OpenLedger Is The Only Protocol I Have Found That Is Building A Technical Response To What That Means For AI
I want to tell you about a moment that happened in a Reddit thread in early 2024 that I think about more than I should. A user posted what they thought was an original question about career decisions and within forty minutes had received sixty-three responses. When they went back later to reread the thread carefully they noticed something deeply unsettling which was that a significant portion of the responses followed identical structural patterns used the same transitional phrases and arrived at suspiciously similar conclusions despite appearing to come from different accounts with different posting histories. They posted a follow-up saying it felt like they had been talking to a room full of people where half the room was not actually there. The comment got thousands of upvotes from people who said they had experienced the exact same thing and could not find language for it until that moment.
The dead internet theory used to be fringe. It is not fringe anymore. Researchers at institutions including MIT and Oxford have published studies documenting measurable increases in the proportion of AI-generated content circulating across major platforms and the numbers are not small or ambiguous. Estimates from 2024 research suggest that between 15 and 20 percent of content on major English-language social platforms is now generated primarily by AI systems rather than by humans and the detection methods used in those studies were specifically designed to be conservative rather than to maximize the detected proportion. The real number is likely higher and growing faster than the methodologies used to measure it can track.
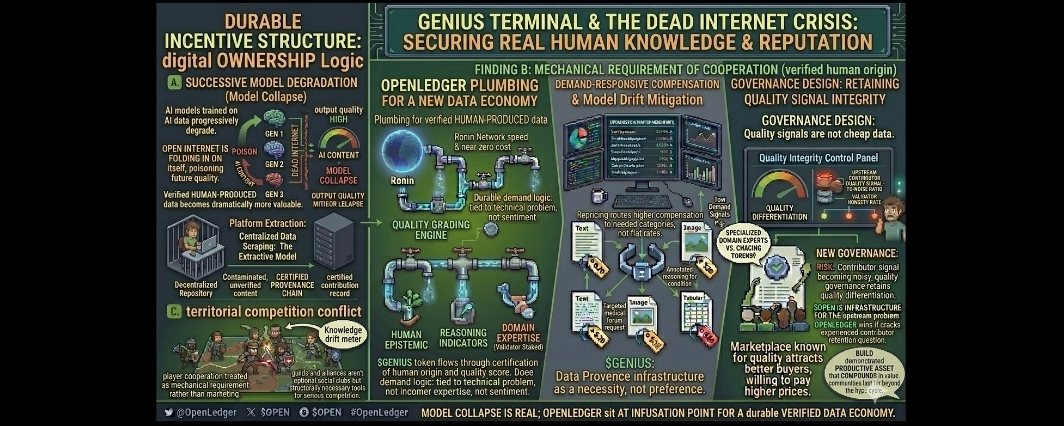
This is the context that makes what @OpenLedger is building feel genuinely urgent to me in a way that goes beyond the standard AI infrastructure investment thesis. $OPEN is not just building a data marketplace. Its building the verification layer that distinguishes genuine human knowledge from the synthetic imitation of human knowledge at a moment when that distinction is becoming harder to make and more consequential to get right than at any previous point in the history of the internet.
My hot take on the dead internet situation is something I have said to colleagues and watched make them uncomfortable. The AI companies that scraped the internet for training data over the last decade were not just collecting human knowledge. They were consuming the feedstock that made the internet worth scraping in the first place and as the models trained on that feedstock begin generating the majority of new internet content the quality of what future models train on degrades in a compounding cycle that has no natural stopping point. The dead internet is not just a cultural problem about authenticity and connection. Its a technical crisis about the long-term viability of using internet-scale data collection as a training strategy and the organizations most exposed to that crisis are the ones whose entire model development roadmap depends on continuing to do exactly that.
The human provenance verification system that OpenLedger has built into its contribution architecture is a direct technical response to this crisis and I want to explain how it works at a concrete level because the abstract description obscures the genuine sophistication of what has been built here. When a contributor submits knowledge to the network the validation layer does not simply assess whether the content is accurate or well-formatted. It assesses a multidimensional profile of the submission that includes indicators of genuine human epistemic process meaning the specific patterns of reasoning organization and knowledge boundary behavior that characterize how real human experts think through problems as opposed to how language models generate text that resembles that thinking. The validators who assess those indicators are themselves verified domain experts whose track records are on-chain and whose economic incentives are explicitly aligned with accurate detection rather than high approval rates.
