Tem uma espécie de fadiga que não vem de modelos fracos ou falta de dados, mas do fato de que um processo que deveria ser suave continua sendo quebrado em muitas partes pequenas. Li os materiais exatamente nesse estado de espírito, então parei na maneira como a Openledger aborda o ajuste fino como uma camada de infraestrutura que precisa ser comprimida, em vez de deixar existir como um processo pesado espalhado por muitas direções.
Quem já passou por um ciclo de ajuste fino vai entender que a parte mais cansativa raramente está no momento em que você pressiona o botão de executar. Está nas horas gastas limpando dados, corrigindo rótulos, removendo amostras ruins, e depois os dias extras comparando saídas e rastreando qual mudança realmente fez a diferença. Para ser honesto, o que desgasta muitas equipes gradualmente não são algumas horas de processamento, mas o número de vezes que elas têm que voltar ao mesmo lugar só para reconectar partes que deveriam ter se movido juntas desde o início, e a Openledger merece discussão porque parece reconhecer esse custo exato.
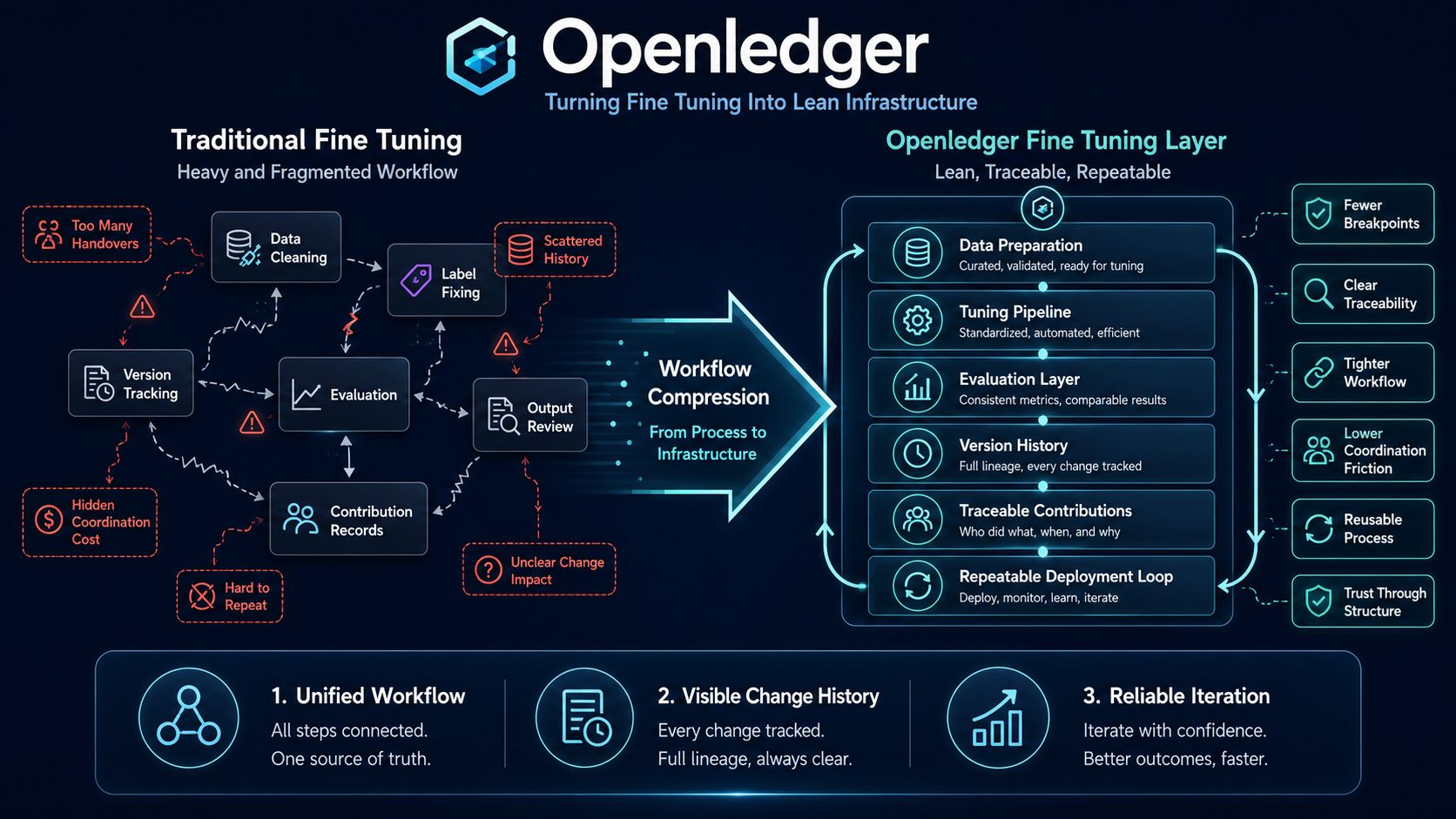
O que eu aprecio é que o projeto não trata o ajuste fino como um passo técnico sentado em algum lugar entre dados e saída. Quando o fluxo de trabalho é dividido em camadas separadas, os dados se movem em uma direção, a avaliação em outra, enquanto a história das mudanças é espalhada por vários lugares, os construtores mal podem saber em qual versão realmente estão e por que a qualidade mudou. Provavelmente é por isso que o Openledger escolhe puxar essas camadas mais próximas e reduzir os pontos de ruptura dentro do ciclo de ajuste.
