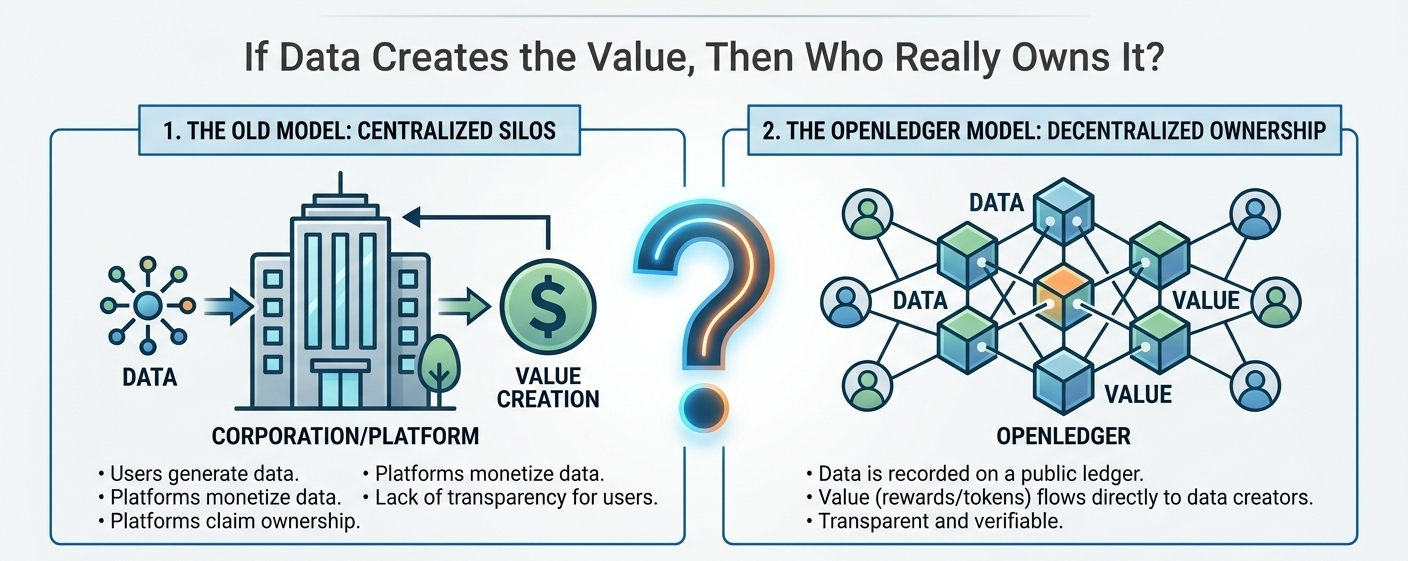
I used to think data in AI systems was just background fuel, something that sits quietly behind models while value is created somewhere else.
At first, I didn’t really understand why projects like OpenLedger ($OPEN) were framing data almost like an economic asset. It sounded like a narrative shift rather than a structural one. I assumed AI value still came mainly from models, not the raw information feeding them.
