OpenLedger and the Quiet Problem of Who Owns Intelligence
I keep wondering who actually benefits from the current AI economy.
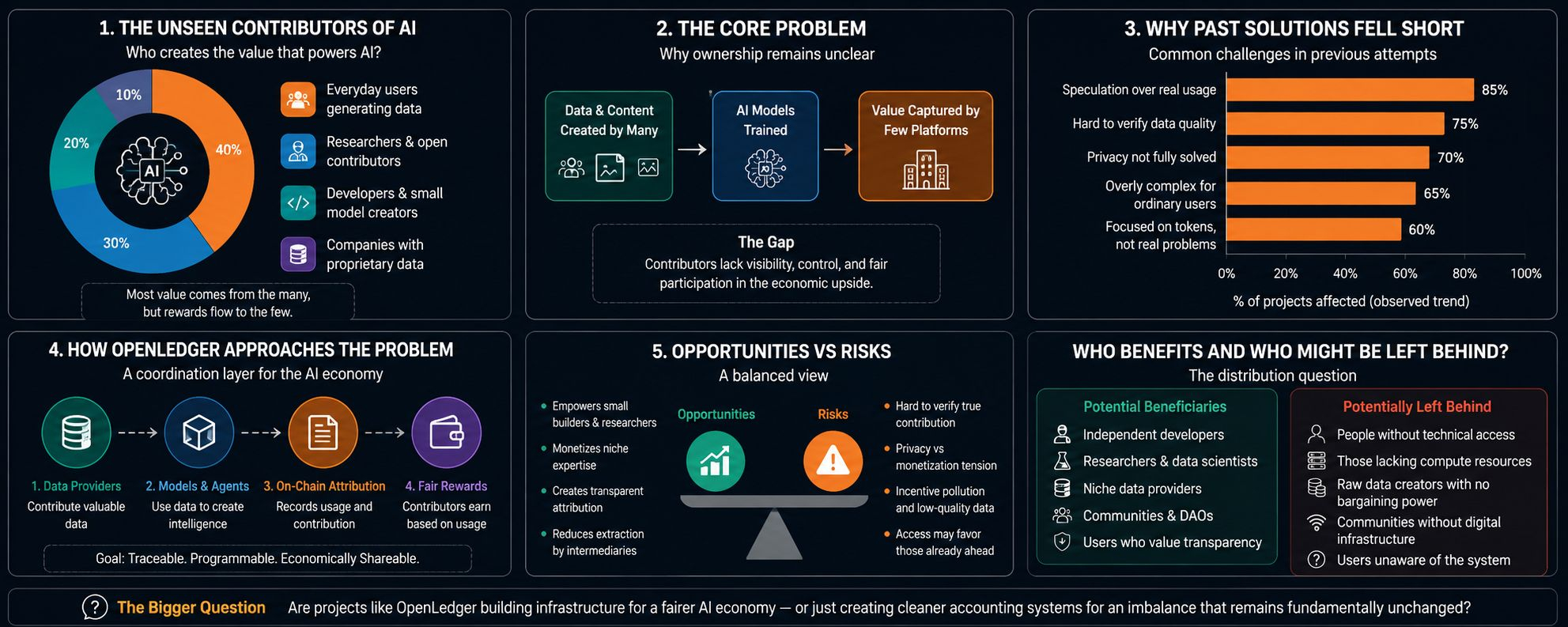
Not the companies building the largest models. Not the investors funding infrastructure. I mean the people whose data quietly trains these systems every day. The researchers sharing open datasets. The developers refining small models in public. The communities generating the information that eventually becomes machine intelligence.
For years, the internet operated on an unspoken trade. People produced value while platforms captured most of it. Social media monetized attention. Search engines monetized intent. Cloud providers monetized computation. AI accelerated this pattern because modern models depend on enormous amounts of human-generated material, yet the individuals supplying that material rarely participate in the economic upside.
That imbalance is not new. What feels different now is the scale.
As AI systems become more capable, data itself starts looking less like content and more like infrastructure. A high-quality dataset can shape the behavior of a model just as much as code can. Specialized medical data, financial behavior, regional languages, industrial workflows — all of these become economically valuable once models learn from them. Yet ownership around this value remains unclear. Most contributors still hand over information without visibility, bargaining power, or long-term control.
