When I first looked at @OpenLedger 's Proof of Attribution, I thought the main issue was fairness. Pay the people who contribute useful data, and the system becomes more honest. But that view feels too simple now.
The harder question is not who contributed. The harder question is whose contribution actually changed the answer.
That is where influence score I(di, y) matters. In plain words, di means one data point, y means one model output, and I measures how much that data point shaped that specific output. It turns attribution from a broad ownership claim into a narrower measurement problem.
On the surface, a contributor uploads data into a DataNet and waits for value to return. Underneath, the system has to ask whether that data merely existed in the training environment or whether it carried real weight when the model produced a result.
That difference is quiet, but it changes the reward logic completely.
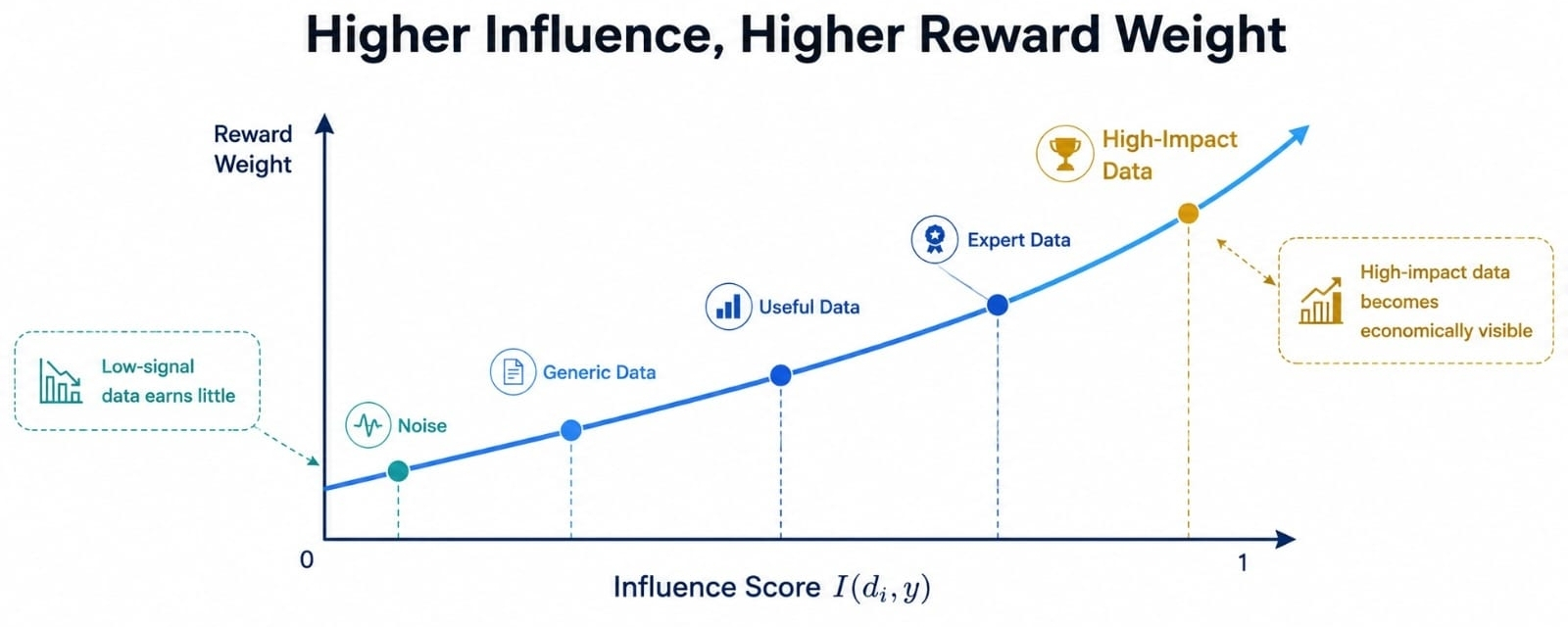
If 100 contributors provide data, a flat reward model may treat participation as value. That creates a weak incentive. People can chase volume, duplicate material, or submit low-signal data that looks active but does not improve the model under pressure.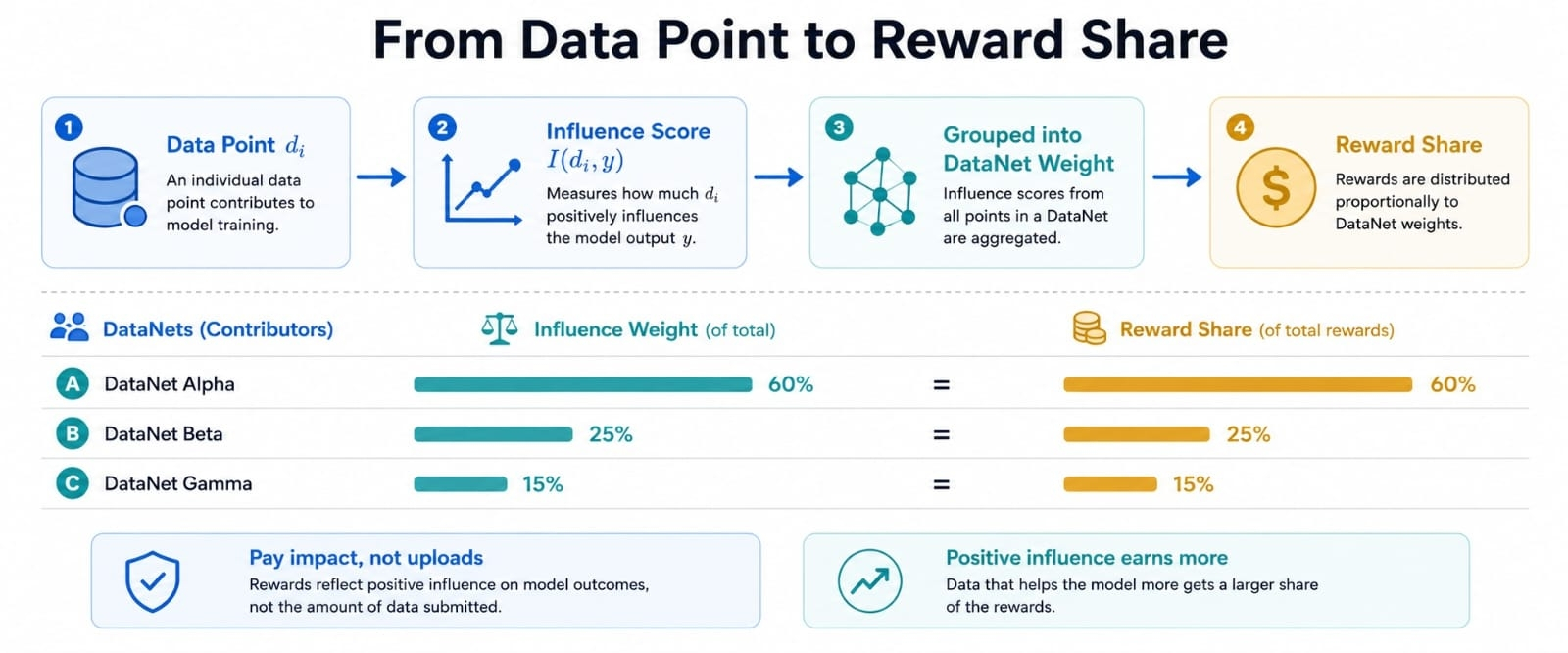
I(di, y) pushes against that. It asks for influence, not noise. If one data point improves confidence, relevance, or accuracy for an output, it should earn more weight than ten generic points that sit nearby but do not matter much.
Understanding that helps explain why attribution math is more than a payment tool. It is also an incentive filter. A contributor is not rewarded simply because their data entered the system. They are rewarded because their data still shows up in the behavior of the model.
