I didn’t take it seriously at the beginning...
Not because @OpenLedger sounded empty. more because I’ve seen this industry turn too many real problems into clean infrastructure language. contribution, ownership, verification, coordination. all good words. all tired words too, once you’ve watched enough cycles bend under the same pressures.
Maybe that’s too harsh.
but crypto has made me slower to trust the first version of any system. the first version is always where the ideals are still visible. the second version is where incentives start whispering. the third version is where people stop asking who controls the boring parts.
and with AI-data, the boring parts are basically everything.
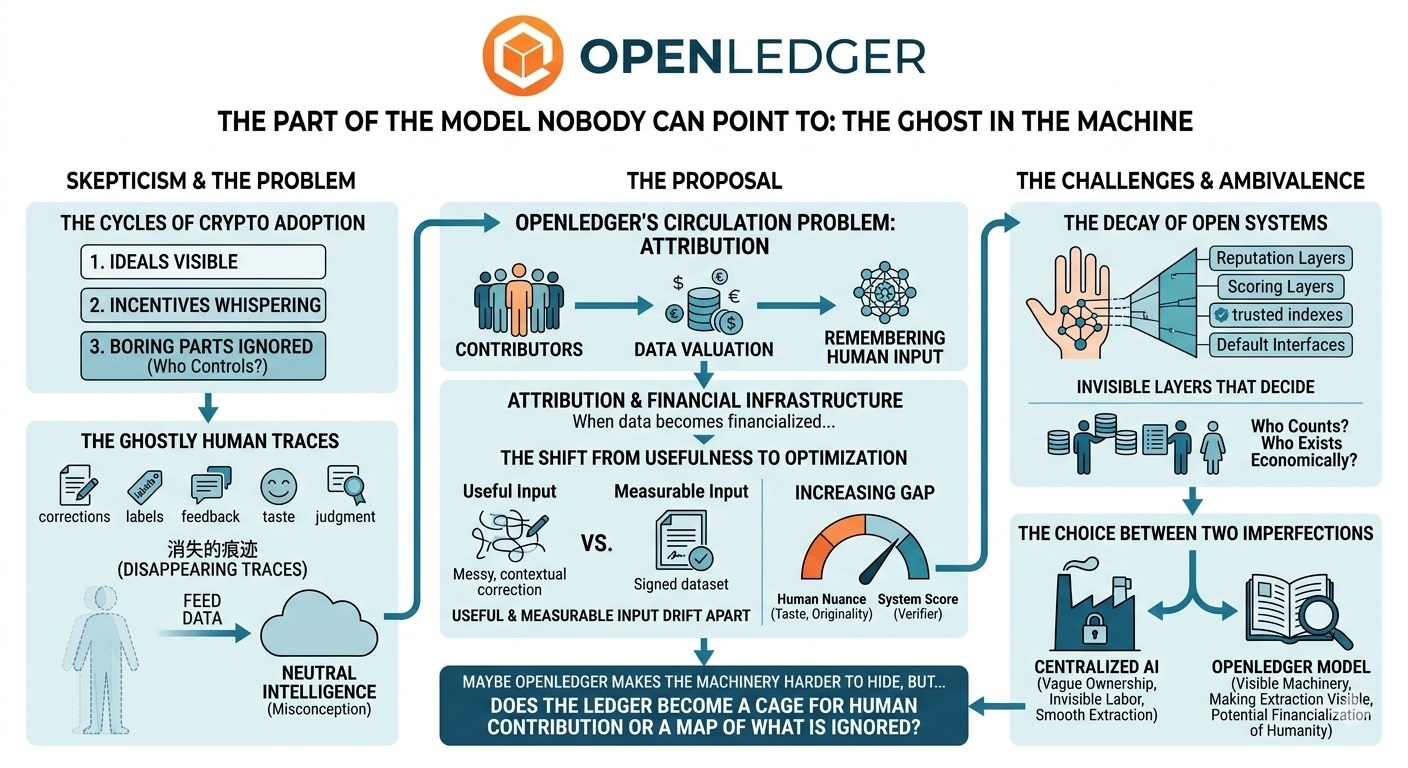
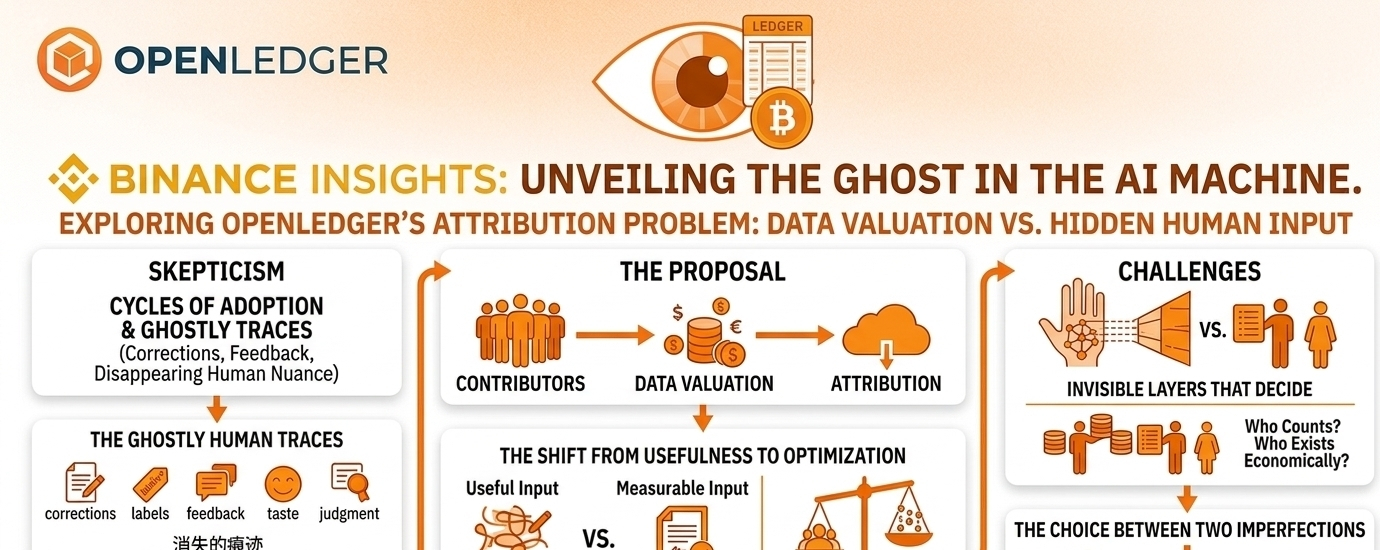
models are built from human traces that disappear almost immediately. corrections, labels, examples, feedback, preference signals, domain knowledge, small bits of judgment. all of it gets absorbed into the machine, and later the output gets described like it emerged from some neutral cloud of intelligence.
it didn’t.
I keep coming back to attribution.
there is something uncomfortable but necessary there. if people help shape models, maybe the system should remember them. if data carries value, maybe that value should not vanish into closed pipelines and return as someone else’s product. OpenLedger seems to circle that problem more directly than most AI-crypto narratives, which is probably why I can’t fully ignore it.
but attribution changes once it becomes financial infrastructure.
That’s where things start to feel uncomfortable.
