Lembro de uma conversa que tive há um tempo com um amigo que trabalha com IA. Passamos horas falando sobre modelos, potência de computação, GPUs e todas as coisas habituais que as pessoas associam com inteligência artificial.
Na época, eu supunha que era ali que a verdadeira competição estava acontecendo.
Construa modelos maiores. Treine com mais dados. Tenha acesso a mais potência de computação.
Simples.
Mas quanto mais eu acompanhava o espaço, mais eu começava a notar algo que parecia ser negligenciado.
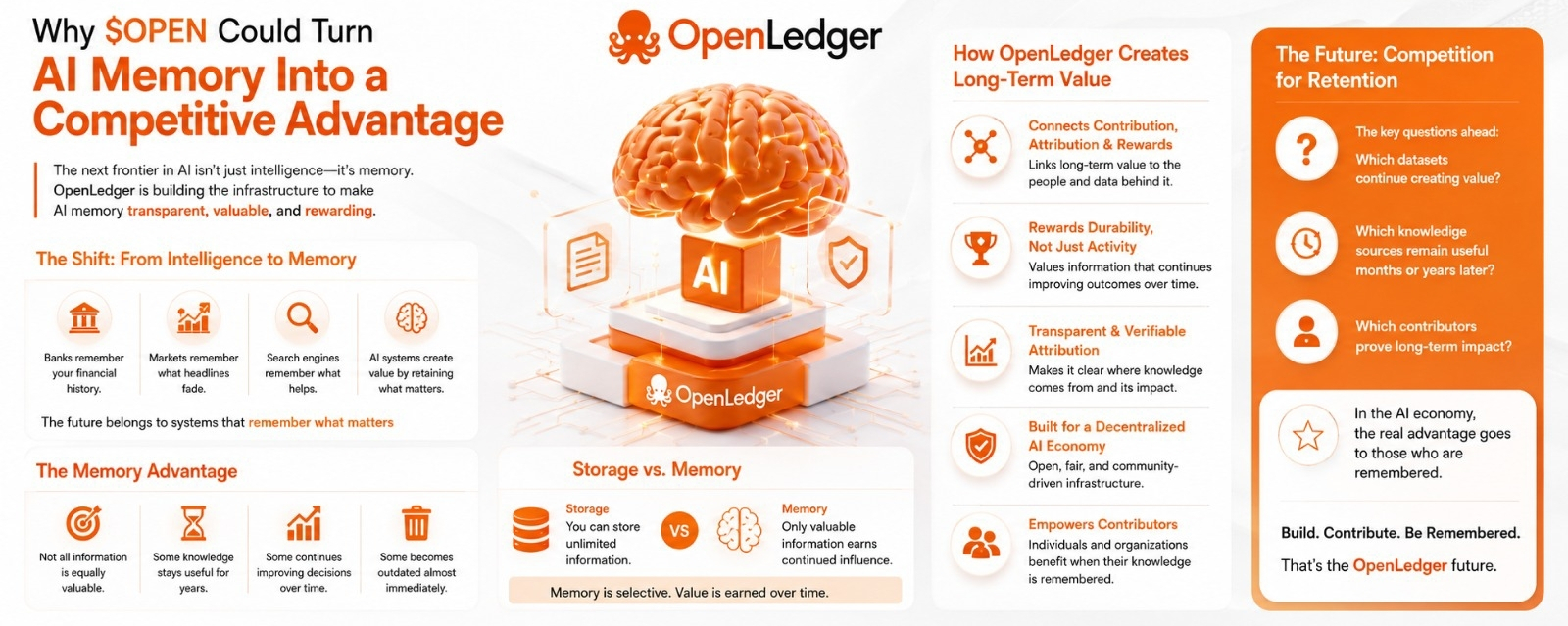
Não era inteligência.
Era memória.
Não é memória no sentido técnico. Quero dizer memória na forma como sistemas de sucesso lembram do que importa e ignoram o que não importa.
Uma vez que comecei a pensar sobre isso, vi exemplos em todos os lugares.
Os bancos lembram seu histórico financeiro.
Os mercados lembram informações muito depois que as manchetes desaparecem.
Os motores de busca lembram quais fontes ajudam consistentemente os usuários.
Os sistemas que criam mais valor muitas vezes não são os que sabem mais. Eles são os que retêm as informações mais úteis ao longo do tempo.
Essa é uma das razões pelas quais a OpenLedger continua chamando minha atenção.
A maioria das discussões sobre IA hoje ainda está focada em gerar melhores respostas. Mas eu me pergunto sobre uma pergunta diferente:
Como a IA decide o que merece ser lembrado?
