
OpenLedger was one of those projects I had to sit with for a while before it started making sense to me.
At first, I saw the usual phrase attached to it: AI Blockchain. That alone did not tell me much. In fact, it made me a little cautious because almost every project touching AI and crypto now uses the same kind of language. Data, models, agents, ownership, monetization — all of it sounds familiar after a while.
So I tried not to judge OpenLedger from the tagline. I went through the project more slowly, looking at what it is actually building, how the pieces connect, and why a blockchain is involved in the first place.
The simplest way I can explain OpenLedger is this: it is trying to create a system where the data behind AI models does not disappear. When people contribute useful data, when builders fine-tune models, when agents use those models, OpenLedger wants that activity to be traceable. More importantly, it wants contributors to have a path to earn from the value their data helps create.
That is what made the project interesting to me.
A lot of AI today feels one-sided. Models are trained on huge amounts of information, but the people who created or organized that information usually do not remain part of the value chain. Their work gets absorbed, the model becomes useful, and the reward goes somewhere else. OpenLedger is trying to change that structure by making data contribution, model training, usage, and rewards part of the same system.
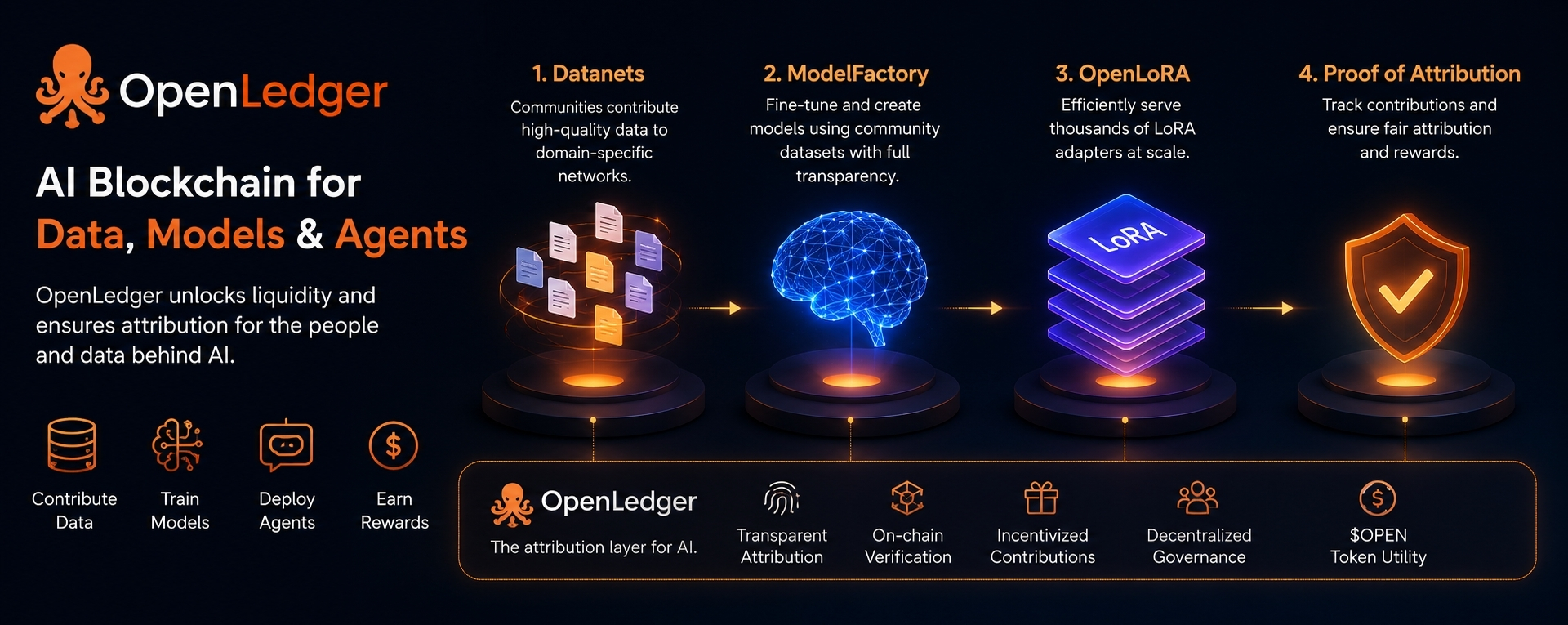
The first piece that helped me understand this was Datanets.
