companies may no longer access valuable datasets “for free.” Attribution itself becomes infrastructure.
Which also explains why this idea is controversial.
Big Tech probably benefits enormously from the current system where attribution remains blurry. The moment data ownership becomes traceable and economically enforceable, training AI models becomes far more expensive.
At that point, OPEN stops looking like a normal utility token.
It starts looking more like a data royalty layer for the internet.
But honestly, this is also where the biggest weakness appears.
Incentives attract spam.
Every Web3 system eventually learns this lesson the hard way.
A rare medical dataset could be more valuable than millions of low-quality social posts, but networks rewarding contribution volume often struggle to separate scarcity from noise. Without strong Proof of Quality systems, OPEN risks becoming an incentive token for recycled or low-value data farming instead of real intelligence creation.
And maybe that’s the bigger thing people still underestimate about AI infrastructure.
The next AI war may not be about who has the smartest model.
It may be about who owns the rarest and most trustworthy data.
The first era of the internet rewarded whoever captured attention.
The next era might reward whoever controls verified knowledge.
That’s why OpenLedger feels interesting to me.
On paper, it’s an AI blockchain.
But underneath, it may actually be trying to build property rights for digital intelligence itself.