What keeps bothering me on OpenLedger isn't the answer quality by itself.
Would almost be simpler if it were.
Anyways...
It's the part where one answer lands, looks useful enough, and immediately turns into a tiny financial event nobody wants to describe that way because it sounds less magical and more annoying. Platform fee. Model fee. Datanet fee. Contribution fee hanging off attribution on OpenLedger. Nice. The chat response is barely warm and the accounting logic is already standing behind it with a clipboard.
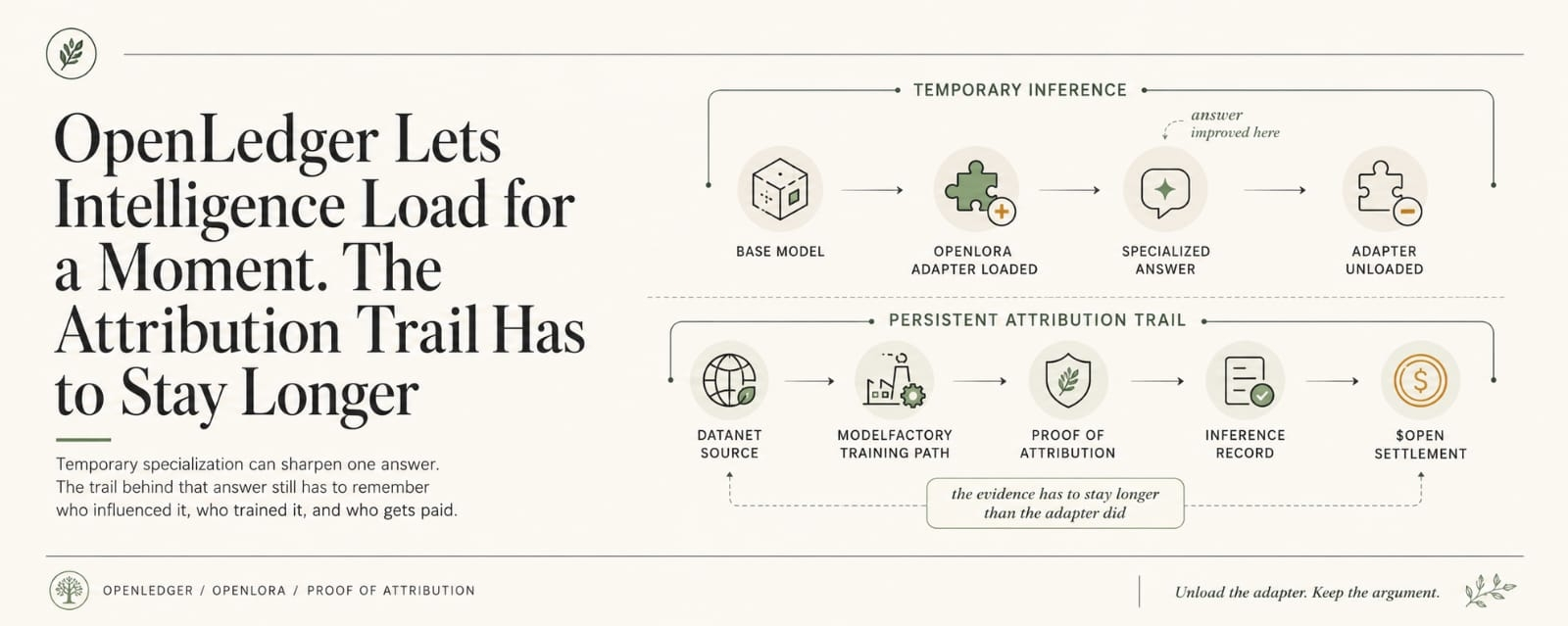
OpenChat up front. Fee stack underneath. Same answer, two jobs.
Thats the part that keeps dragging me back.
