What keeps irritating me on OpenLedger isn't bad data, exactly.
Would almost be easier if it were.
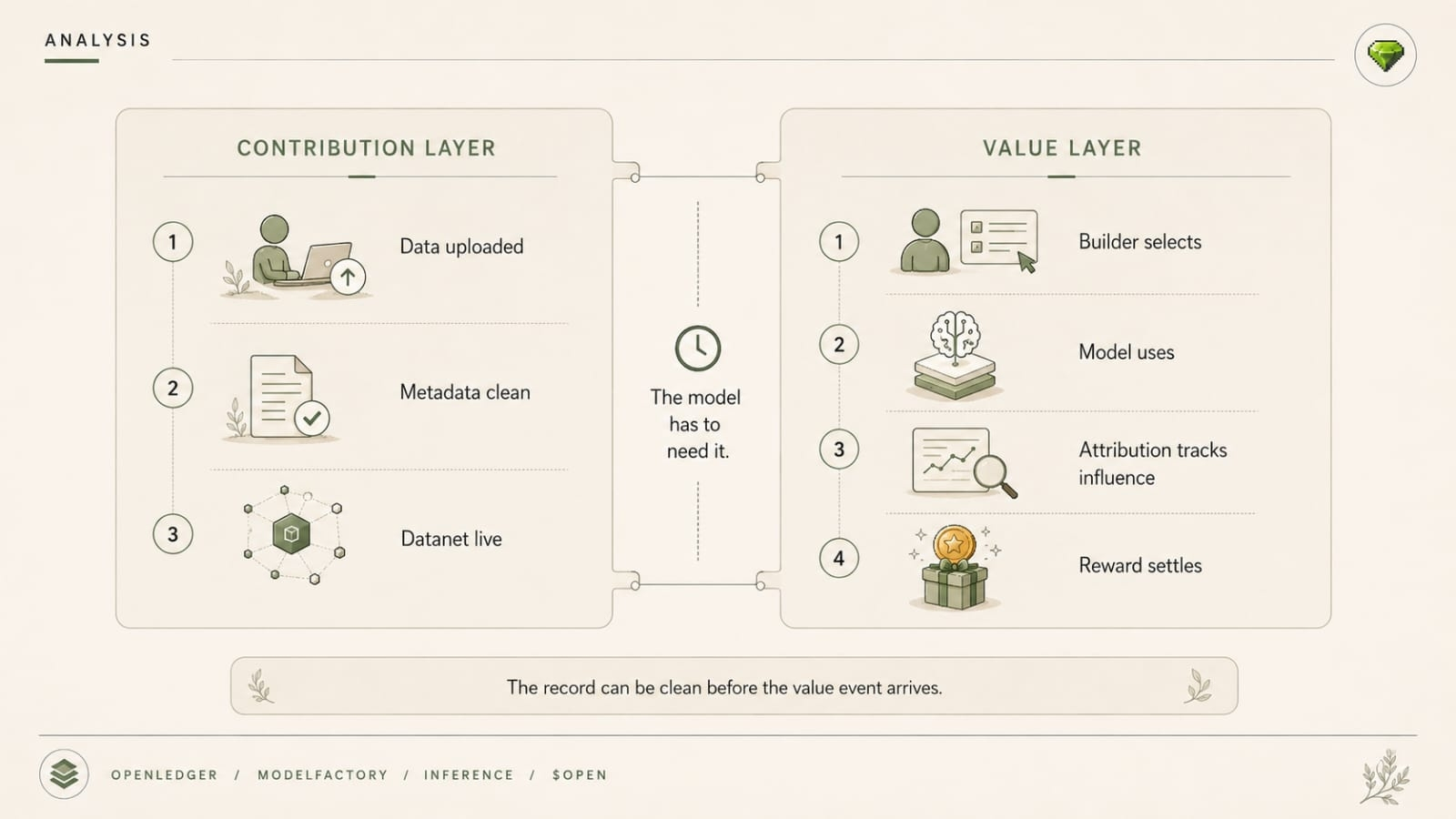
It's the moving-target version of good data. The respectable kind too. Which is worse. Approved contribution comes in. Row gets approved, file gets updated, Datanet rolls forward onchain. New version. New fee. Nice. Healthy little community data organism. Everybody claps because the thing is alive.
Fine.
Then some model path starts acting strange three weeks later and suddenly nobody wants a living organism anymore. They want one version. One surface. One clean slab of data they can point at and say: there. That one. That’s what trained this behavior. That’s what fed this output. That’s what we relied on.
