
Okay...so the longer I look at ModelFactory on OpenLedger, the more I keep coming back to the same uncomfortable version of #OpenLedger .
Actually...
Not the nice version where a small private model just starts being useful and everybody nods because the workflow got faster. Fine. That version is real. A narrow model can absolutely start doing real work before most teams have the patience to explain why.
The worse version is when the model is already useful and the Datanet is still sitting below the row threshold, so the workflow is live before the attribution side is ready to stand up properly.
Alright...
Because the clean pitch of OpenLedger sounds bundled. Train the model. Deploy the model. Attribution follows the model. Economics follow attribution. Everybody gets their little piece of truth and their little piece of money. Nice. Except none of it actually turns on together.
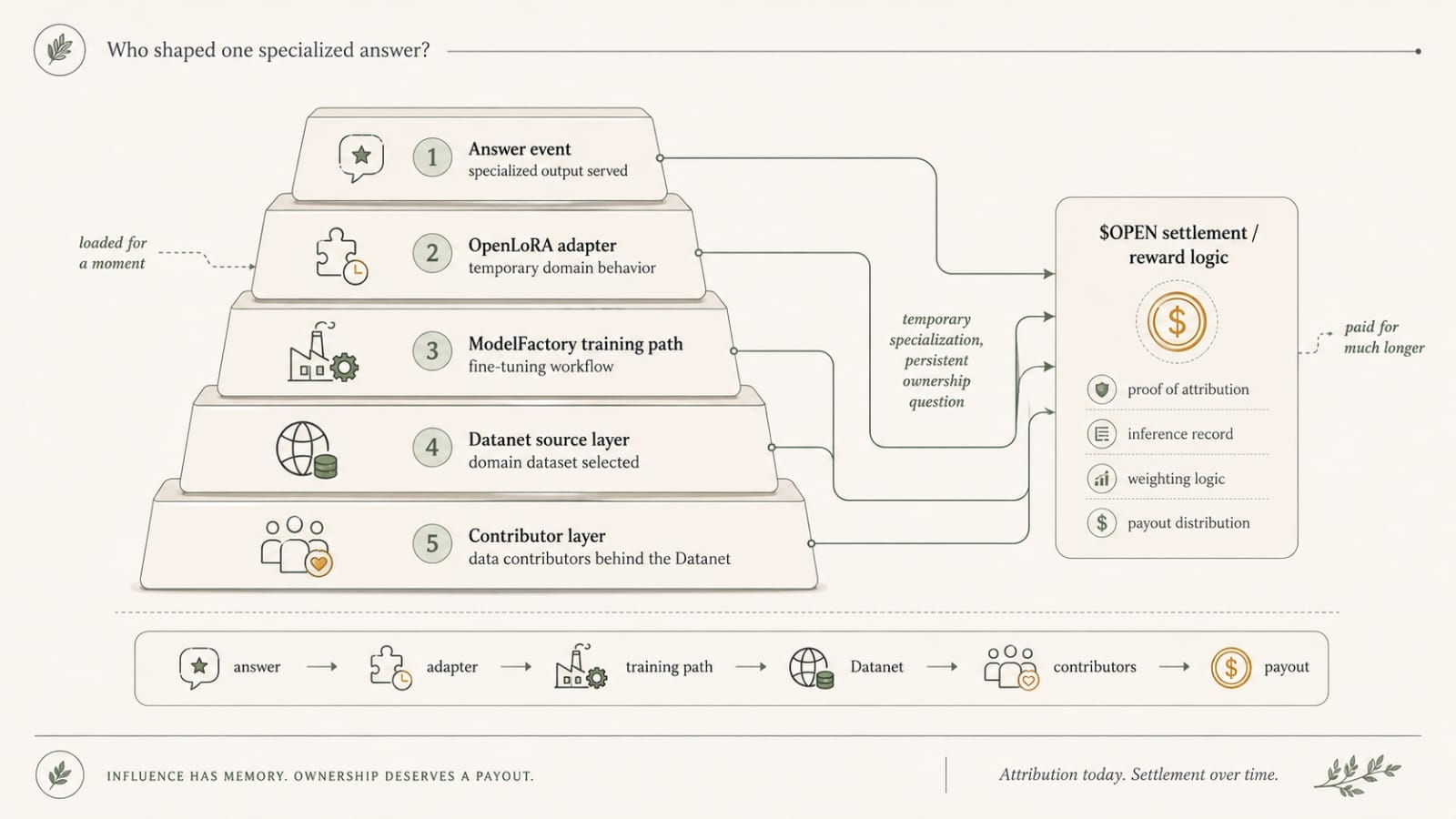
A team can already have the model working while the attribution side is still sitting there waiting on row count.
