Eu estava pensando em @OpenLedger da direção oposta hoje.
Geralmente, quando a galera discute projetos de blockchain com IA, eles começam falando sobre a oportunidade. Os dados se tornam monetizáveis. Modelos viram ativos. Agentes se tornam atores econômicos. A liquidez entra em lugares onde o valor costumava estar preso. Essa é uma tese interessante, e é parte do motivo pelo qual $OPEN continua aparecendo nas conversas sobre infraestrutura de IA.
Mas a pergunta mais útil pode ser menos confortável: o que poderia desacelerar isso?
Não porque a ideia é fraca. Na verdade, é o oposto. Ideias de infraestrutura fortes muitas vezes falham ou se movem lentamente quando colidem com comportamentos existentes, regulamentações, estruturas de custos e hábitos institucionais. Então, em vez de tratar #OpenLedger como uma resposta definitiva, pode ser melhor perguntar o que precisa dar certo antes que ela se torne amplamente utilizada.
O Problema Antes do OpenLedger
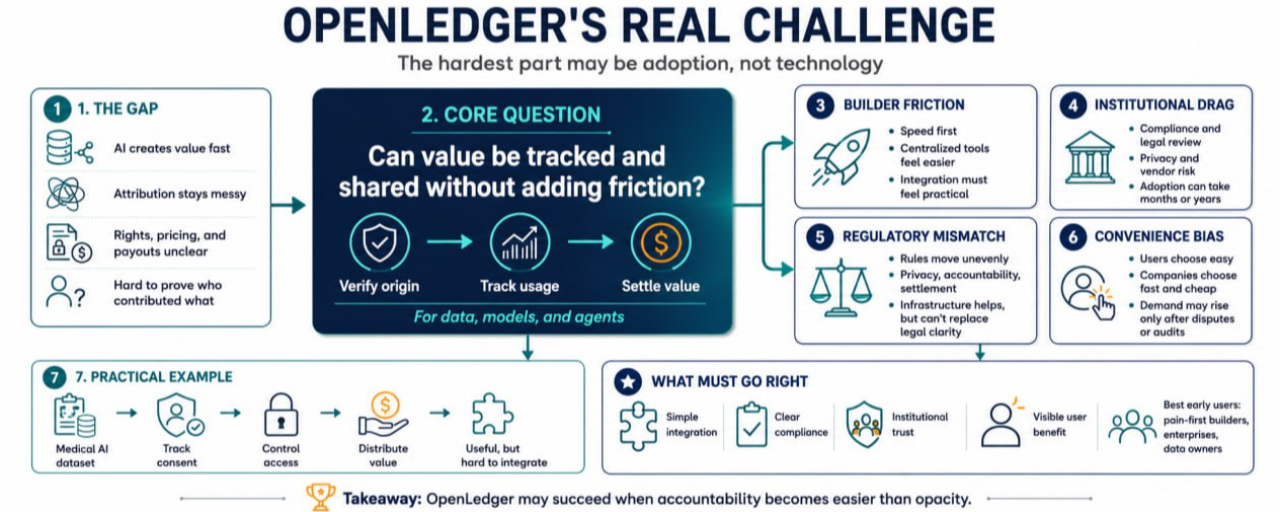
A IA já está se espalhando pelos fluxos de trabalho empresariais, mas a camada econômica ao redor dela é confusa.
Uma empresa pode usar dados de terceiros, ajustar modelos, implantar agentes e automatizar decisões sem ter uma maneira limpa de rastrear quem contribuiu com o quê. Os usuários frequentemente não sabem como seus dados são usados. Os construtores podem não saber como precificar ativos de IA. As instituições podem querer melhores trilhas de auditoria, mas hesitam em expor operações sensíveis. Os reguladores ainda estão tentando entender onde a responsabilidade começa e termina.
Isso cria uma lacuna estranha. A IA pode criar valor rapidamente, mas provar de onde esse valor veio é muito mais difícil.
O foco do OpenLedger em desbloquear liquidez para monetizar dados, modelos e agentes fala diretamente para essa lacuna. No entanto, ter o problema certo não garante uma adoção fácil.
Risco Um: Os Construtores Podem Evitar Fricções Extras
Os construtores geralmente se preocupam primeiro com a velocidade.
Se um desenvolvedor pode lançar um aplicativo de IA usando uma API centralizada, um banco de dados simples e um provedor de pagamento, ele pode não se importar imediatamente com uma atribuição ou liquidação mais profunda. Equipes em estágio inicial estão frequentemente lutando por usuários, não projetando uma infraestrutura econômica perfeita.
Esse é um verdadeiro risco de adoção para o OpenLedger. Mesmo que fluxos de dados verificáveis e trilhos de monetização sejam úteis, os construtores precisam que eles pareçam práticos. Se a integração parecer pesada, a documentação parecer confusa ou os benefícios chegarem muito tarde, muitas equipes podem adiar o uso.
O desafio não é apenas técnico. É comportamental. As pessoas adotam infraestrutura quando ela remove a dor que já sentem.