And OpenLedger, by design, is not really built to give them that comfort cheaply.
Good.
Still annoying once somebody wants one clean version to blame.
That’s usually when the nice story dies.
Thats the part that keeps dragging me back.
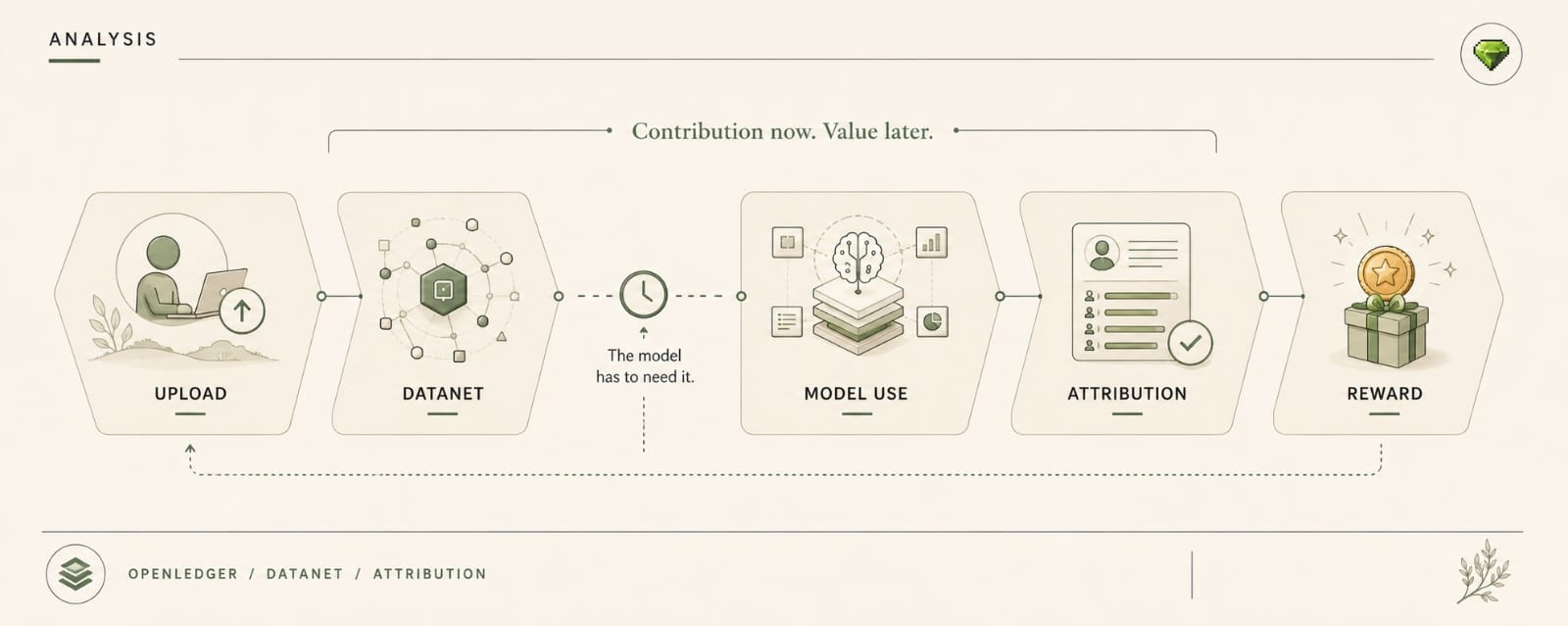
Because the soft story sounds great. Community Datanets keep improving. Public contributions get approved. The OpenLedger dataset becomes more useful over time. Better source layer. Better model inputs. Better downstream outputs. Good. Probably true. Still annoying once somebody needs reproducibility with teeth.
Say a desk is using a model that came out of an OpenLedger flow. Nothing exotic. A domain-specific Datanet feeding a model path that looked good enough to package, deploy, maybe route into a research workflow or risk note. Contributors keep adding rows. Some updates get approved. Datanet version rolls. Onchain history clean. Fee paid. Everybody gets the nice OpenLedger answer about transparent Datanet evolution instead of the usual private training repo nonsense.
Then the output quality bends.
Not explodes. Bends.
Worse kind.
One risk-summary path starts leaning weird. One retrieval path starts surfacing a thin pattern too often. One class of answer gets cleaner in tone and worse in judgment. You know. The kind of drift that makes the dashboard still look healthy while the operator starts narrowing their eyes at one row and then another and then the payout view and then the retrieval panel because something in the shape feels off.
That’s when the boring hostile question shows up.
Which Datanet version did this come from?