That row threshold is not decorative on OpenLedger. It decides when the payable part can stop pretending and actually speak.
Not a branding problem. Workflow problem.
Say a team has one narrow Datanet. Not huge. Just good. Maybe research notes in one vertical. Maybe policy summaries. Maybe some compliance-heavy internal material nobody wants to dump into a public sludge lake and call innovation. They train privately in OpenLedger's ModelFactory, test privately, keep the thing out of public view, and the model starts doing real work. Drafts cleaner. Routes faster. Summarizes the right way. Maybe not beautiful. Doesn’t matter. Useful.
ModelFactory already did its part. The row gate didn’t.
Useful is enough to start habits.
That’s usually when I stop listening to the clean pitch.
By then the workflow is already learning around the model, which is usually where the tidy product story starts lying.
And habits show up earlier than economics all the time.
Thats the part I keep getting stuck on. somehow...
The workflow can already be real while the attribution side is still half-assembled in the corner waiting for 1,500 rows. The model is already helping. The row gate still isn’t open. That’s not the same thing.
If the model is already helping the team move faster, write better, filter better, whatever, then value is already being created. The question is whether OpenLedger is actually ready to price that value the way it said it would?
Big difference.
Maybe not yet.
Try telling that to a team thats already saving time with it.
I've seen enough teams take the useful part first and let the accounting logic explain itself later.
That’s a nasty little gap.
Because in a normal private model stack, fine. Nobody cares. The team trains a model, it works, end of ugly story. But OpenLedger is not selling plain fine-tuning and a quiet sandbox. It is selling the idea that model value can be decomposed, attributed, and paid through. Datanets matter. Rows matter. Provenance matters. Payable AI matters. None of it arrives at the same time. That’s the whole mess.
Private model path live.
Attribution-linked payout logic still waiting on rows.
I can already hear somebody trying to smooth that over with product language. Bad idea. Because the workflow won’t wait. If the small model is helping the desk or the internal team or the support channel or whoever, they will use it. Obviously. Humans do not postpone useful tools just because the economic philosophy under them is still loading. They take the gain first and let the accounting department suffer later. Ancient tradition.
Now imagine that team two weeks in. Model is live inside some narrow process. Notes get drafted through it. Screening gets faster. Maybe internal routing gets cleaner. The Datanet is still below the attribution threshold, though.
Row count still sitting there under the line while the model is already inside the workflow.
Same draft path getting used. Same internal note flow speeding up. Counter still short.
So the model is doing useful work before the contribution economics are legible enough to do OpenLedger's full trick. Good. Great even. Now ask the irritating question.
What exactly is live here?
The model, sure. But is the OpenLedger promise live, or just the useful part?
That’s not a fake question either. Finance and product will answer it differently in about ten seconds.
The model, yes.
The value, yes.
The OpenLedger's attribution-linked payout logic? Not really. Not all the way. Not in the way the big promise implies.
That’s where it gets rude.
Because once a model is useful, people start treating it like infrastructure. They stop talking about setup and start talking about reliance. Which means the missing part is no longer some abstract roadmap feature. It becomes the thing that’s absent from an already-working economic surface.
The private model path is helping. The Datanet exists. Deployment is possible. The row threshold is still sitting there refusing to let the payable part talk properly.
That little number starts looking very different once the model is already inside somebody’s process.
But the “who shaped this and who gets paid for that” part is still partially gated by row count.
That’s usually the point where I stop trusting the bundled product story.
OpenLedger leaves the mismatch visible. Good. Still awkward as hell.
A team with a narrow, high-value dataset may not need 1,500 rows to get something operationally real. That’s the point. High-value datasets are rude like that. Small. Concentrated. Effective. One ugly little dataset can do a lot if it is clean and targeted enough. ModelFactory does not care whether the philosophical symmetry of the product stack has arrived yet. If the thing trains and performs, teams will treat it as useful. The system does not get to say “please wait until the attribution story is emotionally complete.”
