
Estive pensando em algo que notei enquanto rolava pela atividade on-chain tarde da noite, o tipo de hábito que você desenvolve quando está tentando entender para onde a infraestrutura realmente está indo, em vez de apenas assistir os preços se moverem. Não estou negociando, não estou fazendo farming, apenas observando como as wallets interagem com sistemas que raramente se explicam claramente.
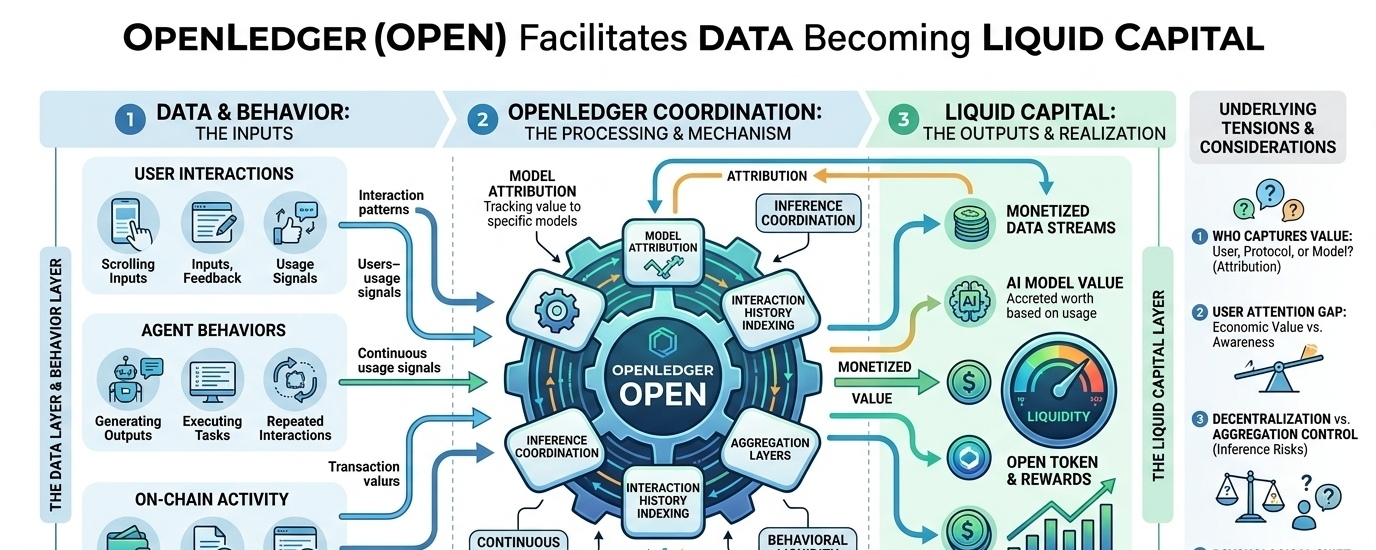
Está acontecendo uma mudança silenciosa onde os dados não são mais apenas um efeito colateral do uso de aplicativos cripto. Eles estão começando a se comportar mais como uma camada de ativo por conta própria. É aí que o OpenLedger (OPEN) começou a voltar aos meus pensamentos, não por causa do hype, mas pela forma como enquadra dados, modelos e agentes como algo que pode carregar liquidez.
Lembro quando dados em cripto significavam principalmente painéis, ferramentas de análise, ou talvez métricas DeFi se você estivesse imerso o suficiente. Agora a conversa parece mais pesada de uma maneira que é difícil de ignorar. Não se trata mais de observar dados, mas de quem possui o fluxo que os gera.
OpenLedger ocupa esse espaço desconfortável onde os dados não são apenas coletados, mas tratados como algo que pode ser monetizado através de sistemas de IA. A ideia de que modelos e agentes podem participar de estruturas de liquidez ainda me parece um pouco estranha. Não errada, apenas familiar o suficiente para que eu continue relendo.
Talvez eu esteja pensando demais, mas continuo perguntando quem realmente captura valor quando um agente de IA gera resultados por meio de interações repetidas. É o usuário que fornece a entrada, o protocolo que coordena ou o próprio modelo? A resposta ainda não parece clara, pelo menos não de forma limpa.
O que se destaca é como a liquidez, nesse enquadramento, começa a se estender além de tokens e pools para padrões de comportamento e interação. Isso soa abstrato no papel, mas começa a fazer sentido quando você pensa em como os sistemas de IA já aprendem continuamente a partir de sinais de uso.
