
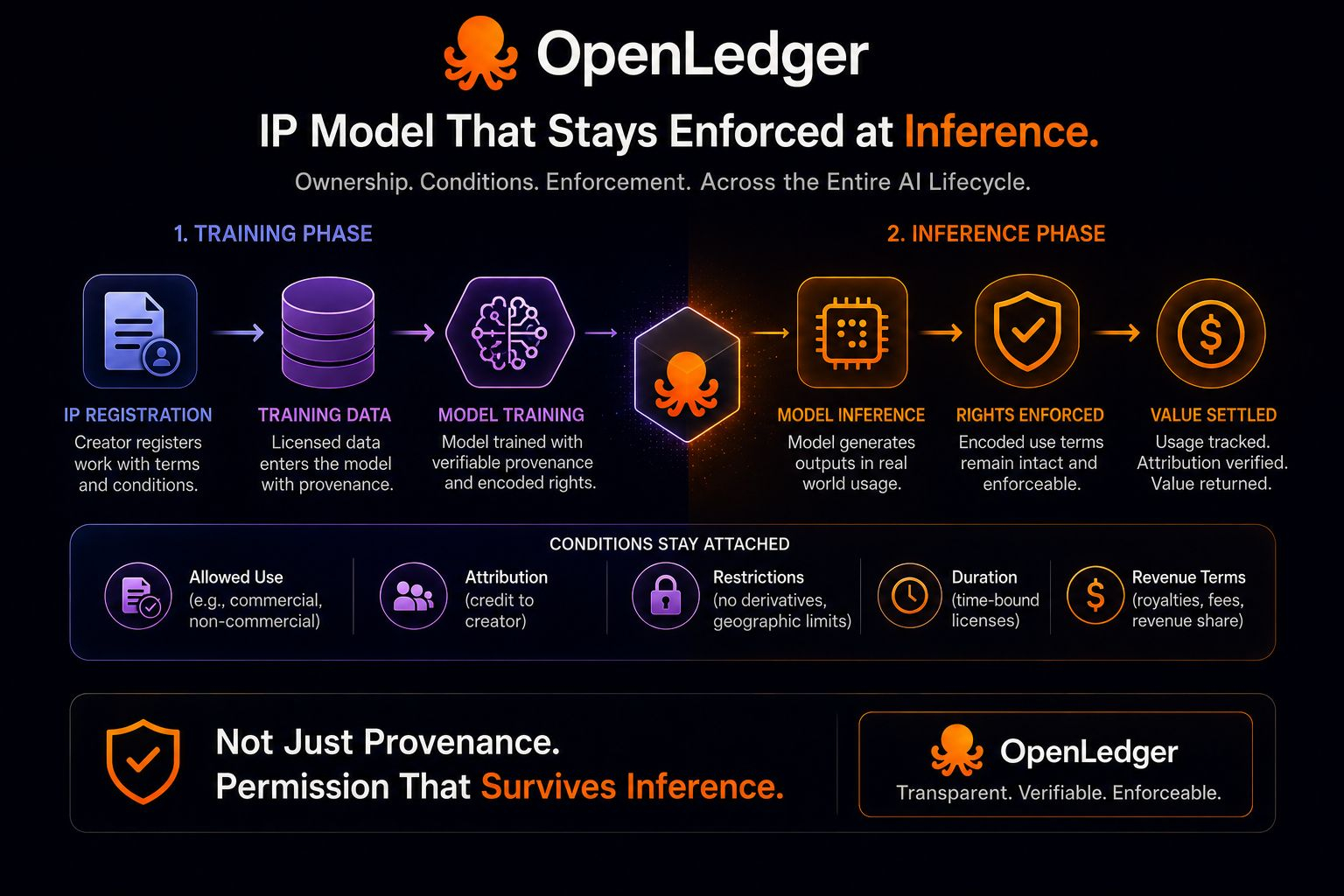
A primeira vez que li sobre a infraestrutura de PI da OpenLedger, pensei que o ponto principal era a proveniência.
Dados de treinamento, modelos e propriedade intelectual entrando em sistemas de IA com propriedade atrelada em vez de desaparecer em pipelines opacos depois. Honestamente, isso já parecia útil por si só. Um criador poderia pelo menos provar onde algo entrou na rota e sob quais condições se tornou disponível.
No início, tratei esse ponto de entrada como a parte difícil.
Se a propriedade permanecer visível no início, se o ativo carregar uma proveniência legível antes do treinamento começar, então o sistema já parece mais responsável do que a maioria dos pipelines de IA hoje. O trabalho não começa mais como entrada anônima.
Mas então eu parei na parte sobre codificar o uso permitido tanto durante o treinamento quanto na inferência.
Isso mudou a maneira como eu olhava para tudo.
Porque o treinamento é apenas uma fase onde a permissão importa. O momento mais difícil chega depois, quando o modelo está realmente sendo usado. A inferência é onde as saídas são geradas, decisões são tomadas, valor é criado, e onde as condições originais anexadas a um trabalho permanecem significativas ou silenciosamente desaparecem de fundo.
É aí que a reivindicação do OpenLedger se torna muito maior do que a infraestrutura de registro.
Um registro de proveniência limpo na entrada é útil, mas não resolve completamente o problema de coordenação por si só. Um titular de direitos pode permitir que seu trabalho entre em um sistema sob condições específicas, mas se essas condições se tornarem ilegíveis uma vez que o modelo comece a operar, então a parte importante do caminho de permissão quebra exatamente onde a atividade econômica começa a acontecer.
E a redação do OpenLedger importa aqui porque estende explicitamente a lógica além da proveniência sozinha. A integração não é descrita apenas como rastreamento de propriedade em torno de dados de treinamento e modelos. Ela descreve o uso permitido permanecendo codificado entre o treinamento e a inferência juntos.
Isso significa que a fase de inferência não é um problema extra adicionado depois.
Esse é o teste de pressão real para ver se a estrutura de permissões sobrevive uma vez que o modelo entra em uso real.
Quanto mais eu refletia sobre essa ideia, mais o OpenLedger deixava de parecer apenas uma camada de registro e começava a parecer uma tentativa de manter os fluxos de permissão de IA legíveis após a implantação, e não apenas antes.
E, honestamente, isso provavelmente é um problema de infraestrutura muito mais difícil do que a maioria das pessoas percebe à primeira vista.