And here is the thing about that verification process that most coverage misses completely. The dead internet problem makes verified human provenance more valuable every single day that passes without a solution. A verified human knowledge contribution to the OpenLedger network today carries something that the same contribution made two years from now will carry with even greater premium because the proportion of accessible human-verified training data relative to total available data shrinks continuously as AI content generation scales. The scarcity dynamic is not speculative it is arithmetically inevitable given current content generation trajectories and any contributor who builds verified reputation in the OpenLedger network now is accumulating a position in an appreciating category.
But I want to tell you about a specific real situation that brought this home for me in a way that pure analysis never does. In late 2024 a medical information community that had operated for eleven years as a peer-to-peer forum where patients with rare diseases shared treatment experiences and coordinated research into conditions that mainstream medicine underserved discovered through an investigation by a health journalist that the platform had been quietly modifying its terms of service in ways that granted broad AI training rights to all historical and future content. The community had produced over two million posts representing genuine patient experiences diagnostic observations and treatment outcome data that existed nowhere else in the medical literature because the conditions involved were too rare to attract formal research funding. That accumulated knowledge was being transferred to AI health companies without individual contributor consent and without any compensation mechanism for the thousands of patients who had documented their most vulnerable experiences on the platform under a different set of expectations.
The patients who built that community are not going to get that data back. The terms of service were technically legal even if they were ethically indefensible. And the AI health products trained on their experiences will be sold to healthcare systems without any acknowledgment that the training data came from a community of sick people who shared their suffering freely because they thought they were helping each other.
I want to be precise about what the OpenLedger model would have meant for that community had it existed as the contribution infrastructure rather than a conventional platform. The contributors would have entered a documented economic relationship with explicit terms established before contribution rather than retroactively modified by a platform deciding to monetize its historical content library. Their contributions would carry on-chain provenance records that exist independently of any platform decision about how to use them commercially. The $OPEN reward mechanism would have returned economic value to the people who generated the knowledge rather than to the intermediary that accumulated it. And most importantly the contributors would have owned a verifiable record of their expertise that translated into continued earning potential rather than a historical contribution that they surrendered entirely the moment they hit submit.
The regulatory environment is moving in the direction that makes the OpenLedger model increasingly necessary rather than merely preferable. The EU AI Act enforcement mechanisms for high-risk AI systems require documentation of training data consent and provenance that conventional scraping and platform-based collection cannot provide. Proposed data governance frameworks in multiple jurisdictions are moving toward individual data rights models where contributors have legally enforceable claims over how their knowledge gets used commercially. The compliance cost of building AI systems on unattributed scraped data is increasing and the premium on data with clean documented voluntary contributor provenance is increasing proportionally.
And the engagement economy angle is something I find genuinely fascinating about where $OPEN sits strategically right now. The same platforms that scraped contributor knowledge for AI training are now implementing AI-generated content at scale to fill engagement metrics as organic human content creation declines in response to the degraded community experience that AI content flooding creates. That cycle is self-reinforcing in a direction that accelerates the dead internet dynamic and degrades platform value simultaneously. OpenLedger offers contributors something that no conventional platform offers which is a reason to produce their best most genuine work specifically for the protocol rather than sharing it freely in spaces where it will be extracted without compensation. That migration of genuine human expertise from extraction-based platforms toward compensation-based protocols is not happening overnight but the directional pressure is real and I think it will become increasingly visible in the quality differential between what gets contributed to verified networks versus what gets posted freely on platforms where contributor rights remain unprotected.
I keep thinking about that Reddit user who realized they were talking to a room where half the people were not actually there. What @OpenLedger is building is infrastructure that lets you know when the person you are learning from is genuinely there and has genuinely spent a career accumulating the knowledge they are sharing with you. In a world where that certainty is becoming rare it is also becoming valuable in ways that current OPEN pricing does not yet fully reflect.
The dead internet is not the future. Its Tuesday. And the protocol designed to verify that human knowledge is still real and still worth paying for is more relevant today than it was when the first line of its architecture was written.