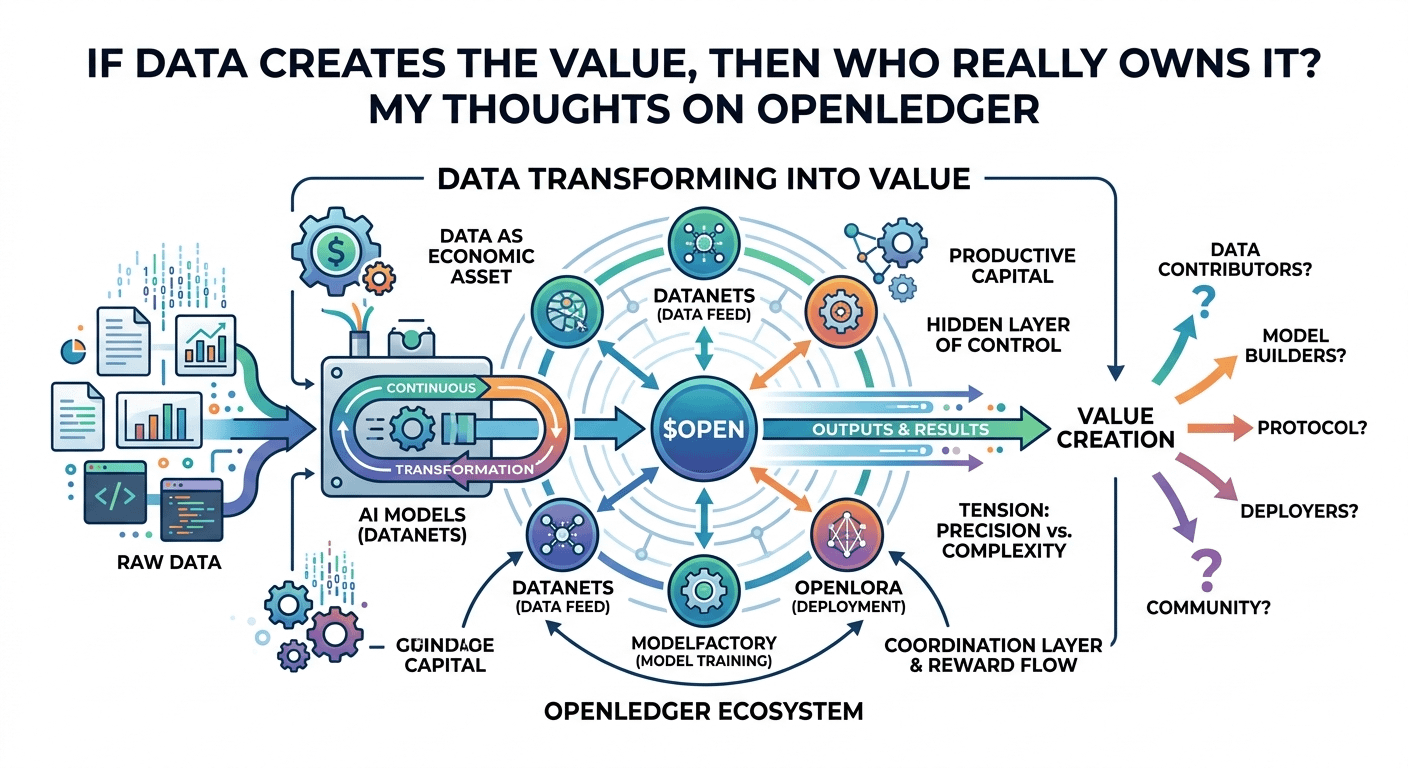
What changed my thinking was the idea that AI is no longer just consuming data, but continuously transforming it into usable outputs that can be reused, priced, and routed through systems. It feels like data is slowly losing its “invisible” status and becoming something closer to an active participant in value creation.