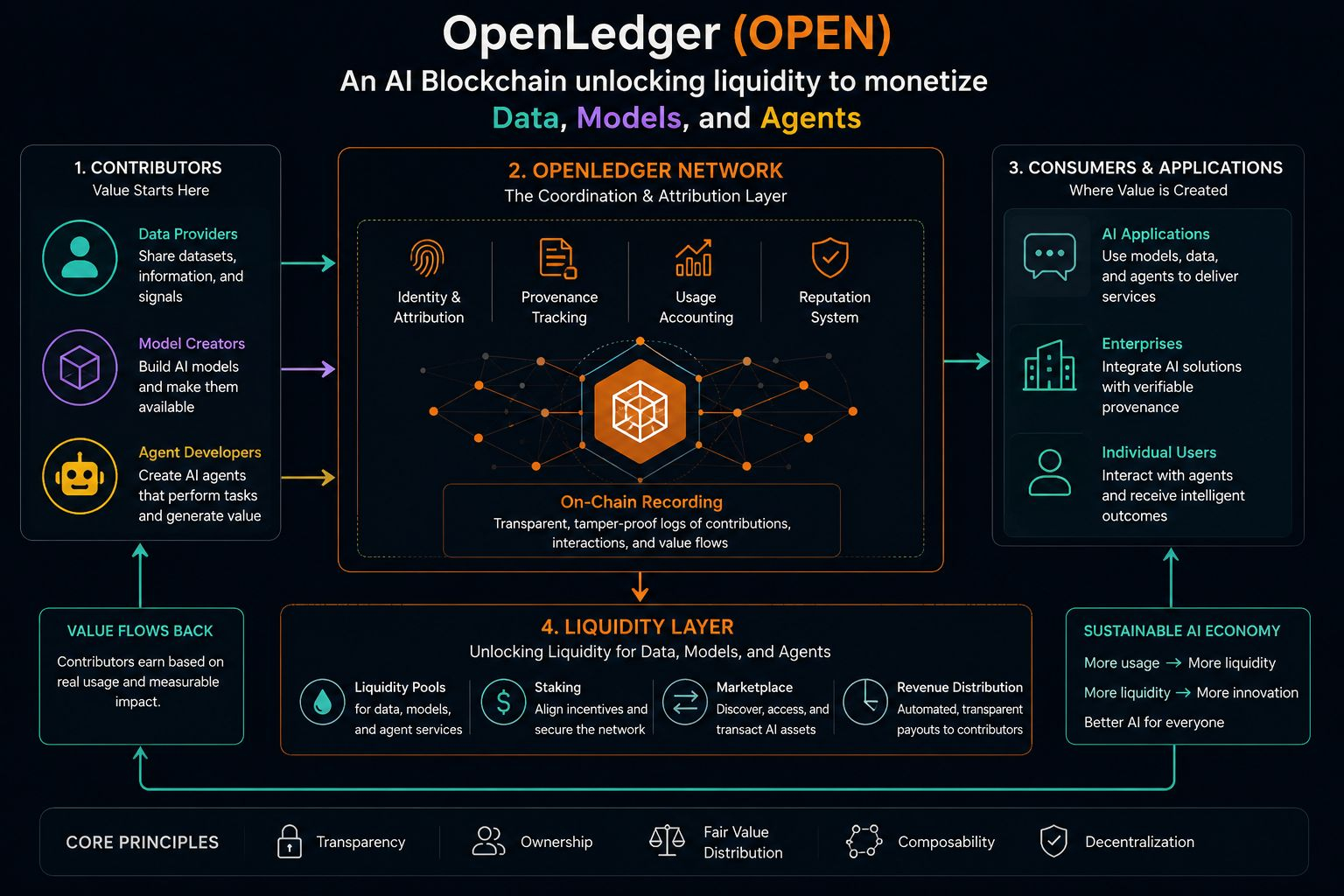
Vi versões anteriores dessa ideia em formas fragmentadas através de marketplaces de dados e camadas de incentivo, e geralmente elas enfrentam a mesma fricção. As pessoas querem a propriedade de seus dados, mas também querem sistemas que não as forcem a pensar sobre propriedade a cada passo. Essa tensão nunca realmente desaparece.
O OpenLedger parece estar tentando uma espécie de compressão dessa tensão, onde a contribuição de dados, interação de modelos e atribuição não são camadas totalmente separadas. Não estou totalmente convencido de como isso funciona de forma limpa no uso real. Parece uma daquelas ideias que só revela sua verdadeira forma quando a escala chega.
Ao mesmo tempo, fico me perguntando se os usuários algum dia vão se importar com a atribuição no nível do modelo. A maioria das pessoas não rastreia para onde seus dados vão hoje, mesmo quando claramente têm valor. Essa lacuna entre valor econômico e atenção do usuário pode ser mais difícil de preencher do que a tecnologia em si.
Agentes de IA sendo incorporados em ferramentas do dia a dia mudam essa superfície, no entanto. Uma vez que os sistemas começam a tomar decisões ou executar tarefas em nome dos usuários, o histórico de interação se torna economicamente relevante, independentemente de os usuários pensarem ativamente sobre isso.
Lembro de uma sensação semelhante durante os primeiros experimentos DeFi, onde incentivos estavam atrelados a comportamentos que não pareciam naturais no início. Levou tempo até que esses padrões se tornassem normais. Não tenho certeza se o OpenLedger é a mesma coisa, mas a mudança psicológica parece um pouco familiar.
Há também uma incerteza contínua sobre se esse modelo introduz novas formas de centralização sob a superfície. Mesmo que o sistema seja descentralizado estruturalmente, camadas de agregação ou pontos de controle de inferência ainda podem concentrar influência de maneiras que não são imediatamente visíveis.
O que torna mais difícil definir é se isso é uma evolução natural da infraestrutura cripto ou algo sendo moldado principalmente pela demanda de IA. Pode ser que ambos estejam se alimentando, mas não acho que a fronteira entre eles esteja totalmente definida ainda.
Não tenho uma conclusão limpa aqui. Continuo voltando à ideia de que os dados estão lentamente se comportando menos como informações estáticas e mais como algo mais próximo de capital, mas em uma forma que ainda não aprendemos a precificar, discutir ou mesmo perceber completamente em tempo real.