Datanets are basically focused data networks. Instead of collecting random data in one big pool, OpenLedger organizes data around specific domains or use cases. A legal Datanet would be different from a medical Datanet. A cybersecurity Datanet would need different standards from an education Datanet. That separation matters because specialized AI needs specialized data.
This part made sense to me because not every useful AI model has to be massive or general-purpose. In many cases, a smaller model trained on cleaner, more focused data can be more valuable than a larger model that only understands a topic at a surface level. A law-focused model needs legal context. A finance-focused model needs structured financial knowledge. A technical support model needs product-specific documentation.
OpenLedger seems to be built around that idea.
People can contribute data to these Datanets, and that data can later be used for fine-tuning models or supporting AI applications. But the important part is not just the upload. The important part is that the contribution is recorded and can be connected to later usage.
That is where Proof of Attribution comes in.
Proof of Attribution is probably the most important part of OpenLedger, and also the part I would watch most carefully. The idea is to track which data, model, adapter, or contributor influenced an AI output. If a model becomes useful because of certain data, the system should be able to recognize that contribution and reward it.
I like the idea because it deals with a real problem. AI models do not appear from nowhere. They are shaped by data, examples, feedback, expert knowledge, and human work. But once all of that is inside a model, it becomes difficult to see who helped create the value.
OpenLedger is trying to make that trail visible.
At the same time, I do not think this is easy. Attribution in AI is messy. A model does not always use one clean source for one clean answer. During training, data influences weights in complex ways. During inference, an output can be shaped by the base model, a fine-tuned adapter, retrieved documents, prompts, and other hidden factors. So the challenge is not only building an attribution system. The challenge is making people trust it.
If Proof of Attribution works well enough, OpenLedger has a real foundation. Contributors can feel that their data is not just being taken and forgotten. Developers can build with a clearer record of what their models use. Users can get more transparency around where outputs come from.
If it does not work well, the reward system becomes harder to defend. People may question the scores, the payouts, or the way influence is measured. That is why I see attribution as the heart of the project. Everything else depends on it.
Another part I explored was ModelFactory.
ModelFactory is OpenLedger’s fine-tuning layer. Instead of forcing users to handle the entire training process manually, it gives them a more accessible way to build specialized models from approved datasets. Users can choose a model, select data, adjust training settings, and create a fine-tuned version.
This is important because fine-tuning can be difficult for people who are not deeply technical. Data preparation, model selection, training parameters, evaluation, and deployment can become overwhelming very quickly. ModelFactory tries to make that process easier.
But I also see a limitation here. A simple interface does not automatically create a good model. If the dataset is weak, the result will be weak. If the use case is unclear, fine-tuning may not help much. If evaluation is poor, a model can look useful in a demo and fail in real use.
So I see ModelFactory as useful infrastructure, not a guarantee. It lowers the barrier, but the quality still depends on the data, the training choices, and the people building with it.
The more technical part of OpenLedger is OpenLoRA, and I found that more interesting than I expected.
LoRA adapters are lightweight fine-tuned layers that can change how a base model behaves without retraining or deploying a whole new model. This is useful because OpenLedger’s world depends on many specialized models existing at the same time. If every specialized model needs its own expensive full deployment, the system becomes difficult to scale.
OpenLoRA tries to solve that by serving many LoRA adapters more efficiently. Instead of loading a separate full model for every use case, it can use a shared base model and dynamically load the right adapter when needed.
That may sound like a background infrastructure detail, but it matters. If specialized AI is going to become common, it has to be affordable to run. A legal adapter, a support adapter, a cybersecurity adapter, and an education adapter should not each require heavy standalone infrastructure.
OpenLoRA also connects back to attribution. When a specific adapter is used, that usage can be recorded. If that adapter came from a certain dataset or contributor group, the system can connect usage back to the source.
That is when OpenLedger’s design started to feel more complete to me. Data enters through Datanets. Models are trained through ModelFactory. Adapters are served through OpenLoRA. Usage is tracked. Attribution connects usage back to contributors. Rewards can then move through the system.
The blockchain part fits mainly as the record and settlement layer.
I do not think the AI model itself needs to run on-chain. That would not make sense. Training and inference are heavy processes and are better handled off-chain. But the chain can be useful for recording ownership, permissions, model registrations, dataset activity, usage history, and reward distribution.
