
Tem algo que percebi bastante tarde sobre a OpenLedger que continuo voltando e não consigo resolver totalmente na minha cabeça.
Estive pensando sobre agentes de IA há um tempo. Não de uma forma abstrata como as pessoas discutem em threads do Twitter sobre crypto. Mais de uma forma prática — o que realmente acontece quando um agente começa a tomar decisões que afetam dinheiro real, contratos reais, resultados reais para pessoas reais.
E quanto mais penso nisso, mais percebo que a conversa está acontecendo no nível errado.
Todo mundo está falando sobre capacidade. Quão inteligente é o agente. Quão rápido ele executa. Quantas tarefas ele pode lidar simultaneamente. Essas coisas são importantes, obviamente. Mas não são a parte difícil.
A parte difícil é algo muito mais chato e muito mais importante.
O que acontece quando o agente erra.
Eu paro aqui porque é aqui que fica realmente interessante para mim.....
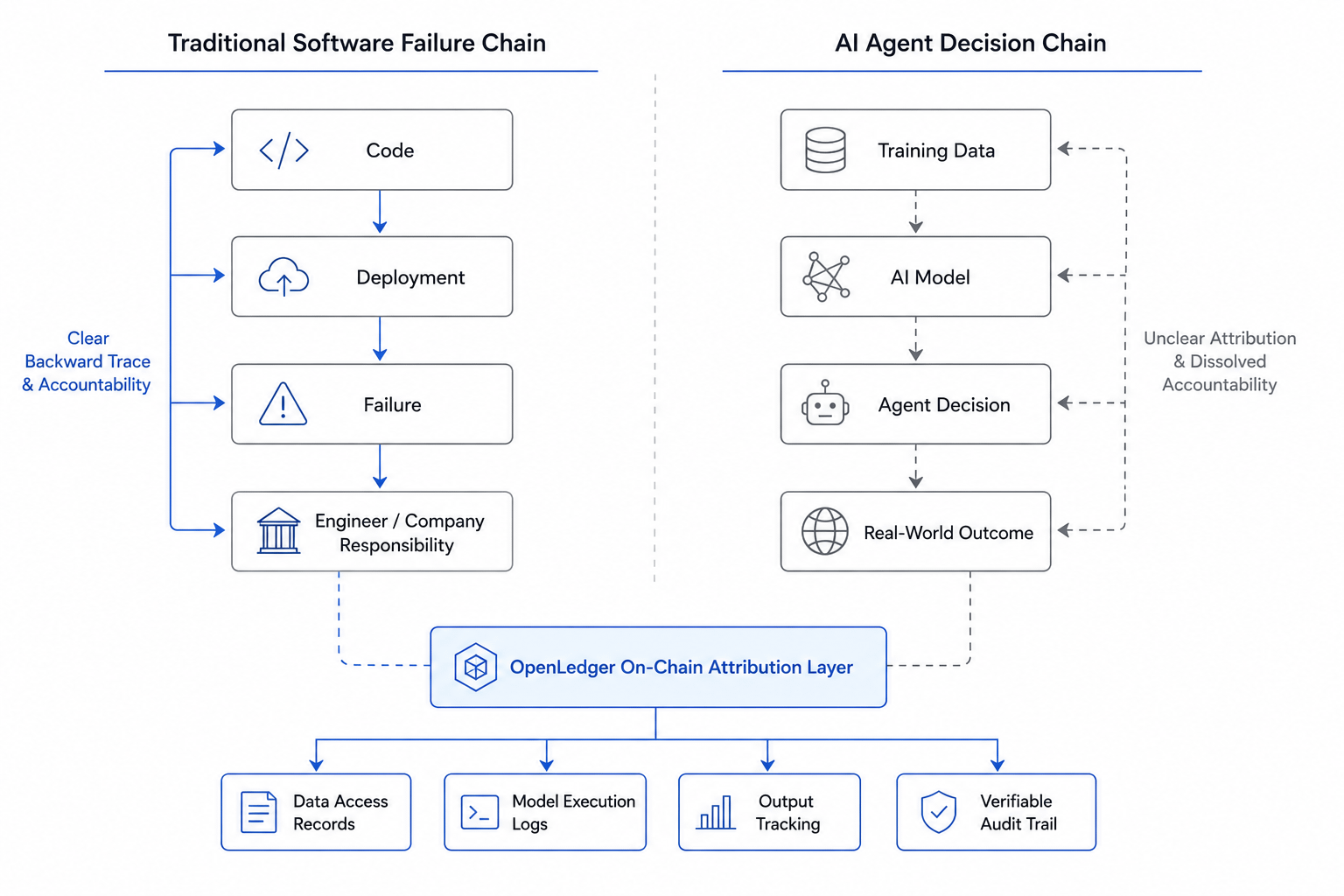
Em software tradicional, quando algo quebra, há uma cadeia que você pode seguir. Código rodou. Algo falhou. O engenheiro escreveu o código. A empresa o implantou. A cadeia é bagunçada às vezes, mas existe. Você pode segui-la para trás da falha até a causa.
