Eu já rodei bastante no meio da Inteligência Artificial e das conversas sobre cripto para saber quando um pitch é apenas um terno limpo em uma ideia fraca. A maioria dos modelos de recompensa nesse espaço ainda parece preguiçosa. Junte-se, clique, poste, stake, farm, repita. Isso conta movimento. Não pergunta se o seu trabalho realmente trouxe melhorias. Essa é uma maneira ruim de precificar a contribuição humana, e fica ainda pior quando dados de IA estão envolvidos.
@OpenLedger with $OPEN vale mais uma lida atenta porque tenta lidar com esse velho emaranhado, quem deve ganhar quando muitas mãos moldam um único modelo?
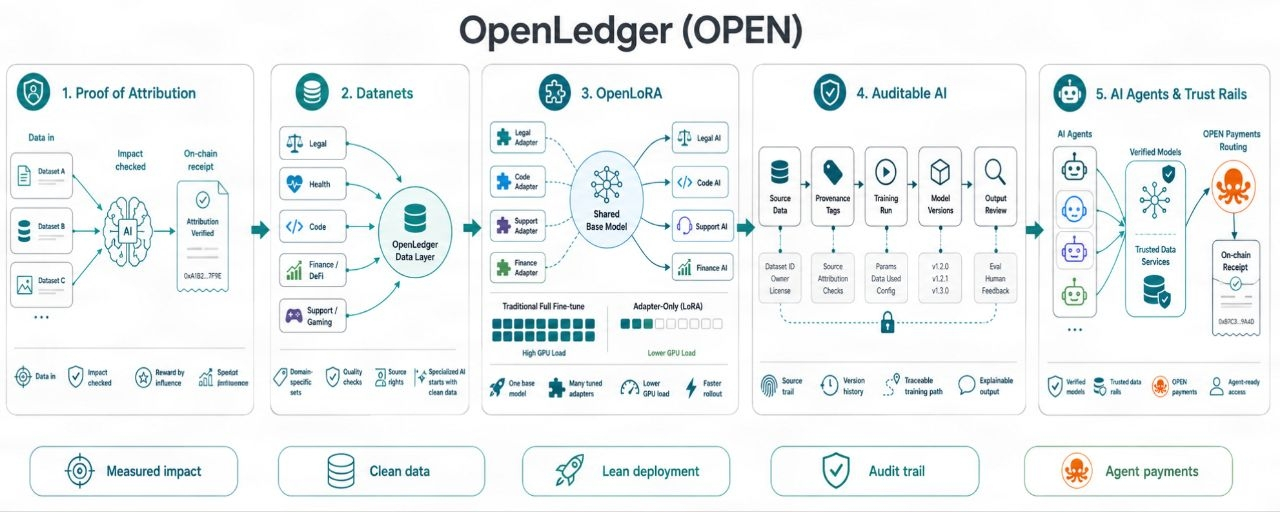
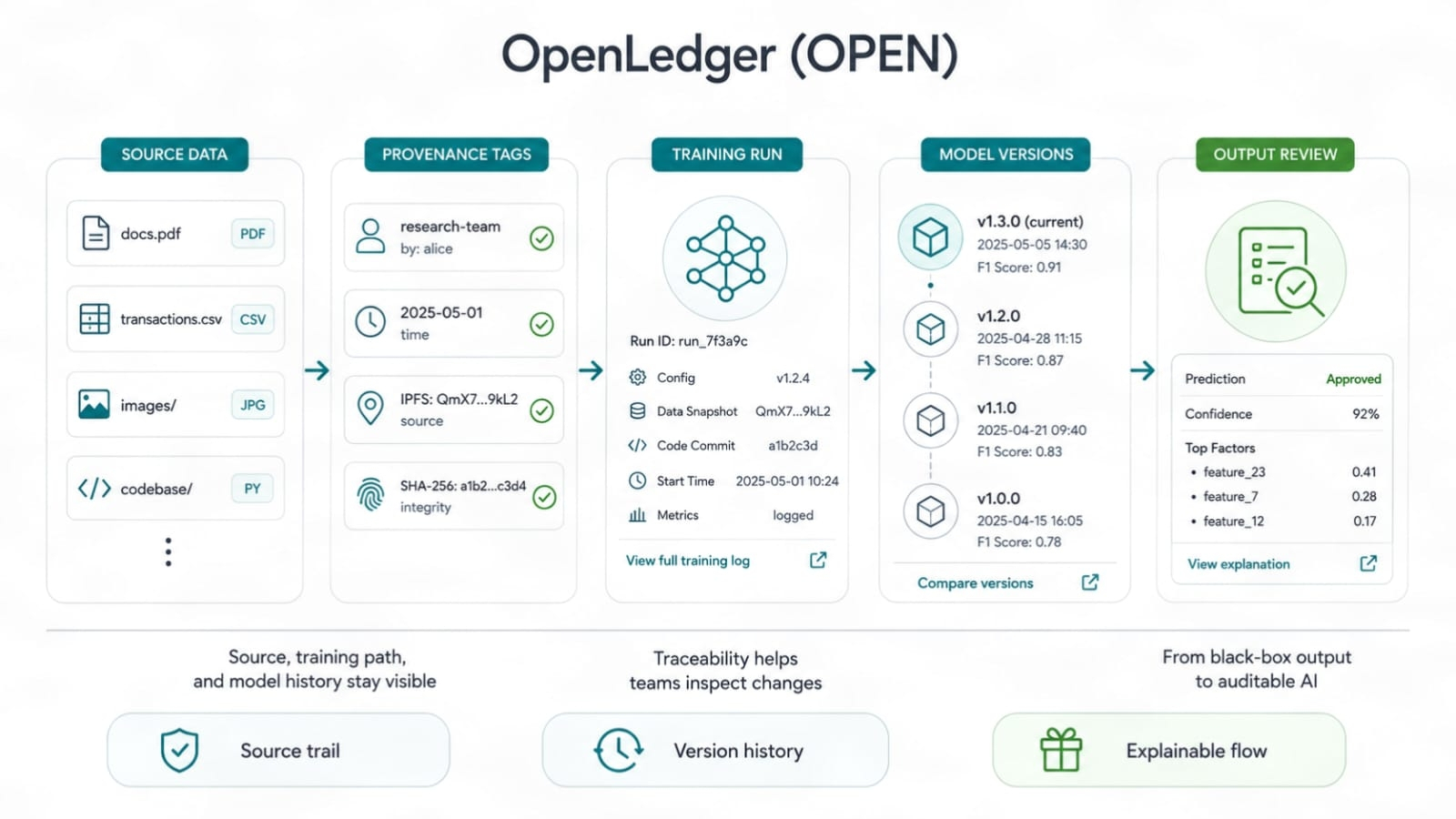
A Prova de Atribuição é útil porque muda o foco de "Eu participei" para "meus dados mudaram a qualidade da saída."