Because the clean version sounds elegant. OpenChat runs, the user gets a response, the system tracks who contributed what, value gets split, everybody gets paid in a way that’s supposed to match influence instead of just ownership theater. Good. Fair enough. Better than one platform swallowing the whole thing and calling everybody else “context.”
Still.
The second one answer also becomes a payout event, the whole argument changes shape.
Now “who influenced this response?” is not a research question. Not a nice provenance question. It’s a compensation fight waiting for good manners to fail.
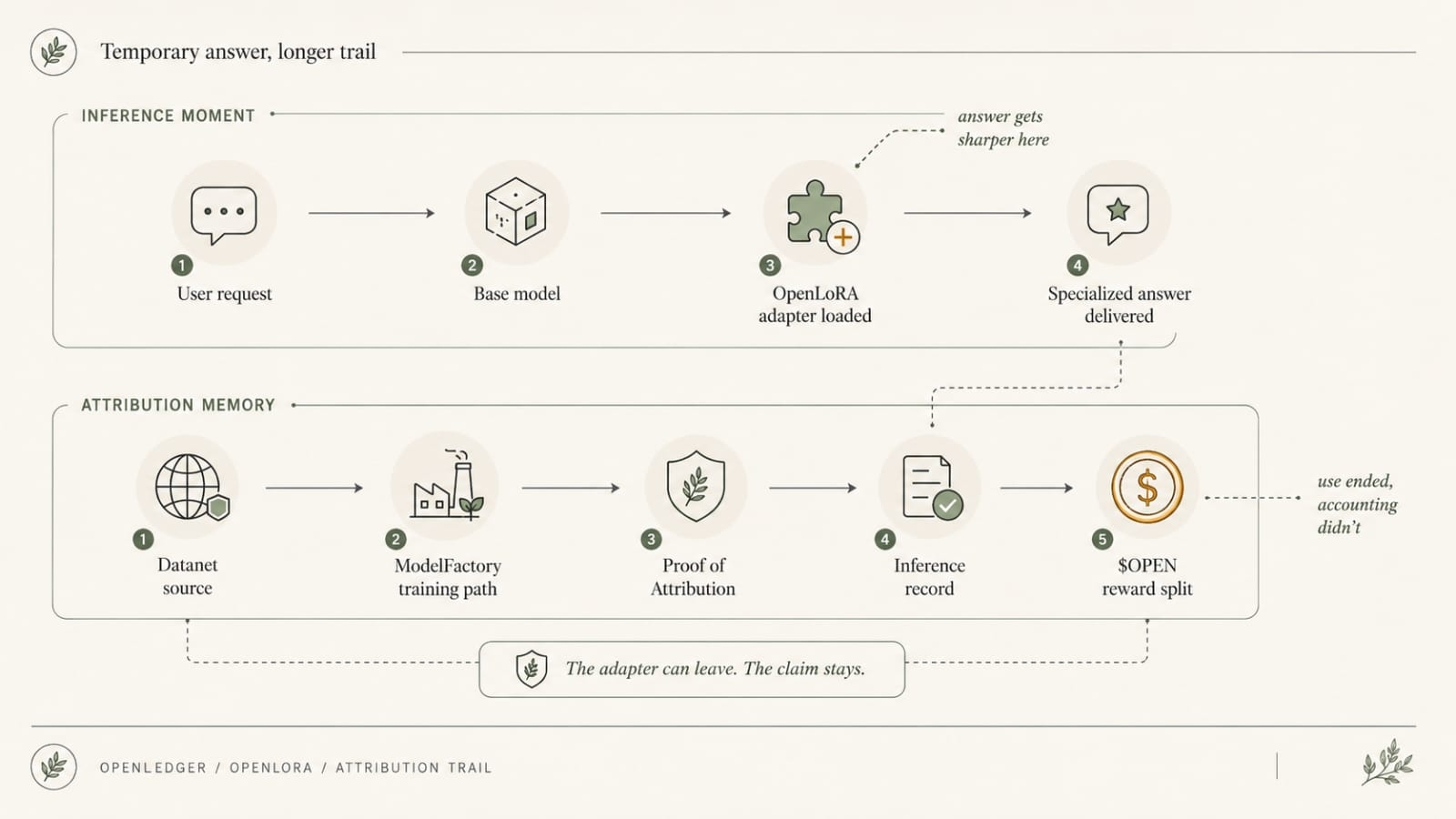
Say a team is using OpenLedger's OpenChat inside a real workflow. Research desk, maybe. Partner support, maybe. Doesn’t matter. Somewhere a user asks for a market note, or a risk summary, or some ugly synthesis that pulls from multiple Datanets, one packaged model surface, maybe an adapter path that nudges tone or domain handling just enough to matter. The answer comes back. Good enough to use. Good enough to circulate. Good enough to trigger fees and splits underneath it.
