Agora há um ritmo familiar nesta indústria. Uma nova ideia surge, muitas vezes fundamentada em algo realmente pensativo. Promete corrigir uma ineficiência que todos aceitaram em silêncio. Recontextualiza um problema com o qual aprendemos a conviver como algo solucionável. E por um momento, parece progresso—não o tipo barulhento e especulativo, mas algo mais estrutural.
Então o tempo passa. Usuários chegam. Fricções aparecem em lugares que não eram óbvios na teoria. E o que antes parecia um sistema elegante começa a revelar suas concessões.
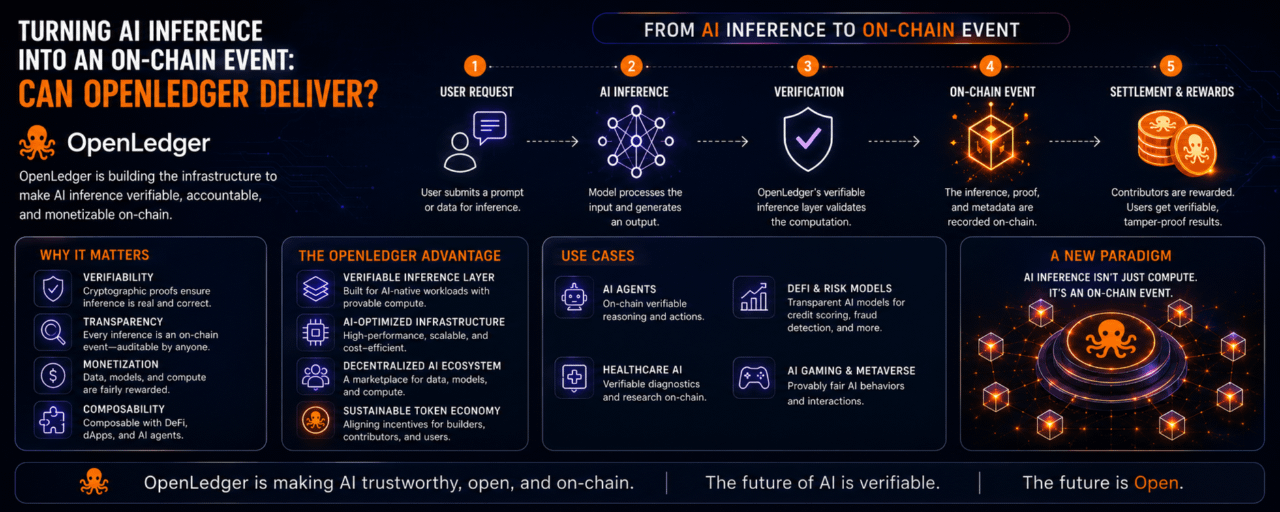
Eu me pego pensando na OpenLedger em algum lugar dentro desse ritmo.
A distância, a premissa é atraente. A maioria dos sistemas blockchain hoje opera sob uma espécie de transparência radical que raramente questionamos mais. Cada wallet é visível. Cada transação é permanente. Padrões comportamentais podem ser rastreados, reconstruídos e muitas vezes previstos. Para os primeiros adotantes, essa abertura parecia uma característica—um antídoto para sistemas financeiros opacos e intermediários ocultos. Mas, ao longo do tempo, começou a parecer menos uma transparência e mais uma exposição.
Se você passa tempo suficiente na blockchain, começa a notar isso de maneiras sutis. Transações grandes atraem atenção antes de se concretizarem. Estratégias são copiadas em minutos. Históricos de wallets se tornam marcadores de reputação, queira você ou não. Para traders individuais, isso pode ser inconveniente. Para instituições, criadores ou qualquer um operando com capital significativo ou modelos proprietários, isso se torna algo mais próximo de uma limitação estrutural.
Sistemas abertos são úteis, mas nem tudo se beneficia de ser permanentemente visível.
É aqui que a OpenLedger se posiciona de forma diferente. Ela propõe um modelo onde dados, inferência de IA e atividade do usuário podem ser expostos, controlados e—importante—monetizados de maneira seletiva. Em vez de tratar cada interação como um evento totalmente público, tenta criar uma estrutura onde o valor ainda pode ser verificado na blockchain sem exigir total transparência dos dados subjacentes.
Em teoria, isso é uma tentativa de reequilibrar algo que a cripto se inclinou longe demais. A ideia de que tudo deve ser público por padrão sempre foi mais ideológica do que prática. A maioria dos sistemas do mundo real—financeiros, criativos ou computacionais—depende de algum grau de acesso controlado. Não a segredo por si só, mas a discrição como um requisito funcional.
A abordagem da OpenLedger parece reconhecer isso. Sugere que a inferência de IA em si—algo inerentemente ligado a dados, modelos e contexto—pode se tornar um evento on-chain recompensável sem expor totalmente as entradas ou processos internos por trás disso. Essa é uma mudança interessante. Reestrutura a inferência não apenas como computação, mas como uma ação econômica que pode ser precificada, rastreada e compensada.