Essa forma de ver as coisas é importante porque muda o papel do ajuste fino dentro de todo o sistema. Se continuar a ser tratado como um passo secundário, as pessoas vão continuar aceitando dados como matéria-prima anônima, critérios de avaliação como algo que pode ser ajustado sem peso, enquanto as saídas são lidas como se simplesmente aparecessem sozinhas. Eu acho que só quando o Openledger é colocado neste eixo é que fica claro que o projeto está tentando transformar o ajuste fino em uma capacidade que pode ser repetida, rastreada e acumulada.
Ironicamente, o mercado muitas vezes prefere falar sobre modelos mais fortes, maior velocidade e menor custo, enquanto evita a questão muito mais difícil, quem realmente fez um ciclo de ajuste confiável. Um conjunto de dados limpo não aparece por si só, e uma boa rodada de avaliação não se sustenta sozinha se a história das mudanças foi desbotada. Poucos esperariam que a maneira mais rápida de erodir a confiança vem de correções de rótulos, mudanças nos critérios de pontuação ou comparação de versões, e é precisamente nessas áreas que o Openledger mostra que entende onde os construtores estão ficando cansados.
Olhando um pouco mais fundo, fica claro que essa não é apenas uma história sobre tornar o fluxo de trabalho mais compacto por conta da apresentação. Quando dados, ajuste, avaliação e rastreamento de contribuições são puxados para a mesma lógica, as pessoas que preparam os dados, as pessoas que organizam a execução e as pessoas que leem os resultados não estão mais separadas por tantos pontos cegos. O valor que o Openledger sugere reside em sua capacidade de construir uma estrutura suficientemente apertada para que o próximo ciclo não precise começar com a confusão deixada pelo anterior.