because once data becomes financialized, people stop just contributing. they optimize. they learn what gets counted. they study the verifier, the scoring layer, the path of least resistance. useful input and measurable input begin to drift apart. slowly at first. then very quickly once rewards are large enough.
It works in theory. Most things do.
The problem isn’t really the technology… or not only the technology. it is the shape of human contribution itself. a transaction has edges. a signature is clean. but context is not clean. taste is not clean. usefulness can arrive late. originality can be collective. a messy correction can matter more than a polished dataset, but the polished dataset may look better to the system.
so who gets remembered?
the person who made the model better, or the person who fit the attribution logic best?
That part keeps bothering me more than it should.
and then there is the old open-system decay. nothing closes at once. it narrows. default interfaces. trusted indexes. operators. dashboards. reputation layers. quality scores. all the practical stuff people accept because raw openness is exhausting.
AI infrastructure feels especially vulnerable to that drift. attribution logic, filtering, model coordination, contribution scoring — these invisible layers decide what counts. and once they decide what counts, they decide who exists economically.
still, I can’t dismiss OpenLedger.
centralized AI has not earned that comfort either. closed datasets, vague ownership, invisible labor, extraction hidden under smooth products. that already feels broken, just easier to ignore.
maybe OpenLedger makes the machinery harder to hide.
maybe that matters.
or maybe when incentives get sharp enough, the system built to remember human contribution only remembers the parts that are easiest to price, and lets the rest slip quietly back into the model.