Às vezes eu acho que a maioria das pessoas ainda não entende o quão importante a "validação de dados" vai ser no mundo da IA autônoma.
Se eu tivesse que dizer isso do fundo do meu coração, é porque toda a discussão ainda está presa na quantidade. Qual modelo tem mais parâmetros, qual raspou mais terabytes de texto, qual empresa acumulou a maior fazenda de servidores. Mas por baixo disso, algo muito mais profundo está acontecendo… e isso provavelmente é a pureza dos dados. Quem realmente limpa e verifica as informações antes da máquina aprender? E, honestamente, quanto mais olho para a arquitetura do OpenLedger Datanet, mais parece que eles não estão apenas criando mais um balde de armazenamento descentralizado. Eles estão realmente tentando redefinir a relação entre informação bruta e verdade verificada.
Parece grande. Talvez até extra grande – quero dizer algo absolutamente massivo. E pode levar mais alguns ciclos para as pessoas entenderem se essa validação descentralizada realmente funcionará em escala sob estresse de raspagem pesado. No entanto…. há algo diferente aqui em nível estrutural. Porque, tradicionalmente, modelos de IA absorvem vastos oceanos de lixo da internet – mas uma vez que o modelo começa a alucinar ou tomar decisões ruins, os dados tóxicos subjacentes ficam completamente ocultos dos usuários que dependem deles.
O modelo aprende tudo.
O sistema não verifica nada.
Esse desequilíbrio existe há muitos anos.
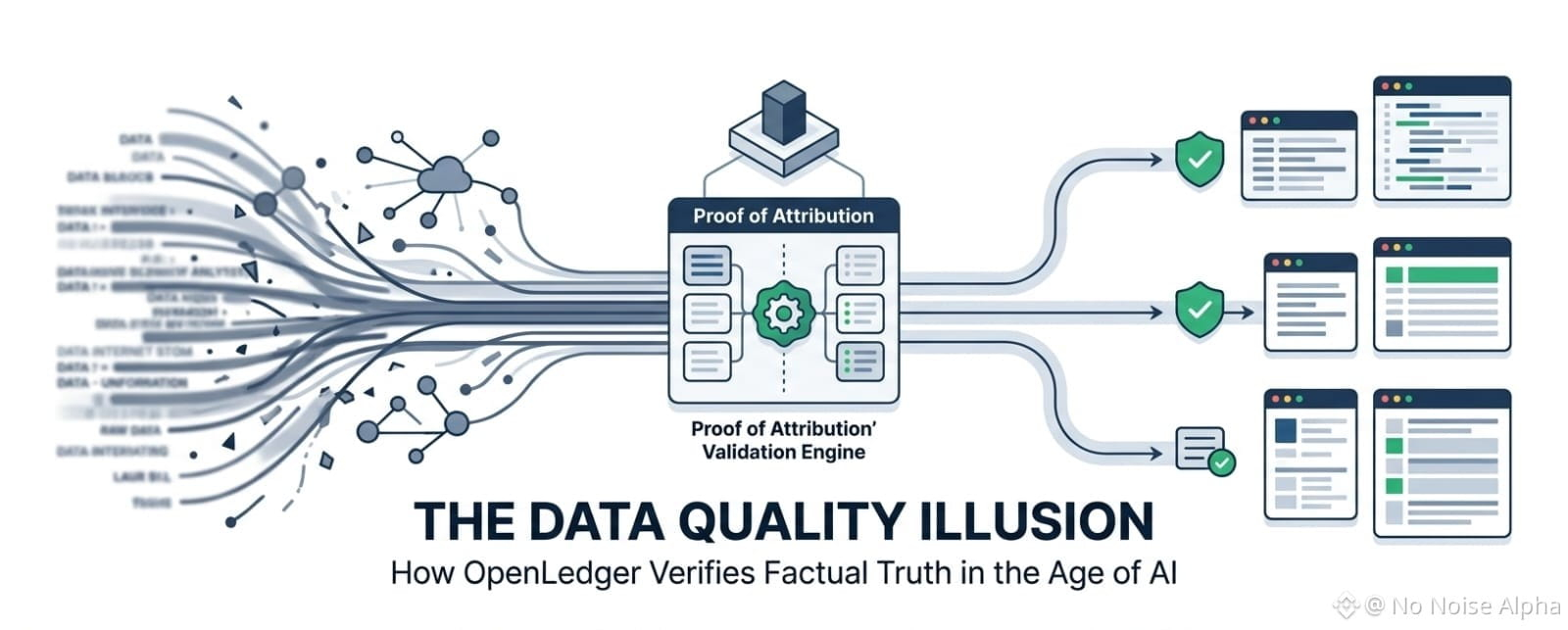
E, para ser honesto, é aqui que o foco da OpenLedger em dados verificáveis começa a parecer interessante para mim. Não por branding. Honestamente, projetos de cripto lançam novos mercados de dados quase toda semana. Mas, desde que a estrutura de contribuição se moveu para a execução ao vivo, a discussão mudou de teoria de raspagem para realidade econômica. Agora, a camada Datanet não é mais apenas um desenho conceitual. Os contribuidores podem enviar conjuntos de dados específicos, os validadores verificam fisicamente a qualidade, e contratos inteligentes gerenciam as métricas de atribuição na blockchain. Isso muda a estrutura psicológica da criação de conjuntos de dados.