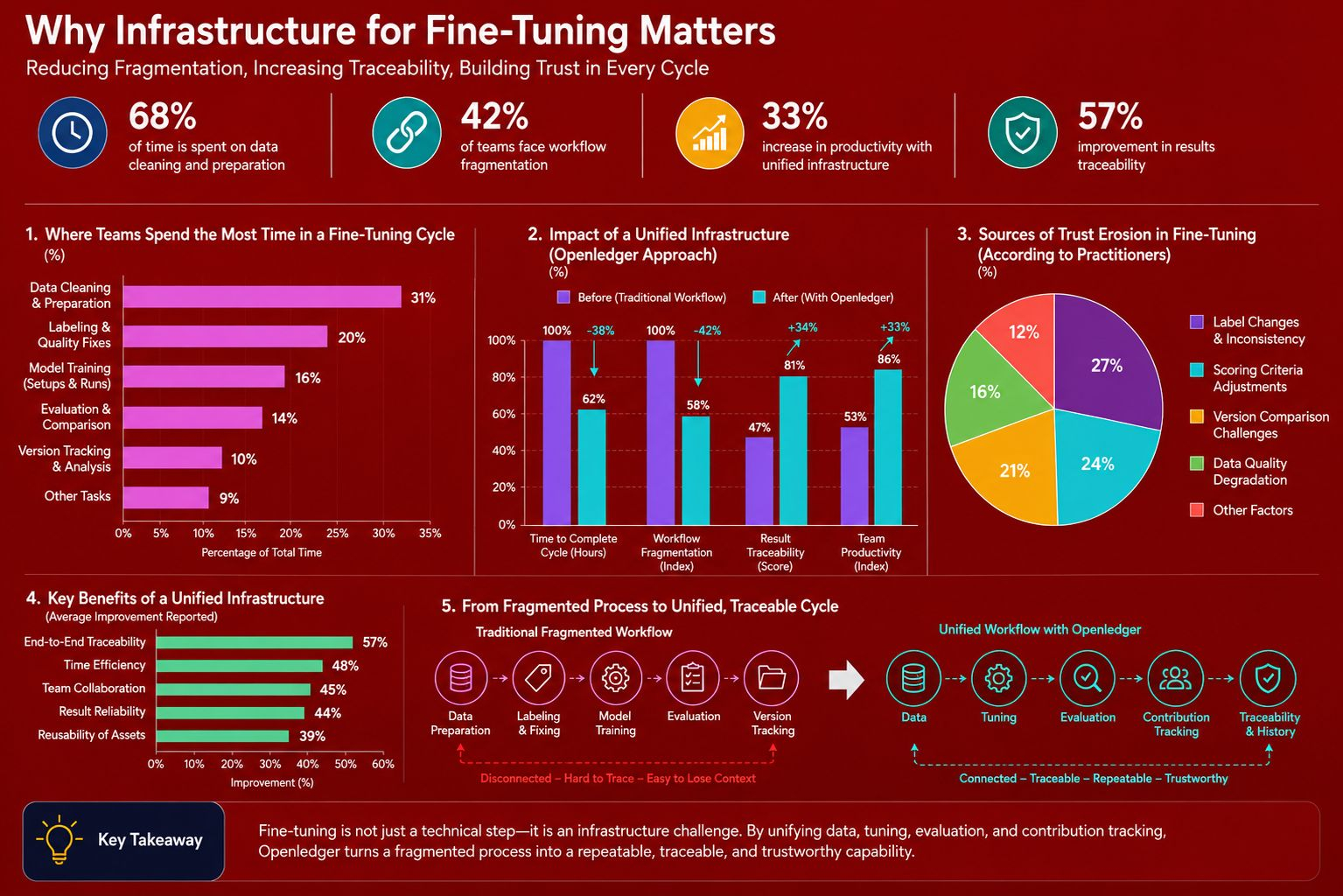
Mesmo assim, não acho que simplesmente juntar as camadas faça o problema desaparecer por si só. Quanto mais compacta uma camada de infraestrutura se torna, mais fácil é criar a ilusão de que a complexidade já foi resolvida, enquanto, na realidade, pode ter apenas sido empurrada para baixo e tornada mais difícil de ver. Ou talvez os usuários só vejam uma superfície mais lisa enquanto ainda não conseguem rastrear quais dados foram inseridos, quem mudou o que e por que os resultados mudaram. O Openledger só se torna verdadeiramente convincente quando essa compactação ainda vem com uma clara rastreabilidade reversa.
Depois de anos assistindo o mercado expandir enquanto se tornava solto na organização do trabalho real, acho que essa direção vale a pena seguir porque toca a base do problema. Em vez de permitir que o ajuste fino permaneça preso na forma de um processo pesado e fragmentado, o projeto está tentando trazê-lo de volta a uma camada base que os praticantes podem confiar e repetir. Se esse nível de rigor for preservado até o fim, o Openledger será digno de ser lembrado não porque produziu um resultado mais bonito, mas porque o caminho que criou esse resultado finalmente foi tornado mais enxuto, claro e mais confiável.
\u003cm-7/\u003e\u003ct-8/\u003e\u003cc-9/\u003e\u003cc-10/\u003e\u003cc-11/\u003e