Mas é também aqui que a incerteza começa.
Transformar a inferência em algo recompensável on-chain soa limpo em abstração. Na prática, levanta uma série de perguntas que são menos sobre arquitetura e mais sobre comportamento. Quem é realmente incentivado a participar de tal sistema? Os desenvolvedores estão dispostos a se integrar a uma estrutura que adiciona camadas de controle e visibilidade condicional? Os usuários se importam o suficiente com a propriedade dos dados para tolerar a complexidade adicional que geralmente vem com isso?
Porque a complexidade tem uma maneira de se esconder em sistemas assim.
Isso nem sempre aparece no whitepaper ou nas primeiras demos. Surge mais tarde, quando alguém tenta construir algo real. Gerenciar permissões, precificar o acesso a dados, verificar inferências sem expô-las—essas não são interações triviais. Cada camada introduz decisões, e decisões introduzem atrito. E atrito, na maioria dos casos, é onde a retenção de usuários começa a erodir.
Há também a questão da demanda, que tende a ser menos discutida em projetos em estágio inicial. É uma coisa criar um sistema onde contribuintes de dados e agentes de IA podem monetizar suas atividades. É outra garantir que haja uma demanda consistente e orgânica por esses dados e essas inferências. Sem isso, o sistema corre o risco de se tornar autorreferencial—valioso dentro de sua própria estrutura, mas desconectado da utilidade externa.
Eu já vi versões disso antes. Não na forma exata que a OpenLedger toma, mas na suposição subjacente de que um melhor controle e modelos de propriedade mais sutis levarão naturalmente à adoção. Às vezes isso acontece. Mas muitas vezes, os usuários gravitacionam para o que é mais fácil, não para o que é mais principiado.
A conveniência sempre teve uma vantagem silenciosa sobre a soberania.
Isso não significa que o problema que a OpenLedger está abordando não seja real. Se alguma coisa, o desconforto em torno da transparência na blockchain provavelmente crescerá à medida que mais participantes sérios entrem no espaço. Instituições não vão operar confortavelmente em ambientes onde cada movimento é visível. Criadores hesitarão em expor os dados por trás de seu trabalho se puderem ser replicados livremente. Mesmo usuários individuais, ao longo do tempo, podem começar a questionar a permanência de seu histórico financeiro e comportamental.
Nesse sentido, a direção @OpenLedger que está explorando parece inevitável. A indústria provavelmente se moverá em direção a sistemas que permitam uma visibilidade mais controlada e divulgação seletiva. A questão não é se essa mudança acontecerá, mas como acontecerá—e quais designs podem sobreviver ao contato com o uso real.
O que me deixa cauteloso não é a ideia em si, mas a tradução da ideia para a experiência.
Há uma diferença entre um sistema que pode teoricamente equilibrar transparência, privacidade, propriedade e utilidade, e um que as pessoas realmente querem usar. O primeiro é uma conquista de engenharia. O último é um produto. E a cripto, apesar de toda sua sofisticação técnica, tem lutado para superar consistentemente essa lacuna.
Se a OpenLedger tiver sucesso, não será porque sua arquitetura é sólida—embora isso importe. Será porque consegue esconder sua complexidade atrás de uma interface e experiência que parecem intuitivas. Será porque os desenvolvedores acham mais fácil, e não mais difícil, construir dentro de suas restrições. Será porque os usuários podem participar sem precisar entender os mecanismos subjacentes de permissões de dados e mercados de inferência.
Isso é uma barra muito mais alta do que parece à primeira vista.
Há também a questão do tempo. A curiosidade inicial pode sustentar um projeto por um tempo, especialmente em um espaço que está sempre procurando a próxima narrativa. Mas a sobrevivência a longo prazo depende de algo mais silencioso: uso repetido, demanda sustentada e uma integração gradual em fluxos de trabalho que existem além do público nativo de cripto.
É aqui que muitos projetos reflexivos começam a desaparecer. Não porque estavam errados, mas porque não conseguiram manter a relevância uma vez que o interesse inicial se dissipou.
Então, eu me encontro em algum lugar no meio com @OpenLedger . Posso ver a lógica. Posso até concordar com a premissa de que tratar a inferência de IA como um evento on-chain recompensável e parcialmente privado é um passo em direção a um sistema mais maduro. Mas também aprendi a ter cuidado com ideias que parecem muito alinhadas.
O verdadeiro teste não é se o sistema funciona, mas se continua funcionando quando pessoas que não se importam com sua filosofia começam a usá-lo.
E isso deixa uma pergunta em aberto que nenhuma arquitetura sozinha pode responder:
A OpenLedger pode se sustentar sob a pressão lenta e desigual da adoção no mundo real, onde conveniência, hábito e indiferença muitas vezes importam mais do que o design?