A centralized company could build a similar system privately, but then contributors would have to trust the company’s internal accounting. OpenLedger is trying to make at least part of that accounting more open and verifiable.
That is a reasonable use of blockchain to me. Not blockchain replacing AI infrastructure, but blockchain keeping track of the economic trail around AI.
The OPEN token is part of that economic layer. It is used for payments, gas, access, staking, governance, and contributor rewards. In theory, this gives the network a way to coordinate activity between data contributors, model builders, and users.
But token incentives are always a double-edged sword.
They can help bring early users and contributors into a network. They can reward people before the ecosystem has mature demand. But they can also attract low-quality behavior. If people are contributing only to earn rewards, the system may get more data without getting better data.
That is one of my main concerns with OpenLedger. The project needs quality, not just activity. A Datanet filled with weak, duplicated, or irrelevant data is not valuable just because it is large. The reward system has to push people toward useful contributions, not just more uploads.
The strongest version of OpenLedger would be one where useful data leads to useful models, useful models get real usage, and contributors are rewarded because their work actually matters. The weaker version would be one where people farm incentives, dashboards show activity, but the models do not offer much beyond what existing AI tools already provide.
The difference between those two outcomes will come down to execution.
Where I think OpenLedger could be most useful is in specialized domains.
A legal research assistant is an easy example. Imagine a Datanet built around case law, contract clauses, legal explanations, and jurisdiction-specific material. A team could use that data to build a specialized assistant. If lawyers or researchers use the tool, the system could track which datasets or adapters helped produce the output and reward the contributors behind them.
Cybersecurity is another practical example. Security researchers produce valuable information all the time: threat reports, vulnerability notes, malware analysis, detection logic, and incident writeups. A focused cybersecurity Datanet could help organize that knowledge into something AI models can use. A specialized model could then help analysts understand alerts, investigate threats, or summarize attack patterns.
Education also fits naturally. Teachers and subject experts could contribute explanations, examples, and exercises for a specific topic. A model trained on that kind of data could become more useful for tutoring than a general model that gives broad answers.
Healthcare is possible too, but it is much more sensitive. Medical data has privacy, safety, and compliance concerns. OpenLedger’s attribution system could be useful there, but only if the validation and governance standards are very strong. In areas like medicine, bad data is not just inefficient. It can be dangerous.
That is why I think OpenLedger’s best early use cases may come from domains where specialized data is valuable but the risks are still manageable.
What I like most about OpenLedger is that it focuses on a real weakness in AI: the invisible contribution layer. AI systems are built from human knowledge, but that knowledge often becomes disconnected from the people who provided it. OpenLedger is trying to give that contribution a record and a reward path.
I also like that the project is not only one feature. It is not just a data marketplace, not just a model builder, and not just an inference layer. It is trying to connect the whole path from data to model to usage to reward.
That full loop is what makes the project worth paying attention to.
Still, I would not look at it without questions.
Can Proof of Attribution measure influence in a way people trust?
Can Datanets maintain quality as more users join?
Can OpenLedger stop low-effort farming?
Will developers choose this system over simpler AI tools?
Will users care enough about attribution to pay for it?
These questions matter because OpenLedger adds complexity. A developer can already build an AI product using existing model APIs, private datasets, and a vector database. OpenLedger has to prove that its attribution and reward layer is worth the extra structure.
After spending time with the project, my view is that OpenLedger is trying to build accountability into AI infrastructure. Not in a vague way, but through records, attribution, model usage, and economic rewards.
The idea is strong because the problem is real. AI needs data, but data contributors are often forgotten. Specialized models need better datasets, but those datasets are hard to build. Agents need trusted context, but context needs provenance. OpenLedger is trying to connect all of those pieces.
I do not see it as something that should be judged only by its tagline. “AI Blockchain” is too broad and does not explain much. The real story is underneath: Datanets for specialized data, ModelFactory for fine-tuning, OpenLoRA for serving adapters, Proof of Attribution for tracking influence, and OPEN for coordinating the economy.
That is the project’s actual thesis.
Whether it succeeds will depend on how well it handles the difficult parts: attribution, validation, incentives, and real adoption. But I can see why the project matters. It is not simply trying to put AI on-chain. It is trying to make the work behind AI easier to trace, easier to use, and easier to reward.