Most people evaluate AI services from the surface layer outward.
Did the response arrive quickly. Did the output sound convincing. Did the workflow complete without obvious failure. If all three happen, the infrastructure underneath usually disappears from the conversation completely.
But the more AI starts handling economic decisions, automated execution, and on-chain activity, the less convincing that surface-level evaluation feels on its own.
Because a polished output is not necessarily evidence that the underlying process was accountable.
That’s why OpenLedger’s collaboration with DGrid caught my attention differently than most AI infrastructure announcements.
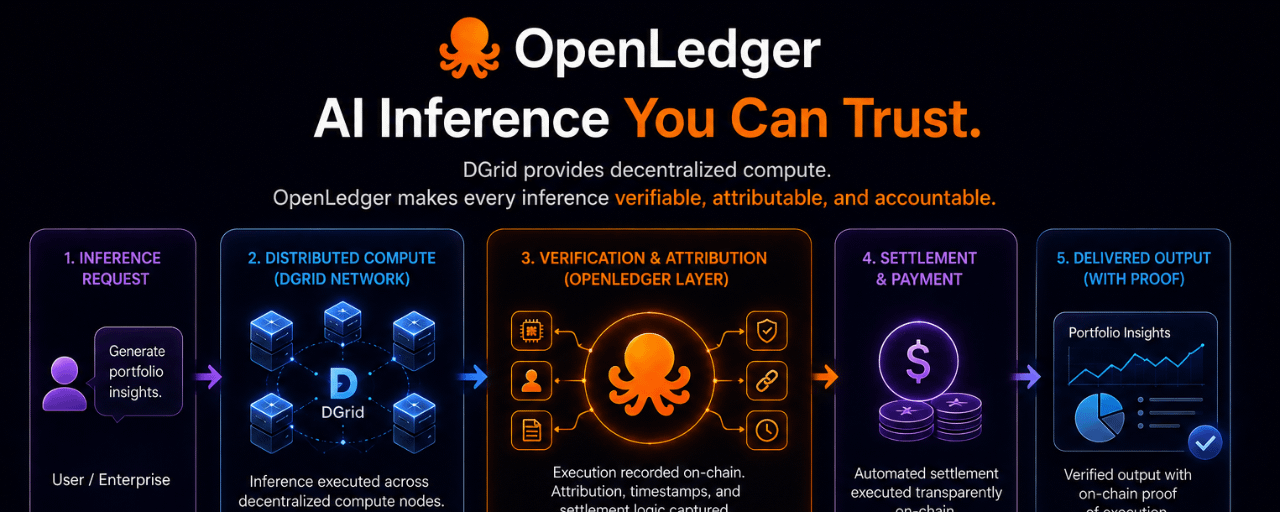
DGrid distributes AI inference workloads across a decentralized compute network. On paper, that already sounds useful. Instead of depending on a single centralized provider, inference work gets distributed across multiple compute participants.
But honestly, decentralization alone does not solve much if the buyer still cannot meaningfully verify what happened after the result comes back.
A distributed black box is still a black box.
The interesting part is where OpenLedger enters the flow.
The network is positioning itself as the coordination and attribution layer sitting around the inference process itself. Execution records, settlement logic, and attribution are intended to remain visible on-chain alongside the inference request instead of being separated into invisible backend accounting systems no normal user can inspect.
That changes the structure of trust completely.
Normally an enterprise purchasing AI inference receives two things separately: the output itself and a bill proving computation happened somewhere. Everything between those two points usually requires trust in whichever provider operated the infrastructure.
OpenLedger seems to be pushing toward a different model where the inference event, settlement path, and execution record stay connected inside the same verifiable environment.
And honestly, I think that matters much more for high-stakes AI systems than most people realize yet.
If AI starts participating in financial workflows, legal systems, autonomous agents, or healthcare coordination, then the output alone stops being enough. The buyer eventually needs to understand whether the process behind that output was reliable, attributable, and economically accountable.
Not because every user will manually audit blockchain records themselves.
Most won’t.
But because infrastructure that preserves those records creates the possibility of accountability when something goes wrong later.
That distinction feels important.
A lot of AI narratives talk about transparency very loosely. OpenLedger’s approach feels narrower and more operational than that. The system is not trying to make AI magically understandable at every level. It is trying to make the execution trail around AI activity remain legible enough that buyers are not forced to trust invisible coordination between disconnected systems.
That is a much more realistic infrastructure problem to solve.
And honestly, probably a more commercially valuable one too.
The harder challenge from here is usability. On-chain execution records only matter if enterprises and developers can actually interpret them without needing a specialized infrastructure team every time a decision has to be reviewed.
If accountability exists technically but remains inaccessible operationally, then most buyers will continue relying on trust anyway.
Still, the direction OpenLedger is moving toward feels important because it treats inference not as an isolated output but as a process that should remain economically and operationally traceable from request to settlement.
That is a very different philosophy from “just trust the AI answer because it sounds correct.”
And the larger AI systems become, the more I think buyers will eventually care about the process almost as much as the result itself.