The fee row updates before anybody in the room has agreed what the answer was actually worth.
The row doesn’t argue. It just assigns weight. Datanet here. Model there. Contribution slice there. Nice little numbers. Now everyone gets to pretend the numbers didn’t start the fight.
That’s where it gets rude.
Because the answer doesn’t just need to be useful anymore. It needs to be allocatable.
Thats usually where I stop pretending this is just inference.
And those are not the same standard. Not even close.
One contributor On OpenLedger thinks their Datanet row carried the factual spine. Another thinks the model behavior did the real synthesis. Somebody else points at the adapter path or the retrieval branch and says the answer would have looked different without that surface. Now the payout view is open, the trace is open, and somehow everyone is reading the same answer as a different invoice. OpenLedger, to its credit, doesn’t hide the attribution game. Fine. It prices it. That’s the whole point. Which means the dispute doesn’t stay abstract for long. It lands in fees. It lands in revenue split. It lands in who feels underpaid and who starts looking at the next answer like a bad invoice dressed as inference.
Whatever.
I keep picturing some OpenChat output that used three things at once. One Datanet supplied the raw material. Another supplied cleaner domain detail. The model did the synthesis. Maybe OpenLoRA or some adjacent specialized surface shaped how the answer handled the request. The user sees one response. The OpenLedger system sees a payout stack. Platform fee. Model fee. Datanet fees. Contribution fees from attribution. Useful answer up top. Tiny negotiation under the floorboards.
Then someone asks the worst possible question.
Not “was the answer good?”
Worse.
Who got paid for what, exactly?
That’s the point where the chat window stops feeling like a product and starts feeling like a billing argument with better typography.
That’s where OpenLedger stops feeling like a neat inference product and starts feeling like a compensation engine with a chat window bolted to the front.
Thats the nastier OpenLedger bit. It doesn’t just serve the answer. It prices the answer. Datanets are not just passive source pools here. They are economic claim surfaces. Proof of Attribution is not just there to make the lineage look respectable. It becomes part of the split logic. Model surfaces are not just serving output. They are billing surfaces too. And once OpenChat turns the response into a fee event, attribution stops being a nice explanation layer and starts being the argument people use when money feels wrong.
That’s a nasty job to dump on an attribution trail.
A trace can be correct and the bill can still feel wrong. Those two are cousins who lie to each other at weddings.
An answer can be technically attributable and still feel economically wrong.
Say one contributor cluster keeps showing up heavier than expected. Same contributor IDs in the reward rows again. Same corner of the Datanet doing more of the carrying. Maybe the retrieval path really is leaning on that cleaner structured slice more than the rest. Fine. Good, even. The machine is doing accounting. Humans love that right up until accounting starts talking back.
That’s the part people keep underestimating. Maybe one Datanet touched many phrases but didn’t really drive the final judgment. Maybe the model did the expensive synthesis work but the visible source trail makes the Datanet look like the hero. Maybe the retrieval path sprayed a bunch of weak influence around and the split still has to pretend all that mess can be priced cleanly. Maybe the contribution logic is formally correct and still leaves one partner looking at the fee line like they just got billed for being helpful.
