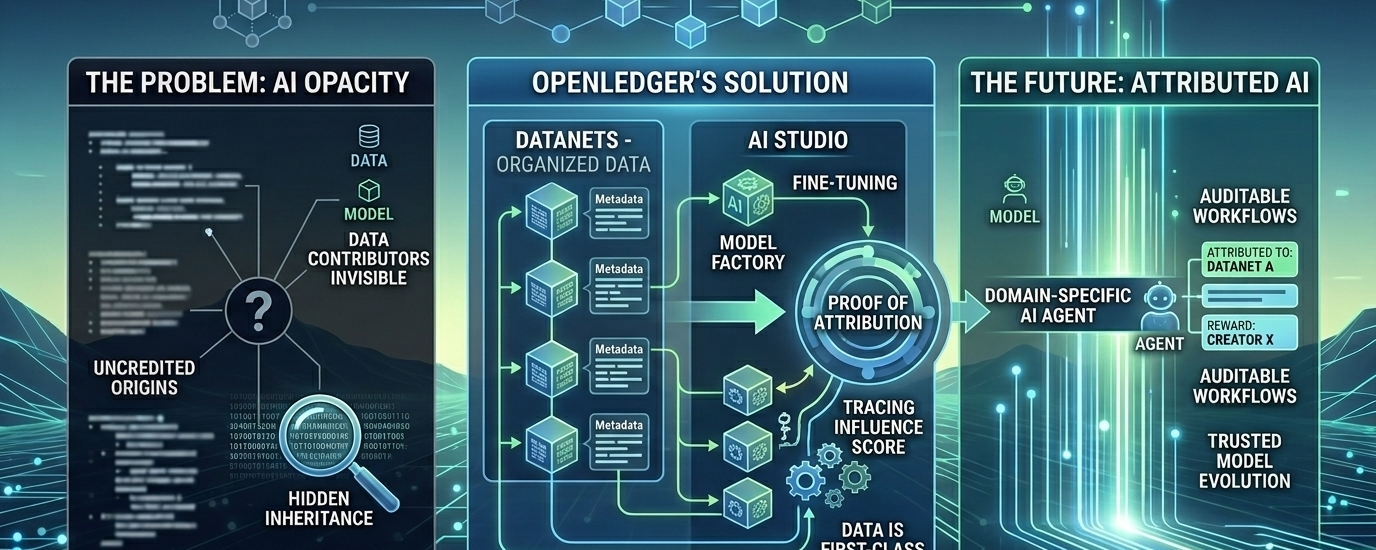
What keeps bothering me about crypto is how often it tries to solve ownership at the level of tokens while leaving the deeper problem untouched: who actually created the thing that was valuable in the first place. In AI, that question comes back with more force. A model may appear fluent and useful, but the data behind it is usually scattered, uncredited, or inaccessible. The result is a familiar kind of opacity. You can see the output, but not the lineage. You can admire the performance, but not inspect the inheritance. OpenLedger is interesting to me because it begins from that irritation and turns it into a protocol design problem rather than a marketing slogan. Its premise is simple enough: if data, models, and agents are becoming productive assets, then their contribution should be traceable, and their use should be compensable. OpenLedger presents itself as an AI blockchain built to do exactly that, with a focus on monetizing data, models, and agents rather than general-purpose blockchain activity
That framing matters because the problem did not begin with blockchains. It began with the structure of modern AI itself. Large models are trained on enormous, mixed-origin datasets, yet the contributors behind those datasets are usually invisible. OpenLedger’s own materials describe this as a gap in recognition and reward: contributors remain disconnected from the value their data helps generate, and high-quality domain data has weak incentives to appear in the open. That is the recurring failure I see in many earlier attempts to “open” AI. Some projects focused on openness of code, others on decentralized compute, and others on marketplace mechanics. But they rarely solved provenance in a way that was usable, enforceable, and economically legible at inference time. OpenLedger is trying to move the argument one layer deeper, from “open source” as a label to attribution as a system. Whether that is enough is a separate question, but it is at least a more precise one
The core mechanism is called Proof of Attribution, and this is where the project becomes more than a familiar AI-on-chain pitch. In the June 2025 paper, OpenLedger describes Proof of Attribution as the foundational mechanism for a system where data, models, and intelligent agents evolve onchain. The paper says attribution is computed differently depending on model size: influence-function approximations for smaller models, and suffix-array-based token attribution for larger language models. In both cases, the goal is to trace which parts of an output can be mapped back to specific training data, then use those influence scores to distribute rewards. Models also log training provenance, so the history of a model version is not merely implied but recorded. I find the ambition admirable, but I also hear the fragility in the wording. Attribution at scale is hard, and any system that claims to resolve it must survive both technical scrutiny and adversarial use. Still, the design is coherent: make data first-class, attach lineage to model behavior, and turn inference into a moment of accounting rather than a black box
The project’s second important idea is DataNets. OpenLedger describes these as collaborative spaces where contributors gather and curate specialized datasets, especially data meant for LLM-ready augmented intelligence. In the paper, each DataNet becomes a structured onchain primitive with metadata and timestamps, while in the product material they function as the source layer for model development. This is the part of the architecture that feels most grounded to me, because it recognizes a practical truth: model quality usually depends less on abstract “decentralization” than on the quality and specialization of the underlying corpus. General web-scale data is abundant; domain-specific, well-labeled, permissioned, and continuously updated data is scarce. DataNets are an attempt to organize that scarcity into an economic and social structure. The question, naturally, is whether communities will contribute enough useful data once the novelty fades. Coordination is expensive. Curation takes labor. And the promise of attribution alone may not overcome the practical burden of participation
OpenLedger’s product layer extends that same logic into model building. The company describes an AI Studio that includes Datanets, a no-code Model Factory, and OpenLoRA as a deployment engine. The blog claims OpenLoRA can reduce the cost of launching models dramatically, though I read such claims as directional rather than settled fact. The more important point is that OpenLedger is trying to unify three moments that are usually separated in AI stacks: data collection, model fine-tuning, and deployment. That is structurally sensible. It lowers the conceptual distance between the people who supply the data and the people who use the model. But the simplification has trade-offs. A no-code layer can broaden participation while also obscuring the technical choices that matter. A specialized deployment path can improve efficiency while narrowing flexibility. And an integrated stack can be elegant in a demo while still demanding serious engineering discipline in production