Porque nem toda informação é igualmente valiosa.
Algum conhecimento permanece útil por anos.
Algumas tornam-se obsoletas quase imediatamente.
Algumas informações continuam melhorando decisões muito tempo depois de entrarem em um sistema, enquanto outras perdem relevância silenciosamente.
E agora, parece que a indústria gasta muito mais tempo discutindo como a IA aprende do que como ela lembra.
Quanto mais penso sobre isso, mais sinto que a memória pode ser um problema econômico tanto quanto um técnico.
Imagine duas pessoas contribuindo com informações para uma rede de IA.
Um contribui com dados que continuam melhorando os resultados anos depois.
O outro contribui com informações que pareciam úteis inicialmente, mas rapidamente se tornaram irrelevantes.
À primeira vista, ambas as contribuições podem parecer igualmente valiosas.
A diferença só se torna visível com o tempo.
É aí que a abordagem da OpenLedger se torna interessante para mim.
O que se destaca não é a promessa de uma IA mais inteligente. Quase todo projeto alega isso.
O que se destaca é a ideia de conectar contribuição, atribuição e recompensas de uma forma que torna o valor a longo prazo visível.
Eu continuo comparando isso com o que aconteceu com a internet.
Nos primeiros dias, a informação estava em todo lugar, mas encontrar informações úteis era difícil.
Então os motores de busca introduziram sistemas de classificação.
De repente, o conteúdo não estava apenas competindo para existir.
Estava competindo para permanecer visível.
A IA pode estar caminhando para um momento semelhante.
Exceto que desta vez, a competição pode não ser pela atenção.
Pode ser para retenção.
Quais conjuntos de dados continuam criando valor?
Quais fontes de conhecimento permanecem úteis meses ou anos depois?
Quais contribuintes podem provar que suas informações continuam melhorando os resultados muito tempo depois de serem enviadas?
Essas perguntas parecem cada vez mais importantes à medida que a IA se envolve mais em decisões do mundo real.
Uma coisa que percebi é que armazenamento e memória não são a mesma coisa.
Você pode armazenar informações ilimitadas.
Isso não significa que qualquer uma delas importa.
A memória é seletiva.
Algumas informações ganham influência contínua.
A maioria das informações não é.
Se a OpenLedger puder ajudar a tornar esse processo mais transparente, os contribuintes podem começar a otimizar para algo diferente.
Não volume.
Durabilidade.
E a durabilidade é muito mais difícil de falsificar.
Qualquer um pode fazer upload de dados.
Qualquer um pode criar conteúdo.
Já vimos isso na internet por anos.
Mas a informação que permanece útil muito tempo depois de criada é muito mais rara.
Um conjunto de dados que ainda está melhorando resultados dezoito meses depois conta uma história.
Uma fonte que continua sendo referenciada em milhares de interações conta outra.
Com o tempo, o mercado começa a distinguir entre informações que existem e informações que sobrevivem.
Essa é uma distinção que eu acho que se torna mais importante à medida que a IA se aprofunda em áreas como finanças, software empresarial, saúde e outros ambientes onde as decisões têm consequências reais.
Porque eventualmente as pessoas farão perguntas que são surpreendentemente simples.
Por que a IA fez aquela recomendação?
Que informação influenciou aquela decisão?
De onde veio esse conhecimento?
No momento em que essas perguntas se tornam importantes, a atribuição também se torna importante.
Claro, nada disso garante que a OpenLedger tenha sucesso.
Os desafios são reais.
Medir o valor da informação é incrivelmente difícil.
O conhecimento não flui através de pipelines organizados.
Diferentes fontes influenciam os resultados simultaneamente.
A atribuição se torna confusa.
E como todo sistema que introduz recompensas, sempre haverá tentativas de manipulá-lo.
Já vimos isso com os motores de busca.
Já vimos isso com as mídias sociais.
As redes de IA não serão diferentes.
Mas isso é na verdade parte do que torna a oportunidade interessante.
O problema ainda está no início.
Ninguém resolveu isso completamente.
O que me mantém prestando atenção não é a ideia de que a memória da IA deve ser permanente.
É a ideia de que a memória poderia se tornar competitiva.
Talvez a economia futura da IA não seja definida apenas por quem constrói os modelos mais inteligentes.
Talvez isso também seja definido por quem contribui com informações valiosas o suficiente para serem lembradas.
E isso parece ser uma oportunidade muito maior do que a maioria das pessoas percebe.
@OpenLedger #OpenLedeger #openledger $OPEN