Agentes de IA quebram essa cadeia de uma maneira que é difícil de consertar depois do fato. O agente tomou uma decisão. Essa decisão veio de um modelo. Esse modelo foi treinado com dados de algum lugar. O raciocínio que levou desses dados até essa decisão se dissolveu em um processo que ninguém pode reconstruir completamente. Não há uma cadeia limpa para seguir para trás.
E é aqui que a OpenLedger começa a parecer diferente para mim da maioria dos projetos de IA que eu olhei.
Não porque eles resolveram esse problema. Honestamente, eu não acho que ninguém o resolveu ainda.
Mas porque a infraestrutura de execução on-chain foi pelo menos projetada com esse problema em mente desde o começo. Cada passo que o OctoClaw dá gera um registro. Quais dados foram acessados. Qual modelo processou. Qual foi a saída. Essa cadeia não se dissolve como acontece quando agentes operam off-chain.
Eu acho isso genuinamente interessante..... mas também não tenho certeza de quão importante isso realmente é na prática ainda.
Porque um registro existir e um registro ser útil para responsabilidade são duas coisas diferentes. Reguladores precisam confiar no registro. Os tribunais precisam aceitá-lo como evidência. As empresas precisam acreditar que é completo o suficiente para satisfazer seus requisitos de conformidade. Nada disso acontece apenas porque a infraestrutura é tecnicamente capaz de produzir o registro.
Isso acontece quando instituições suficientes decidem que a atribuição on-chain é o padrão que querem exigir dos sistemas de IA.
E essa decisão ainda não foi tomada.
Então eu me encontro em um lugar desconfortável com a OpenLedger.
O problema que eles estão resolvendo é real. A lacuna de responsabilidade nos sistemas de agentes de IA é real e está se tornando mais séria à medida que os agentes assumem trabalhos mais significativos. A abordagem de infraestrutura faz sentido para mim tecnicamente. A direção parece certa.
Mas direção e chegada não são a mesma coisa. E no cripto, especialmente, a distância entre uma boa direção arquitetônica e a adoção institucional real é geralmente mais longa e difícil do que o preço do token em qualquer momento reflete.
Não estou descartando a OpenLedger. Também não estou convencido ainda.