Not philosophically.
Actually.
Which one.
The training version? The live one? The one the retrieval path actually touched when it mattered?
Pick one. The room will try.
That’s where the cheerful community-update story starts coughing.
Because OpenLedger makes the dataset a live object. That’s the whole problem once somebody downstream wants one version that stays still. Not some hidden blob buried in a repo nobody outside the team sees. Datanet changes are visible. Approved public contributions roll the thing forward. File updates roll it forward. Row changes roll it forward. So lineage is not an afterthought here. It’s sitting right in the middle of the system, looking back at you.
Good.
Better than darkness.
Still not the same thing as one version a downstream team can freeze in a note.
The Datanet evolves in public. Downstream reliance still wants one version to blame in private.
And once the model behavior gets challenged on @OpenLedger , that nice distinction stops sounding academic real fast. Then it’s just a room full of people asking which version they’re actually dealing with.
I keep picturing some awful little review loop. The model output is bad enough to annoy people, not bad enough to trigger a dramatic incident memo. Which is exactly the range where the real pain lives. Somebody opens the trail. Datanet name there. Version history there. Approved contribution rows there. Maybe PoA still shows which Datanet rows and contribution paths mattered at inference. Maybe the retrieval log gives you a source path. Fine. Good. Better than darkness.
Still doesn't answer the thing the room actually wants.
What version are we relying on here?
The current one? Useless answer.
The one live when the model was trained? Better. Still maybe incomplete.
The one live when the bad output happened? Different question. So which one is the room actually blaming here?
The one that shaped the inference path most? Different again.
Nice. Now try putting that into one approval note.
If those aren’t the same, and they usually won’t be, then “the dataset” is already too blunt for what’s gone wrong.
That's where it gets stupid.
A community Datanet can keep improving while a downstream user still needs one stable version to defend, reproduce, or blame.
And the second those needs collide, the workflow gets ugly.
Because now a builder has to explain whether the model behavior came from the training version, the current version, or some ugly in-between state where the model weights are older but the retrieval path is newer and the output is carrying both without saying so cleanly. A risk operator wants to know whether the drift is model drift, Datanet evolution, retrieval drift, or just one thin contributor slice suddenly winning too often. Compliance wants a versioned surface. The system hands them a family tree.
Useful.
Still rude.
You can feel the room getting annoyed already.
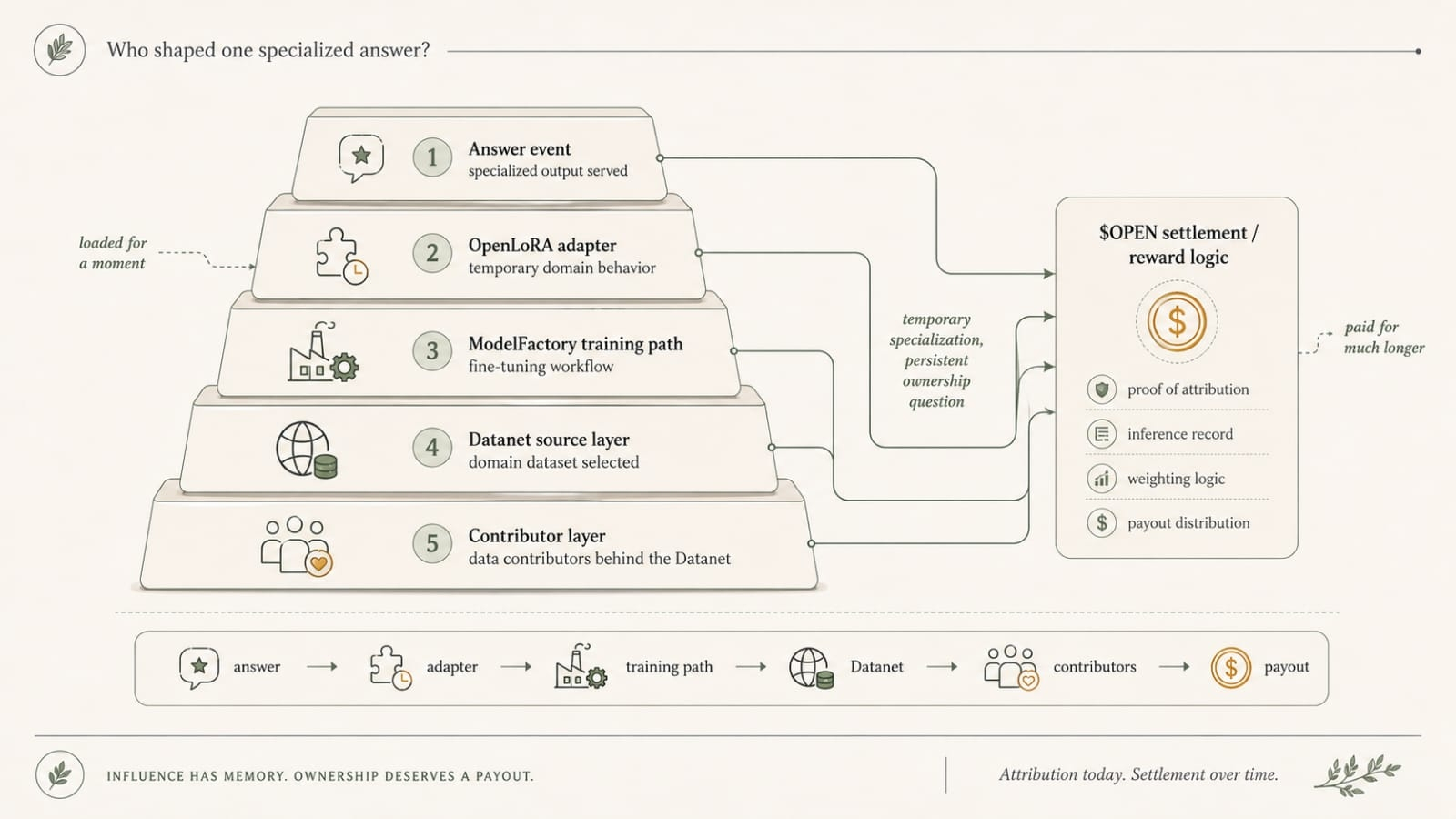