De repente, os dados não são mais apenas combustível bruto.
Isso se torna um ativo verificado e rastreável.
E eu acho que essa distinção é mais importante do que as pessoas pensam. Especialmente depois de olhar de perto como o motor de Prova de Atribuição lida com entradas sobrepostas. A arquitetura depende de alimentar contexto curado por humanos diretamente em um motor de validação distribuído. Se um conjunto de dados específico estiver envenenado com fatos falsos, ou se um bot fornecer intencionalmente spam, a pontuação de qualidade cai instantaneamente. Ao rastrear essas mudanças de qualidade em nível granular, a estrutura tenta atribuir matematicamente qual contribuinte realmente forneceu o sinal limpo. Porque mapear uma resposta limpa de IA de volta a uma teia opaca de sites raspados é um obstáculo de engenharia desconfortável.
As fontes são coletivas.
As origens estão borradas.
Quase inrastreável.
Então, tentar isolar a origem exata de uma única entrada factual dentro de um enorme corpus de treinamento… é na verdade um problema de infraestrutura extremamente ambicioso. E talvez imperfeito. Eu não acho que a verificação de dados algum dia será completamente pura matematicamente. No entanto, tentar pelo menos criar uma camada de validação transparente parece uma mudança diferente de onde a indústria estava indo. A maioria das plataformas otimiza a simples extração de dados. A OpenLedger está pelo menos tentando otimizar a responsabilidade dos dados. Ou pelo menos indo nessa direção.
E aqui está outra coisa que continuo pensando... a realidade legal e comercial para as pessoas que realmente constroem essas coisas. Quando você olha para uma IA polida respondendo a uma pergunta médica ou financeira complexa, parece incrivelmente inteligente. Mas, no mundo prático, empresas e desenvolvedores não estão olhando para a interface suave. Eles estão fazendo perguntas difíceis:
Esse conjunto de dados é legalmente limpo?
As fontes são verificadas?
Como o modelo lida com entradas envenenadas?
As origens vão se sustentar no tribunal?
E isso poderia mudar toda a dinâmica do ecossistema da máquina comercial. Observando a abordagem da OpenLedger para conjuntos de dados específicos de domínio, eles parecem cientes dessa realidade. Eles não estão tentando construir um scraper genérico que rouba tudo. Eles estão focando em ambientes de dados especializados e de alta fidelidade. Honestamente, parece refrescante em um mercado onde muitos projetos ainda estão tentando ser "camadas de dados para tudo". Mas, ao mesmo tempo..... não acho que a jornada será fácil a partir daqui. Porque onde as recompensas econômicas reais encontram a submissão de dados, comportamentos imprevisíveis surgirão.
Laços de dados sintéticos.
Manipulação de qualidade.
Fazenda de spam.
Disputas de validação.
Essas pressões são inevitáveis. Então, o verdadeiro teste provavelmente começa agora, à medida que mais construtores conectam seus conjuntos de dados personalizados na pilha. O processo de validação permanecerá forte mesmo quando escalar por milhares de envios paralelos? A pontuação de qualidade será confiável em milhões de interações autônomas? Os incentivos de longo prazo manterão os validadores honestos?
Honestamente.......
Não sei ao certo. Mas talvez essa incerteza seja o que torna esta fase importante. Porque, após um longo tempo, um projeto está surgindo que não está apenas falando sobre poder computacional abstrato ou narrativas especulativas. Eles estão tentando responder a uma pergunta muito mais desconfortável:
“Se os sistemas de IA se tornarem a base do nosso conhecimento.… a infraestrutura realmente saberá o que é verdadeiro e o que é falso?”
E, para ser honesto, acho que a indústria terá que enfrentar essa questão mais cedo ou mais tarde. A OpenLedger pode não ter todas as respostas ainda. No entanto, parece que esta é uma das poucas arquiteturas que não evita a realidade confusa da qualidade dos dados, mas sim tenta construir uma base permanente em torno disso de qualquer maneira.
Se você está atualmente ajustando ou experimentando conjuntos de dados personalizados, como está lidando com a validação de origem em escala agora?
@OpenLedger #openledger #OpenLedger $OPEN