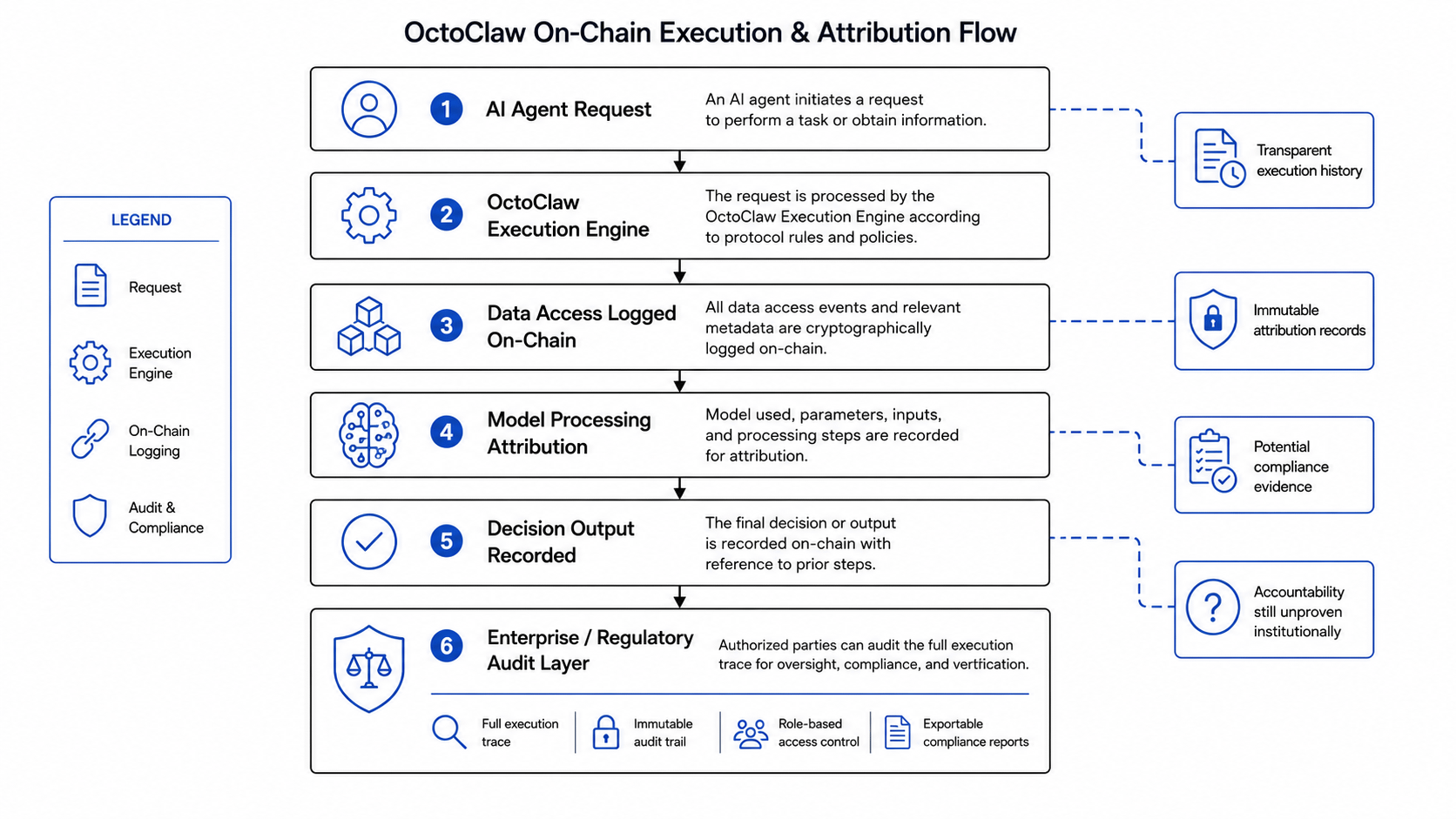
O que estou fazendo é observar se a manutenção do registro realmente é utilizada. Se as empresas que implantam agentes através dessa infraestrutura apontam para o registro on-chain quando algo dá errado e dizem — aqui, é assim que sabemos o que aconteceu. Se os reguladores começam a tratar a execução atribuída on-chain como evidência significativa ao invés de novidade técnica.
Essa mudança de comportamento — instituições realmente dependendo do registro ao invés de apenas saber que ele existe — é o sinal que estou esperando.
E eu não acho que já chegamos lá. Mas também não acho que esteja tão longe quanto o preço atual sugere.