

I think OpenLoRA is one of those features people may scroll past too quickly. It doesn’t sound as loud as tokenomics. It doesn’t feel as exciting as agents, rewards, or big AI narratives. It probably won’t grab attention the same way a new partnership or exchange listing does.
But sometimes the boring-sounding layer is the one that actually makes the whole system work.
And that is why OpenLoRA matters.
if i try to sum up in simple words, LoRA means a lightweight way to adapt an AI model without retraining the whole thing from zero. Instead of rebuilding a massive model every time you need a new skill, tone, dataset, or use case, LoRA lets you adjust smaller parts of the model. Think of it like adding a sharp upgrade to an existing machine instead of building the entire machine again.
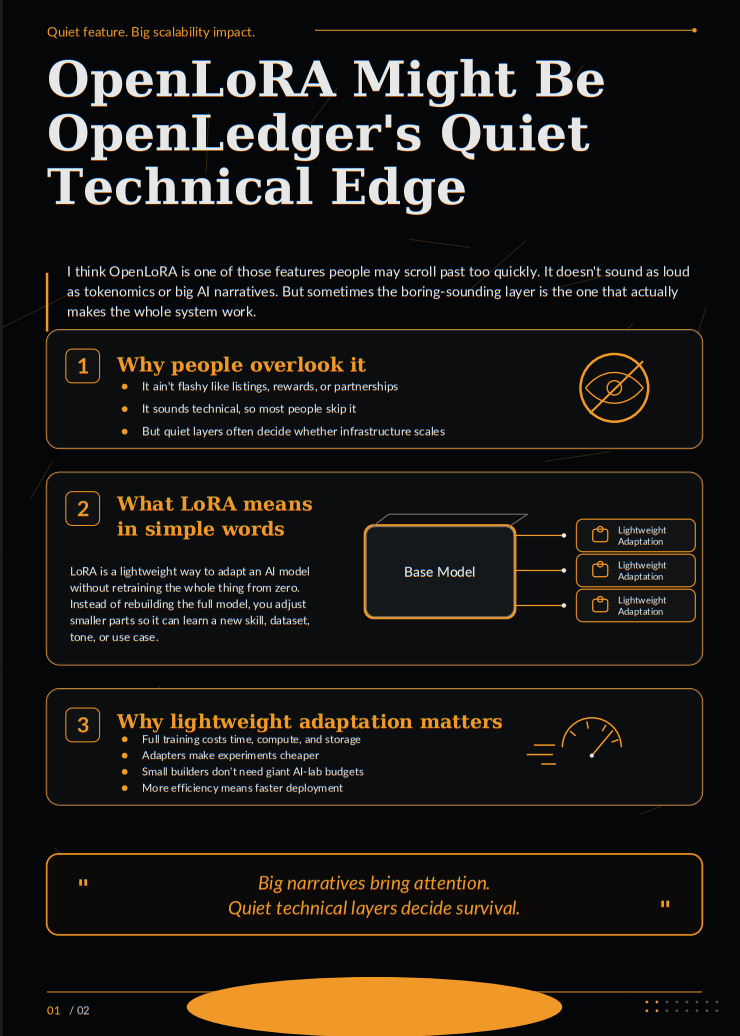
That sounds technical, but the idea is simple.
i know AI models are expensive to train. They take compute, time, storage, and serious infrastructure. If every small use case needs a full model rebuild, scaling becomes painful fast. Costs rise. Deployment slows down. Only bigger teams can afford to experiment.
That is where lightweight model adaptations become important.
OpenLoRA could help OpenLedger make AI deployment more practical. Instead of treating every model like a giant standalone product, OpenLedger can support smaller, more focused adaptations built on top of existing models. That means more builders, more datasets, more specialized outputs, and less waste.
I feel this fits OpenLedger’s bigger idea really well.