I also notice that OpenLedger is careful to place itself in the current AI tooling conversation rather than pretending blockchains alone are enough. Its MCP material argues that AI systems struggle to connect with real-time data sources such as blockchains, APIs, and SaaS tools, and that the Model Context Protocol offers a standardized interface for doing so. In OpenLedger’s telling, this is useful because specialized agents need live context, not static training alone. That is a fair observation. AI systems become much more believable when they can reason over fresh state rather than frozen snapshots. But again, there is a difference between a protocol standard and a complete product. MCP can reduce integration chaos, yet it does not erase the governance questions around what data a model may see, who curates the tool endpoints, or how failures are audited. OpenLedger’s emphasis on secure, dynamic connections is sensible; the hard part is the operational discipline required to make those connections trustworthy over time
What I find most compelling, and most uncertain, is the project’s attempt to turn attribution into governance. OpenLedger’s own comparison with general blockchains says its system would track every contribution, reward data and model creators, and even tie governance to model quality and improvement rules. That is a striking ambition because it shifts power away from a simple validator-miner framing and toward a more content-aware economy. In principle, that could produce better incentives for domain experts, dataset curators, and builders who sit upstream of model utility. In practice, it raises difficult questions. Who decides that a dataset is good enough to enter a DataNet? Who arbitrates disputes over attribution when outputs are ambiguous? How resilient is the reward logic to manipulation, spam, or synthetic data contamination? A protocol can encode values, but it cannot magically eliminate politics. It only relocates the politics into code, committees, and dispute processes
The adoption challenge is easy to underestimate. OpenLedger is not asking users merely to run a new app; it is asking them to participate in a new relationship between data, identity, and value. That is a heavier lift. A contributor must believe that labeling, curating, or uploading data is worth the overhead. A builder must believe that the attribution layer is reliable enough to depend on. A developer must believe that the system is interoperable enough to avoid becoming a silo with different vocabulary. Even the official materials show a project still assembling its ecosystem through product pages, docs, staking, explorer links, OpenCircle, and mainnet-facing surfaces. That is normal for an emerging stack, but it also means the project is still proving whether its architecture can outgrow its own narrative. The gap between elegant design and durable network effects is often where crypto projects stall
I think the likely beneficiaries, if the model works, are not the broadest possible audience but a narrower set of participants: domain experts who can contribute specialized datasets, builders who need auditable AI workflows, and communities that want to keep a visible relationship to the models they help train. OpenLedger seems especially suited to niche, high-context environments such as onchain analytics, compliance tooling, research assistants, and other specialized agents where provenance matters as much as output quality. The people still left outside may be those who want AI to disappear into the background, who are unwilling to do the work of curation, or who cannot afford the friction of participating in an attribution-first system. There is also a subtler exclusion risk: if the protocol becomes too complex, then only technically sophisticated contributors will be able to capture the very credit the system is designed to distribute. That would be a disappointing but entirely plausible outcome
So I come away from OpenLedger neither persuaded by the grandest version of its promise nor dismissive of the experiment. I see a serious attempt to answer a real structural failure in AI: the missing chain of custody between data contribution and model output. I also see a system that may be technically elegant in parts and socially brittle in others. Attribution is not the same as justice, and visibility is not the same as alignment. Still, a project becomes more interesting when it resists the easy claim that decentralization is the answer to everything and instead asks a narrower question: can a network make data contributions legible enough to support trust, reward, and reuse? That is a meaningful question even if the answer remains incomplete. The unresolved part, to me, is whether OpenLedger can make attribution reliable enough that people trust it not because it is promised, but because it is proven