Nobody waits.
Then the weird pressure starts.
If the model is already useful, contributors start wondering when the economic layer catches up.
Fair question, considering the useful part already showed up to work.
If the dataset came from a narrow team effort, somebody starts asking whether the value is already being extracted before the attribution-linked economics are really switched on. If the model gets deployed publicly later, now the before-and-after line matters too.
Because once the same model lineage starts touching a public path, or a partner demo, or an agent workflow, nobody cares that the useful phase used to be private. Value is value.
The timing still counts.
Private usefulness first. Public economics later. Same model lineage. Different political weather.
Useful in private first. Public later. Attribution readiness somewhere in between. Nice messy sequence.
This is where OpenLedger gets more annoying than a normal training stack.
That threshold is not paperwork. It decides when OpenLedger gets to claim the payable part is real.
OpenLedger's ModelFactory can prove usefulness before the Datanet is large enough to make attribution fully legible. So the model is live first. The compensation surface isn’t.
That timing mismatch is not abstract once teams are already building habits around the model.
That split stops being theoretical the second somebody is already relying on the model.
Say the model gets passed around internally because it’s good. Not public yet. Still private. Still useful. One team leans on it for analysis. Another for triage.
Same internal model path underneath. Same Datanet still growing toward the threshold.
Same private surface. Different teams already building habits around it.
Nobody waits for the row counter to become morally satisfying first.
Maybe a partner sees a demo and starts asking when it goes live. Meanwhile the Datanet is still growing row by row, trying to cross the threshold where the attribution story stops feeling partial and starts becoming something the economics can lean on properly. So the model’s operational trust is compounding before the attribution trust is.
That delay is not neutral. Not once the model is already inside somebody’s workflow.
And once value is felt before attribution is fully active, the politics get ugly fast. Nobody phrases it that way, obviously. They say things like “early-stage workflow” or “private validation” or “pre-public testing.” Fine. Still the same issue. The model is already creating advantage while the system’s big fairness machinery is not fully awake yet.
That’s the exact kind of sequence people remember later when they start asking who got paid, who got recognized, who carried the early lift, who benefited first, and why the clean economics only seem to arrive after the useful part was already proven.
OpenLedger does not get to hide from that by saying the model was private. Private can still be valuable. Valuable can still be relied on. Relied on can still create internal winners before the external attribution layer catches up.
Private doesn’t mean economically irrelevant. It just means the bill shows up later and uglier.
If the product promise is bigger than “train a model privately,” then the gap between usefulness and attribution-readiness is not a side note. It is one of the actual tensions.
Follow the workflow and the timing mismatch is sitting right there in the middle of it. ModelFactory lets the team train and test privately. Datanet row count still governs when attribution becomes economically meaningful enough to act like the full story. Deployment makes the model public later, but operational value may have started showing up earlier. So the model lifecycle and the attribution lifecycle are not perfectly synchronized.
There it is. Annoying little timing mismatch. Very real.
One OpenLedger surface is already doing useful work. Another is still standing there waiting for enough rows before it can claim the economics honestly.
And if PoA only becomes legible enough later, then the story OpenLedger tells about who shaped the value is arriving after the workflow already made up its mind.
That doesn’t mean the system is broken. Makes it worse, actually. It means the system can be functioning exactly as designed while the economic promise arrives later than the practical value.
Harder to hand-wave, anyway.
Because a broken system is easy to blame. A system where usefulness arrives first and fairness arrives second is much more uncomfortable. It makes everyone choose which part they think is the real product. The model that already works. Or OpenLedger the attribution-linked economics that supposedly justify why this stack matters more than a private fine-tune in a closed room.
