
OpenLedger caught my attention because it is not trying to be just another chain with a broad promise attached to it. The project is focused on a very specific problem: how data, models, and agents can be connected to ownership, usage, attribution, and rewards in a more transparent way.
When I started looking into OpenLedger, the first thing I tried to understand was what the project is actually trying to fix. The problem is easy to describe but hard to solve. A lot of useful systems are built on data contributed by many different people, communities, and organizations. That data may come from experts, users, researchers, developers, or niche communities. But once it becomes part of a model or an application, the original contributors usually lose visibility. Their work may continue creating value, but they are no longer connected to that value.
OpenLedger is trying to change that.
The project is built around the idea that data should not just be consumed once and forgotten. If data helps improve a model, and that model later produces useful outputs, then there should be a way to trace that contribution and reward the people or groups behind it. This is where OpenLedger’s focus on attribution becomes important.
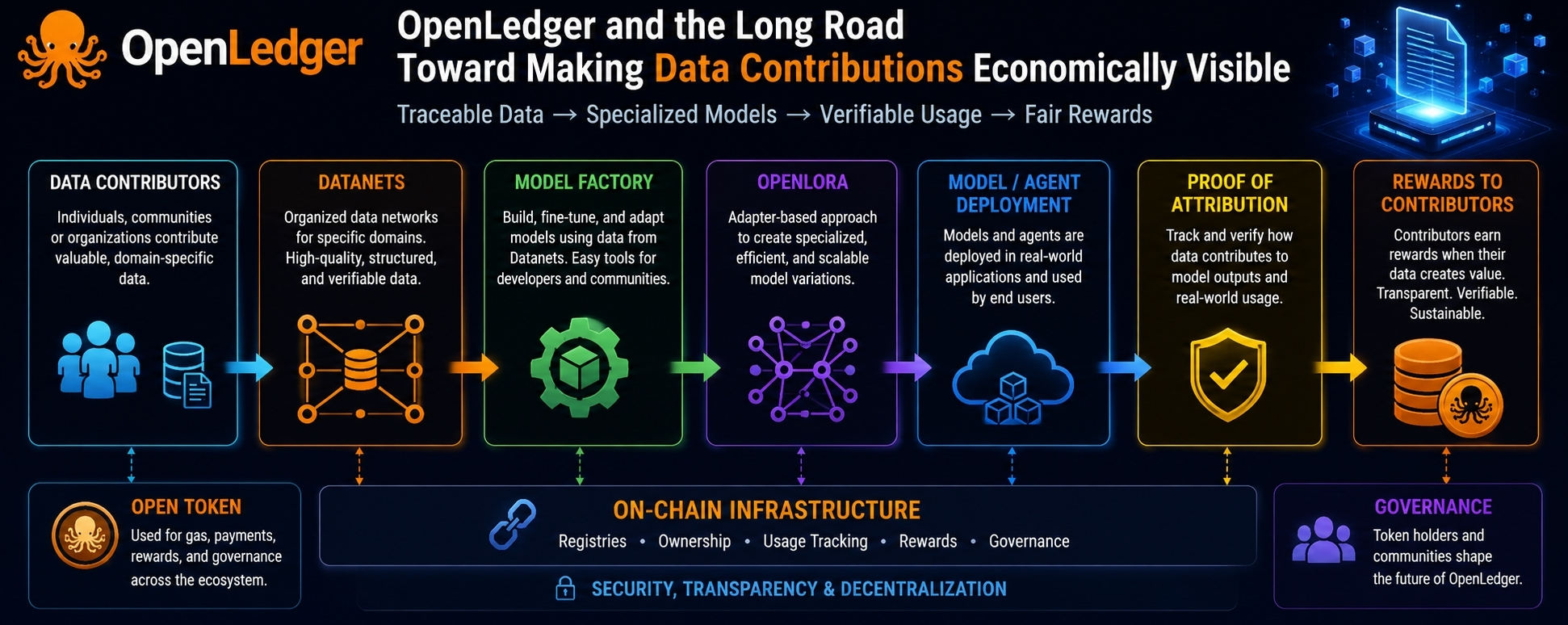
The way I understand OpenLedger is as an infrastructure layer for building, using, and monetizing specialized models through traceable data contribution. It brings together several pieces: Datanets, Model Factory, OpenLoRA, OpenLedger Studio, Proof of Attribution, on-chain registries, and the OPEN token. At first, these parts can look like separate features, but they make more sense when viewed as one workflow.
Datanets are where the data side begins. They are designed as organized data networks around specific subjects or use cases. Instead of random datasets floating around without context, Datanets aim to make data contribution more structured. A community or group can contribute domain-specific data, and that data can later be used to train, fine-tune, or improve models.