Doesn’t stop the partner from staring at the fee line like it insulted them personally.
A narrow contributor band might genuinely be doing more of the work. A retrieval branch might genuinely rely harder on the cleaner side of the Datanet. Still doesn’t mean the room will like what the split is saying out loud.
Now the answer is not just a response.
Its a compensation argument with punctuation.
Follow it one more step and it gets worse. Because once contributors and partners realize each answer is also a payout surface, behavior changes. Datanet owners start caring not just whether they get used, but how visibly they get used. Model providers stop asking only whether the output performs and start asking whether OpenLedger’s attribution logic is over-crediting the easy-to-cite surfaces. Partners want cleaner split logic. Finance wants something they can reconcile without opening a theology seminar about influence. Product wants the answer to feel seamless while the economics underneath it are basically a tiny multi-party settlement discussion every time someone hits send.
Lovely.
Now imagine a team budgeting around those rows. Or promising contributors that this is the fairer model. Or trying to convince outside partners that OpenLedger solved something deeper than “AI, but with better receipts.” That gap between a clean split and a believable split gets expensive very fast.
That’s where OpenLedger gets more annoying, honestly. Not because the idea is wrong. Because it’s honest enough to make the real fight visible. Most systems bury this. OpenLedger doesn’t. If OpenChat triggers platform fees, model fees, Datanet fees, and contribution fees all from one response, then the architecture is doing something more ambitious than chat. It’s trying to break one answer into payable parts. That’s a real thing. Also a very annoying thing once the breakdown is technically defensible and commercially irritating.
You can already see how this leaks into normal workflow. One partner asks why their Datanet only cleared a small share when the answer quoted its material directly. Another asks why the model fee is so high when the retrieval path looks obvious in the trace. Someone else says the answer format came from the specialized model surface and without that shaping the raw Datanet material would have been worthless to the user anyway. Nobody is really arguing about “AI ethics” anymore at that point. They’re arguing over a bill.
As they should, frankly.
OpenLedger made that inevitable the second one answer started meaning both output and payout.
And the ugly part is that none of this requires the system to be broken. That’s what makes it worse. The attribution can be technically sound. The fee logic can be functioning exactly as designed. The split can be defensible inside the rules. And the room can still hate the result because “technically fair” is a weak little shield once revenue is involved.
I’ve seen enough systems like this to know where it goes next. Contributors start optimizing for visibility in the attribution trail, not just quality. Then the split isn’t just accounting the last answer. It’s training the next Datanet fight. Model providers start scrutinizing which surfaces are overcompensated relative to the synthesis lift. Product teams get pressured to keep the fee stack understandable even when the actual influence path isn’t clean enough to deserve simple math. Then somebody has to explain why the answer that looked seamless to the user created three days of low-grade commercial resentment behind the scenes.