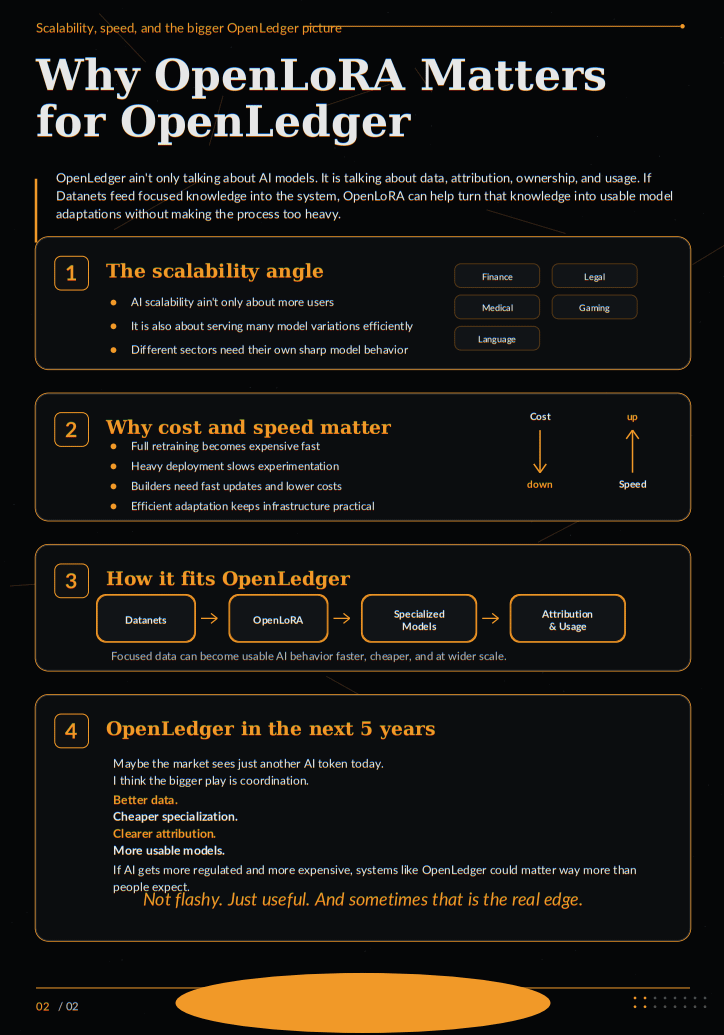
OpenLedger is not only talking about AI models. It is talking about data, attribution, ownership, and usage. If Datanets are feeding focused knowledge into the system, then OpenLoRA can become the layer that helps turn that focused knowledge into usable model adaptations without making the process too heavy.
That matters because scalable AI ain’t just about having powerful models.
It is about serving many models efficiently.
One model for finance. One model for legal docs. One model for medical research. One model for gaming. One model for regional language data. One model for a specific community dataset. If every one of these needs massive compute and full retraining, the system becomes slow and expensive.
But if OpenLoRA makes it easier to create lighter versions, then OpenLedger can support more model variety without breaking under the weight of cost and infrastructure demand.
That is the real scalability angle.
i really think that speed matters too. In AI infrastructure, slow deployment kills momentum. Builders want to test ideas quickly. Users want fast responses. Enterprises want predictable performance. A system that takes too long or costs too much to update won’t feel useful, no matter how strong the narrative is.
OpenLoRA could reduce that friction.
i also think that It could make model updates faster. It could make experimentation cheaper. It could allow more specialized AI tools to exist without needing huge budgets. And in the long run, that kind of efficiency can matter more than hype.
Most people in crypto chase the loud part first.
They look at price, listings, market cap, and short-term attention. I get it. That is the game most people are playing. But infrastructure usually wins or loses in the quiet layers. The parts nobody talks about much are often the parts deciding whether the system can handle real demand.
OpenLoRA feels like one of those quiet layers.
i wanna say it .... It may not be the headline feature. It may not be the thing that gets the loudest posts. But if OpenLedger wants to support a real economy of datasets, models, agents, and attribution, then it needs efficient ways to deploy and adapt AI models at scale.
Big narratives bring attention.
Quiet technical layers decide survival.
And that is why OpenLoRA might be one of OpenLedger’s most underrated edges.
And looking 5 years ahead, this is where OpenLedger could get really interesting.
Not because it is trying to scream “AI crypto” louder than everyone else.
But because the market may slowly realize that AI infrastructure is not just about who has the biggest model.
It is about who can organize data better.
Who can track contribution better.
Who can make specialized models cheaper to build.
Who can prove where intelligence actually came from.
so i reached to this conclusion that OpenLedger keeps building in that direction, then $OPEN could move from being seen as just another AI token to something closer to a real coordination layer for data, models, agents, and payouts.
That is the bigger play guys ....
Quiet now.
Maybe misunderstood now.
i think in the next 5 years, if AI becomes even more regulated, more specialized, and more expensive to run, then systems like OpenLedger could matter way more than people expect today.
@OpenLedger #OpenLedger $OPEN