This part feels important because data quality matters more than people often admit. A model is only as useful as the information it learns from or retrieves. If the data is messy, duplicated, weak, or manipulated, the final output suffers. OpenLedger seems to understand that the value is not just in collecting data, but in organizing it in a way that can support useful model development.
Model Factory is the next major piece. This is where the project tries to make model creation more accessible. The idea is that users should be able to take useful data and turn it into specialized models or model improvements without needing to build everything from scratch. I see this as one of OpenLedger’s practical moves. If the system only works for highly technical teams, then the contributor economy remains limited. But if more people can create and adapt models using structured data, the network becomes more useful.
OpenLoRA also stood out to me because it deals with a real deployment problem. Specialized models sound good, but running many of them separately can become expensive and inefficient. OpenLoRA appears to focus on adapter-based deployment, which can make it easier to serve many specialized model variations without treating each one as a completely separate system. This fits OpenLedger’s broader direction because the project is not really about one large model. It is more about many focused models connected to specific data sources and contributors.
The most important part of OpenLedger, at least in my view, is Proof of Attribution. This is where the project becomes more than a data marketplace or model platform. Proof of Attribution is meant to help identify which data contributed to a model’s output or performance, so rewards can flow back to the right contributors.
This is also the hardest part.
Attribution sounds simple until you think about how models actually work. A single output may be influenced by training data, fine-tuning data, adapters, retrieval systems, user prompts, and other hidden interactions. It is not like a normal blockchain transaction where value moves clearly from one wallet to another. Model influence is more complicated. So OpenLedger’s biggest challenge is not just recording data on-chain. The real challenge is proving contribution in a way that feels fair, understandable, and difficult to manipulate.
That is why I see Proof of Attribution as the project’s core experiment. If it works well enough, OpenLedger has a meaningful foundation. If it feels unclear or unreliable, the reward system becomes much harder to trust.
The blockchain side makes sense when viewed through this attribution and reward problem. OpenLedger uses on-chain records to create a shared layer for ownership, usage, rewards, and governance. A normal centralized platform could track some of this internally, but then users would have to trust the platform completely. OpenLedger is trying to create a more open record where different participants can coordinate around data, models, and value flows.
That does not mean everything needs to happen on-chain. In fact, putting too much on-chain would likely be inefficient. The important question is what OpenLedger records publicly, what remains off-chain, and how users can verify the connection between the two. This is something I would keep watching closely because the strength of the system depends on those design choices.
OPEN, the project’s token, is used inside the network for gas, payments, rewards, and governance. This gives the token a clear role in the system, but it also creates trade-offs. Token incentives can help attract early contributors, but they can also attract people who are only there to farm rewards. Any system that pays people for contributing data has to deal with spam, copied content, low-quality submissions, and attempts to game the reward logic.
For OpenLedger to work, contribution needs to be tied to usefulness, not just activity. That is easy to say, but difficult to enforce. The project will need strong filtering, validation, and governance around Datanets if it wants to maintain quality.
The part I find most convincing about OpenLedger is its focus on specialized models. This feels more realistic than trying to build a general system for everything. Specialized domains have clearer needs and clearer standards. A security-focused model can be judged by whether it helps identify vulnerabilities. A finance-focused model can be judged by how well it handles market or on-chain data. A mapping model can be judged by accuracy and freshness. Narrower use cases make it easier to measure whether data is actually useful.
This is where Datanets could become valuable. If a community has deep knowledge in one area, OpenLedger gives that community a way to organize its data, build models around it, and potentially earn from future usage. That could matter in areas like smart contract security, financial research, environmental data, scientific datasets, legal knowledge, product information, or enterprise-specific workflows.
Still, OpenLedger has real limitations. The project depends heavily on attribution being credible. It also depends on data quality, user adoption, and actual demand for the models built on the network. A data economy cannot survive on contributors alone. There must be developers building useful applications and users willing to pay for the outputs.
Another open question is how OpenLedger handles overlapping data. If two people contribute similar information, who gets credit? If one dataset is derived from another, how is value split? If a model improves because of several sources at once, how does the system decide each contribution’s share? These are not minor details. They are central to whether contributors will trust the network.
My overall view is that OpenLedger is working on a real and difficult problem. The project is strongest when understood as an attribution and monetization layer for data-driven model development. Its focus on Datanets, specialized models, adapter-based deployment, and contributor rewards gives it a more concrete direction than many broad infrastructure projects.
But it still has to prove the hardest parts in practice. Proof of Attribution needs to be transparent enough for users to trust. Datanets need to produce high-quality data. Rewards need to avoid spam incentives. Developers need to build real applications. The token needs to support the system without becoming the only reason people participate.
What I like about OpenLedger is that it asks an important question: if data creates value inside models and agents, should the people behind that data remain connected to the upside?
That question is becoming more relevant as more digital systems depend on contributed knowledge. OpenLedger does not make the answer simple, but it is building directly around that problem. For me, that is what makes the project worth watching.