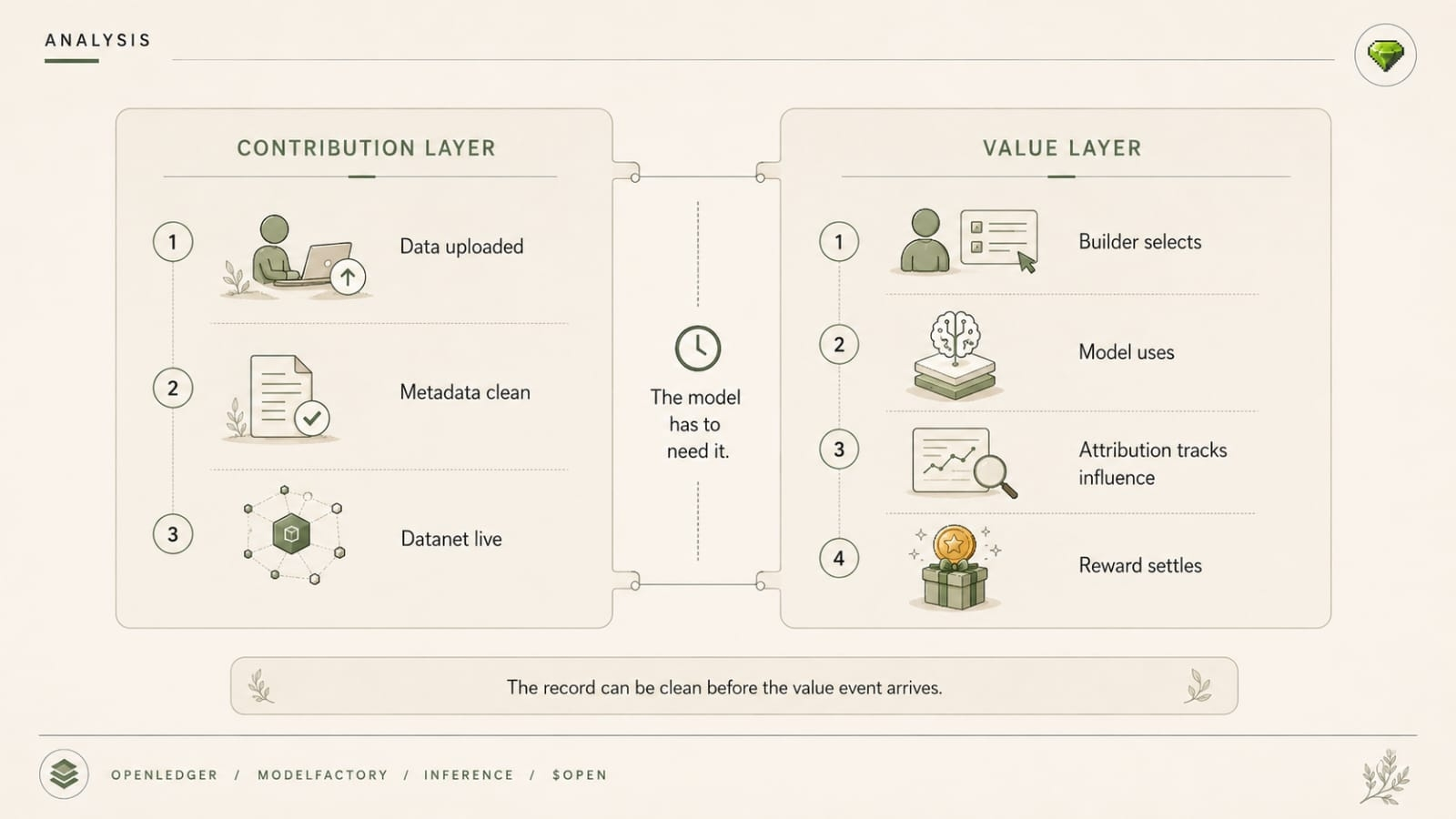
Follow it one more step and it gets uglier.
If the small model is already useful, teams will scale trust around it. Internal dependence first. Public story later. Then once the Datanet crosses the threshold and the attribution logic wakes up properly, the economic narrative arrives after the behavioral narrative already formed.
The model already earned trust before the economics showed up to explain it.
That’s a bad order if your whole story depends on attribution arriving on time.
That’s the kind of timing people pretend is harmless until someone asks who benefited first.
So maybe the economics are not building trust at all. Maybe they’re showing up later to explain trust that formed without them.
Different job. Uglier one.
Model useful already.
Rows still short.
OpenLedger can live with that technically. Fine.
But once the team is already relying on the thing, what exactly are they supposed to call the value that was already moving through the workflow before OpenLedger was ready to say who earned it?