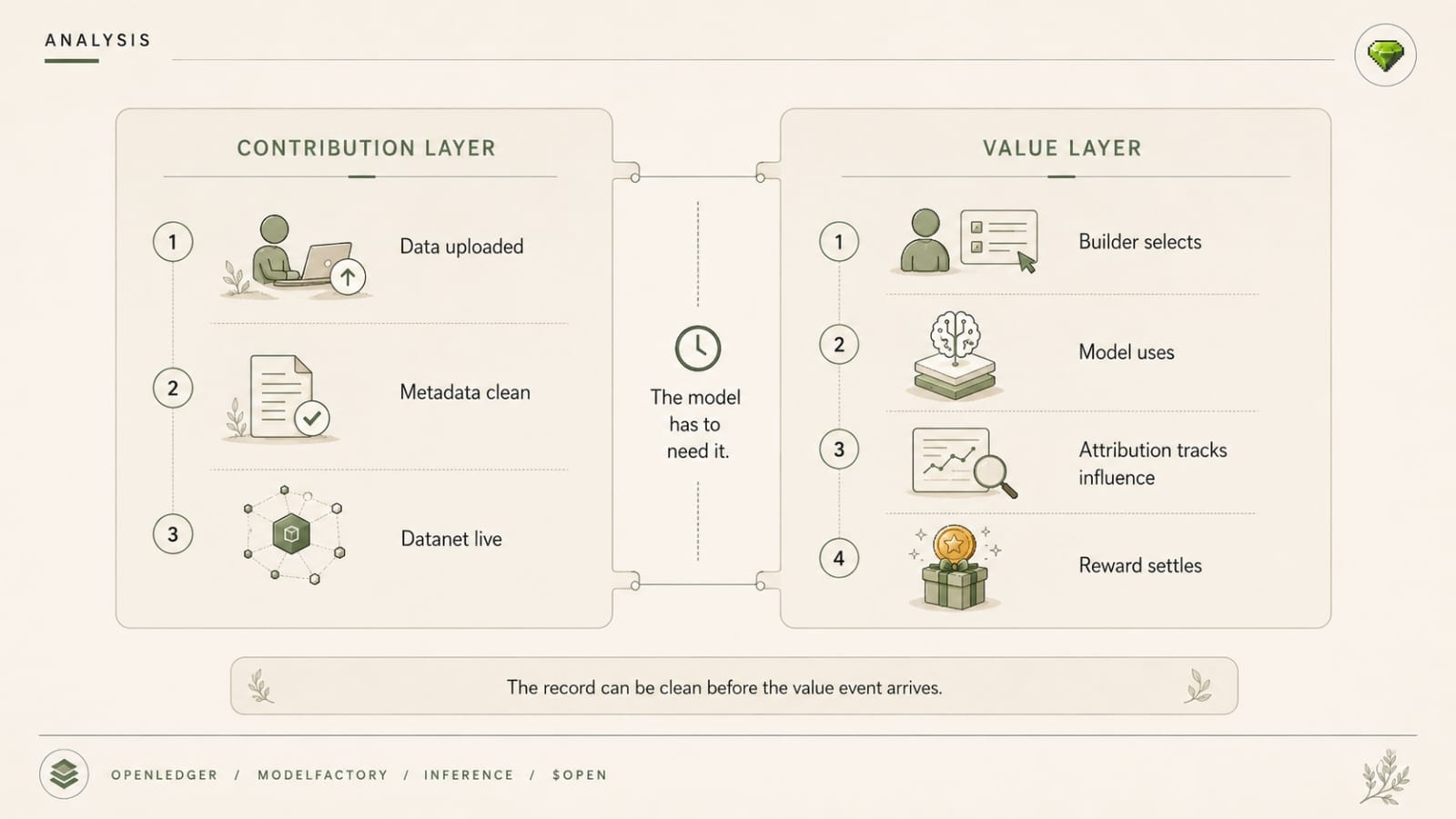
That cost lands before the next answer even does.
Not hypothetical. Not philosophical. One answer gets copied into a note. Another gets sent to a partner. Another gets used in a decision flow. The money trail behind each one starts shaping how willing people are to trust the next one. And if the split logic feels just a little off, even when the answer is decent, OpenLedger doesn’t just have an attribution problem.
Now people start asking whether showing up is even worth it.
Because now every OpenLedger OpenChat response teaches the ecosystem something about whether contributing, modeling, routing, and partnering are worth the trouble under this fee logic.
Thats why I keep getting stuck on this version of it.
Not the nice one where attribution just makes AI fairer.
The nastier one.
The answer lands.
... fees trigger.
The split looks “correct.”
And the next time on @OpenLedger the same contributors, model surfaces, and Datanets meet inside OpenChat, what exactly are they supposed to trust first... the answer, or the bill underneath it?