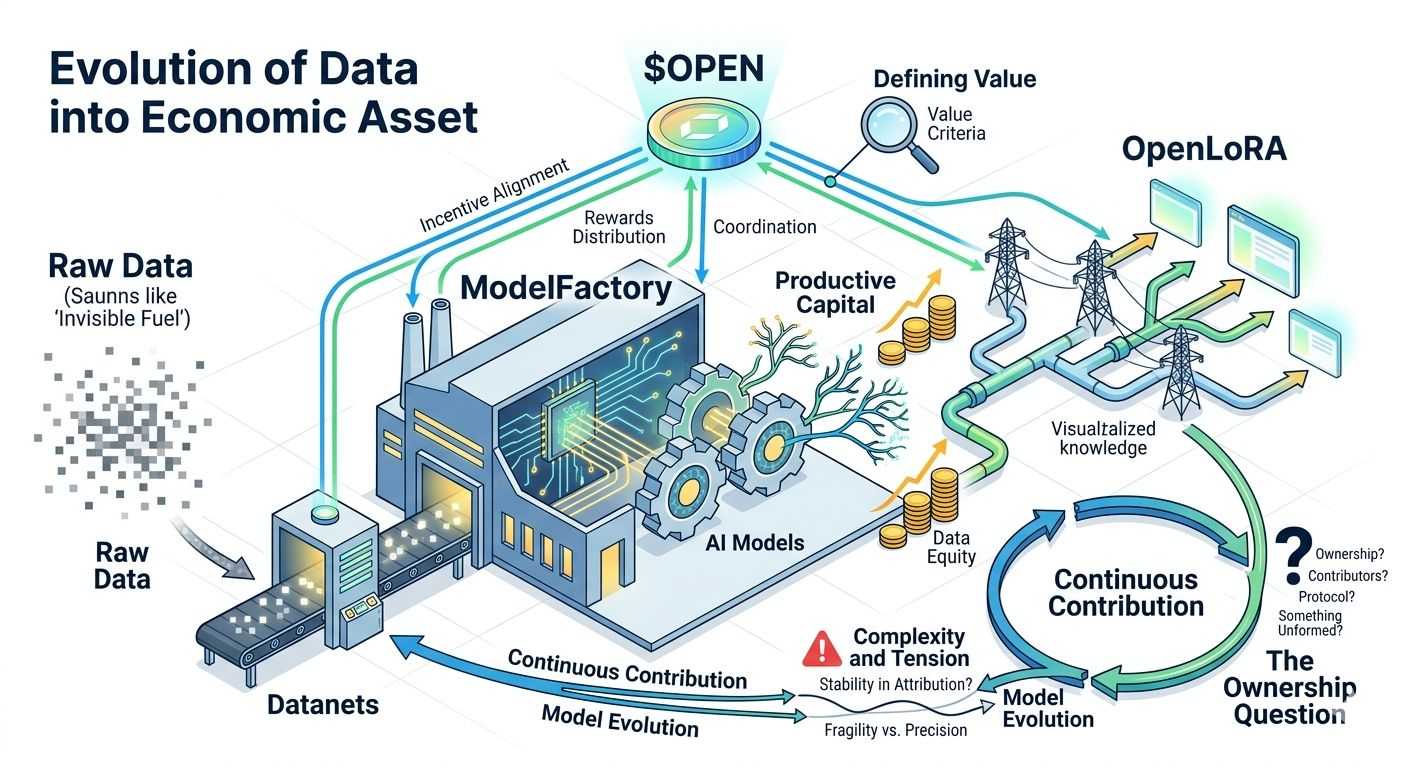
Looking at OpenLedger’s structure, what stood out to me is how it tries to connect the entire lifecycle into one controlled flow. From Datanets feeding models, to ModelFactory shaping them, to OpenLoRA handling deployment, and $OPEN acting as the coordination layer in between. It feels less like a simple ecosystem and more like an attempt to define how value moves from raw contribution to final output.
On a deeper level, the interesting part is not just token distribution or staking mechanics, but how the system tries to define what “valuable data” actually means. That definition itself becomes a form of power. Whoever sets the criteria for usefulness indirectly decides where rewards flow. I could be wrong, but that hidden layer of control feels more important than the technology itself.
In real usage, this creates a loop where data contributors, model builders, and deployers are all tied into the same incentive structure. But at scale, I keep wondering how stable attribution can remain when models evolve so quickly. What is considered “contribution” today may not hold the same meaning tomorrow.
And that’s where the tension appears. The more precise the system tries to be in tracking ownership and rewards, the more fragile and complex it becomes in practice. Complexity here doesn’t just slow things down, it can distort fairness itself.
Zooming out, this feels like part of a wider shift in AI systems. Not just about who builds intelligence, but who governs the flow of value created after intelligence is deployed. If data is truly becoming productive capital, then ownership can no longer stay static or clearly assigned.
That brings me back to a simple but uncomfortable question. If data generates value continuously inside systems like OpenLedger, then who actually owns that value at the end of the cycle?
Maybe it belongs to contributors, maybe to the protocol, or maybe to something in between that hasn’t fully formed yet. Or maybe the system is still learning how to define ownership while it is already creating it.