The crypto industry has tried to address similar coordination problems before. Decentralized storage networks attempted to distribute infrastructure ownership. Tokenized computing projects tried to create open marketplaces for hardware resources. Data marketplaces appeared in several cycles, usually promising fair compensation for contributors.
Most struggled for the same reasons.
The incentives often attracted speculation instead of real usage. Data quality became difficult to verify. Privacy concerns remained unresolved. Many projects focused more on token mechanics than the practical realities of sharing sensitive information. In some cases, the systems became so complex that ordinary participants could not understand what they were actually contributing or risking.
That is partly why projects like OpenLedger are drawing attention now. Not because they claim to solve everything, but because they are approaching the problem from a slightly different direction.
OpenLedger describes itself as an AI-focused blockchain designed to unlock liquidity around data, models, and autonomous agents. Underneath the terminology, the idea is fairly simple. If AI systems increasingly depend on valuable digital resources, then perhaps those resources should become traceable, programmable, and economically shareable in a more transparent way.
What I find interesting is that OpenLedger does not only focus on moving tokens between wallets. It focuses on attribution.
Who contributed the data?
Which model used it?
How should rewards be distributed if an AI system generates value later?
Those questions sound administrative at first, but they touch one of the deeper tensions inside the AI industry. Modern AI systems often operate like black boxes built on invisible labor. OpenLedger appears to be attempting something closer to an accounting layer for AI contribution.
The design choices reflect that goal. Instead of treating blockchain purely as a payment network, the project positions it more like a coordination system. Data providers, model creators, and agent operators can theoretically interact inside the same economic environment while keeping records on-chain. In practical terms, that could mean contributors receive compensation tied to usage rather than surrendering assets outright.
At least conceptually, it is an attempt to move AI economies away from pure extraction.
Still, there are reasons to remain cautious.
One issue is verification. AI systems are messy. Data passes through pipelines, transformations, retraining cycles, and fine-tuning processes. Tracking contribution accurately is far harder than tracking financial transactions. A blockchain can record events, but it cannot automatically determine whether a dataset was meaningful, harmful, duplicated, biased, or legally questionable.
There is also the privacy problem.
Many valuable datasets cannot simply become open economic assets. Healthcare records, enterprise workflows, legal documents, and personal communications all contain sensitive information. Even if systems use encryption or permission layers, the tension between monetization and privacy does not disappear. In fact, monetization may increase pressure to expose information that should remain protected.
I also think there is a cultural risk that the crypto sector still underestimates. Financializing every layer of digital behavior can create distorted incentives. Once data becomes a yield-generating asset, contributors may optimize for volume instead of quality. Platforms may reward engagement over accuracy. Agents may produce synthetic activity purely because the system rewards measurable output.
The internet already struggles with incentive pollution. AI could amplify it further.
And then there is the question of access.
Projects like OpenLedger may empower smaller developers who currently lack access to large proprietary datasets. Independent researchers could potentially monetize niche expertise instead of relying entirely on large technology firms. That sounds positive.
But sophisticated infrastructure often benefits participants who already possess technical knowledge, compute access, or institutional resources. The people generating raw data may still capture only a small fraction of the value created downstream. A decentralized system does not automatically produce an equal system.
Sometimes it simply redistributes power among different intermediaries.
What makes this space difficult to evaluate is that the underlying problem is real. AI development is becoming increasingly centralized around a handful of companies with enormous compute budgets and private datasets. At the same time, the broader public continues supplying the raw informational material that trains these systems.
That imbalance probably cannot continue indefinitely without creating political, economic, or social backlash.
The harder question is whether blockchain-based coordination actually improves the situation, or whether it simply creates another financial layer around the same extraction model under a different vocabulary.
Maybe the future AI economy does require transparent systems for attribution and compensation. Maybe contributors deserve programmable ownership over the intelligence their data helps create. Or maybe the attempt to tokenize every relationship inside AI will introduce new distortions that become visible only years later.
I am not sure anyone fully knows yet.
The more interesting question may be whether projects like OpenLedger are building infrastructure for a fairer AI economy — or merely building cleaner accounting systems for an imbalance that remains fundamentally unchanged.