And yes, this is where OpenLedger gets more annoying than most AI projects. The dataset isn’t hidden. The changes aren’t hidden. Approval history isn’t hidden. That’s better infrastructure. Datanets make the source layer visible as a changing object. Proof of Attribution can tie parts of the output path back toward influence. ModelFactory means somebody may have packaged the model cleanly enough that real teams started using it before they fully priced what a living dataset does to reproducibility. OpenLoRA can make the inference surface more dynamic too, which is nice right up until someone wants to know whether the behavior came from the base model, the adapter path, the current Datanet branch, or the combination.
Good stack.
Still not a magic trick.
Still... a pain in the neck once somebody wants one version number.
Now the sentence “which version did this come from?” starts breaking apart in your hands.
Because half the time when people say “which version,” they don’t mean history. They mean which version can I hold still long enough to defend against.
Thats a much meaner question.
And live systems hate mean questions.
A community contributor hears “the Datanet keeps updating” and thinks healthy participation on OpenLedger. Fair enough. A downstream operator hears the same sentence after a bad model output and thinks great, now the evidence surface already moved while I’m still trying to work out what just happened. Same mechanism. Completely different emotional experience.
That gap matters once the bad answer is already in the note and nobody agrees which Datanet surface they’re even reviewing.
Same Datanet name. Different row state. That’s the part nobody wants to explain quickly.
More than the nice governance story around open contribution sometimes.
Because when something goes wrong downstream, nobody wants the proud abstract answer about living data. They want the ugly practical one. Which rows were present? Which approved contribution rows were already in? Which onchain version did the builder actually train against? Which version was active when the retrieval path got called? Did the inference rely on the newer Datanet surface while the model weights were still older? Did the output inherit both and then land in front of a user like one clean answer?
That's where the blame hunt gets expensive.
The version panel is open. The retrieval log is open. The note still wants one number.
Always does.
And that’s where OpenLedger starts feeling less like a “community AI data” story and more like infrastructure for versioned liability.
Not legal liability necessarily. Relax.
Operational liability, really. Reproducibility liability too, if you want the prettier term.
The kind where one team wants to replay behavior, another wants to freeze the evidence, and a third just wants one version number simple enough to stick in a note so everyone can get lunch.
Bad luck. OpenLedger is more honest than that.
And honesty here means friction. More tabs. More version checks. More people swearing under their breath.
Because once the Datanet is a live onchain object, versioning isn’t just a nice transparency feature anymore. It becomes the thing that keeps ruining lazy sentences like “the model was trained on this dataset.” Which dataset. Which version. Which branch. Which contribution state. Which retrieval surface. Which moment.
That’s what keeps dragging me back to it.
Not whether OpenLedger can make datasets visible.
It can.
The worse question is what happens when the Datanet keeps evolving in public, the model drifts downstream, and the room still needs one version it can hold still long enough to blame?...