A simple reward split shows the idea. If one DataNet carries 60 percent of measured influence for a valuable output and another carries 40 percent, rewards can move with that proportion instead of being guessed manually. The number is not just accounting. It is a way to make contribution harder to fake.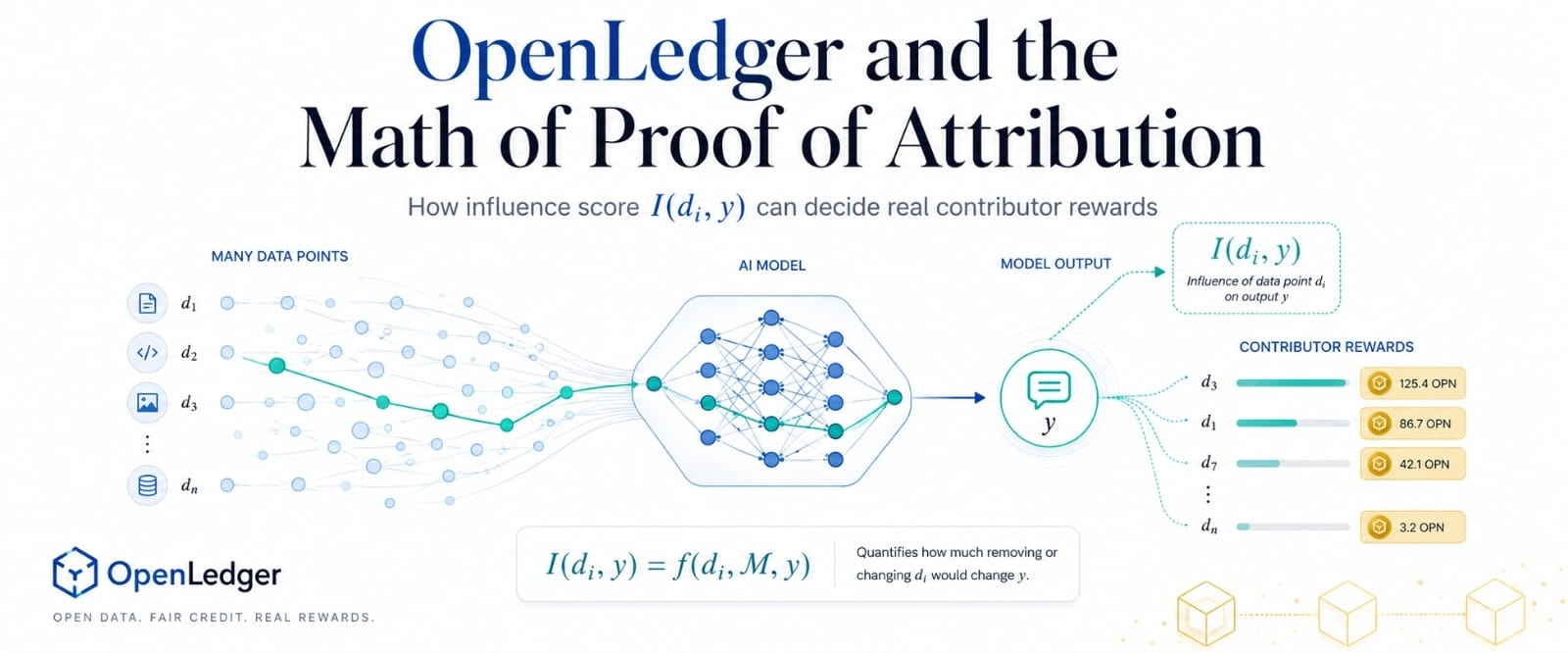
That creates another problem. Influence scores can look cleaner than reality. AI outputs are often shaped by overlapping data, repeated patterns, and indirect signals. A high score may reflect true usefulness, but it may also reflect memorization, duplication, or data designed to trigger attribution.
So OpenLedger’s strongest version cannot depend on I(di, y) alone. It needs records, hashes, timestamps, deduplication, validation, and governance around thresholds. The formula can measure pressure, but the system still has to decide what level of influence deserves payment.
The quieter issue is trust. Once real rewards are attached, every score becomes economic ground. Contributors will test the edges. Governance will face disputes. Markets will ask whether the attribution layer is predictable enough to price contribution fairly.
If this holds, #OpenLedger is not only building a reward system for AI data. It is testing whether AI contribution can become measurable infrastructure.
The real achievement is not proving that data was present. It is proving that the data mattered.