Risco Dois: As Instituições Se Movem Devagar
As instituições podem precisar de uma infraestrutura semelhante ao OpenLedger, mas raramente são adotantes rápidos.
Bancos, seguradoras, empresas de saúde, universidades, empresas de logística e agências públicas se preocupam com conformidade, aquisição, revisão legal, risco de fornecedores, privacidade de dados e aprovação interna. Mesmo quando os benefícios são óbvios, a implementação pode levar meses ou anos.
Para as instituições, a promessa de monetizar fluxos de dados de IA não é suficiente. Elas precisam de confiança de que o sistema pode atender aos padrões de auditoria, requisitos de segurança, obrigações de relatórios e expectativas regulatórias.
É aqui que @OpenLedger precisa ser mais do que uma rede interessante. Tem que se tornar chato da melhor maneira possível: confiável, compreensível e fácil de justificar dentro de um comitê de riscos.
Risco Três: Os Reguladores Podem Não Se Movimentar em Sincronização
A regulamentação de IA ainda é desigual.
Uma jurisdição pode focar na privacidade. Outra pode focar na responsabilidade do modelo. Outra pode se preocupar com a liquidação financeira, proteção do consumidor ou localização de dados. Para um sistema que lida com ativos de IA, direitos de dados, atividade de agentes e distribuição de valor, isso cria um ambiente complexo.
O OpenLedger poderia ajudar tornando os fluxos mais transparentes e rastreáveis. Mas os reguladores podem ainda discordar sobre o que conta como prova aceitável, uso legal de dados ou compensação justa.
Essa incerteza pode desacelerar a adoção. As instituições podem esperar por regras mais claras antes de se comprometer profundamente. Os construtores podem evitar casos de uso regulamentados. Os usuários podem permanecer céticos se não entenderem como seus direitos estão protegidos.
A infraestrutura pode suportar conformidade, mas não pode substituir a clareza legal.
Um Exemplo Prático: Um Conjunto de Dados de IA Médica
Imagine que uma empresa quer construir uma ferramenta de IA que ajuda clínicas a analisar formulários de admissão de pacientes.
Os dados têm valor. O modelo tem valor. O agente que roteia casos tem valor. Mas os riscos são sérios. A privacidade do paciente deve ser protegida. O consentimento deve ser claro. O acesso deve ser controlado. Se a ferramenta melhora os resultados ou reduz custos, pode haver perguntas sobre quem se beneficia financeiramente.
Uma infraestrutura no estilo OpenLedger poderia ajudar a rastrear permissões, uso e distribuição de valor. Isso seria importante para construtores, instituições, usuários e reguladores.
Mas a adoção ainda seria difícil. Organizações de saúde podem se preocupar com a exposição à conformidade. Advogados podem questionar se o modelo de liquidação se encaixa nas regras existentes. Pacientes podem não confiar em promessas vagas sobre monetização de dados. A integração com sistemas antigos pode ser cara.
Portanto, a proposta de valor é real, mas o caminho não é automático.
Risco Quatro: O Mercado Pode Preferir Conveniência
O maior risco pode ser que muitas pessoas digam que querem transparência, mas escolham conveniência.
Os usuários clicam nos termos que não leem. As empresas escolhem ferramentas que são mais baratas e rápidas. Os construtores otimizam para a velocidade de lançamento. As instituições costumam atrasar mudanças de infraestrutura até que o risco se torne inevitável.
Isso não significa que o OpenLedger não possa funcionar. Significa que a demanda pode crescer gradualmente, especialmente após disputas, auditorias ou pressão regulatória tornarem os sistemas de IA opacos mais custosos.
Em outras palavras, a necessidade do OpenLedger pode se tornar óbvia apenas quando a maneira atual de construir IA começar a falhar sob pressão do mundo real.
Conclusão Fundamentada
Os usuários mais prováveis do OpenLedger podem ser construtores que já sentem a dor da atribuição da IA, monetização de dados, liquidação de agentes ou conformidade institucional. Também pode atrair proprietários de dados que querem compensação, empresas que precisam de auditabilidade e equipes construindo fluxos de trabalho de IA onde a confiança importa mais do que a velocidade sozinha.
Pode funcionar se #OpenLedger tornar a verificação e a distribuição de valor mais simples do que gerenciar acordos privados, auditorias manuais e registros de propriedade pouco claros. Poderia falhar ou se mover lentamente se a integração for muito difícil, se as regulamentações permanecerem confusas ou se usuários e empresas continuarem escolhendo conveniência em vez de responsabilidade.
É por isso que vejo $OPEN menos como uma narrativa simples de IA e mais como um teste do comportamento do mercado. As pessoas querem apenas uma IA mais inteligente ou também querem sistemas de IA que possam provar como o valor é criado e compartilhado?
Não é aconselhamento financeiro.
Qual você acha que é a maior barreira para o OpenLedger: regulamentação, adoção dos construtores, confiança institucional ou conscientização dos usuários?