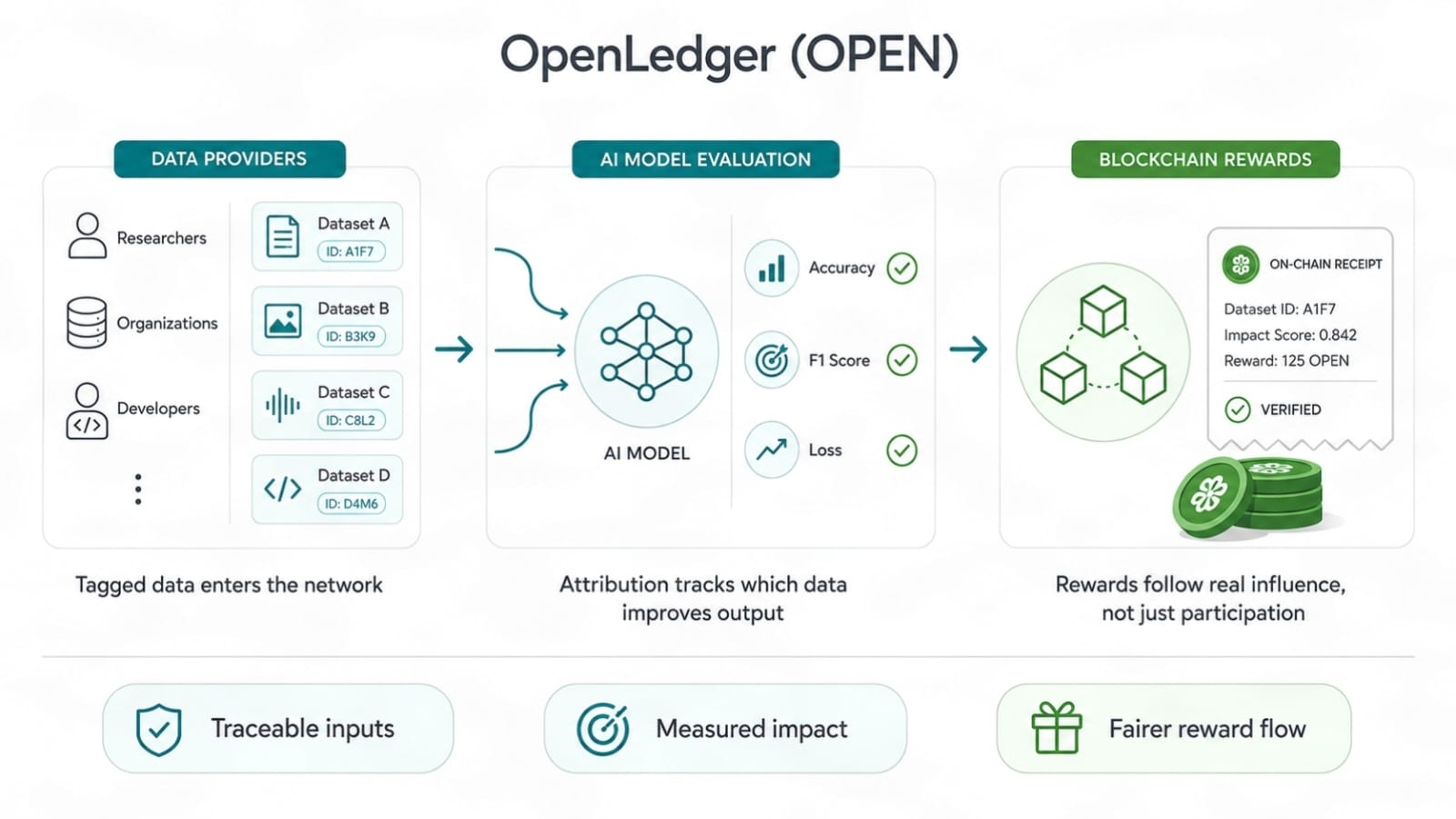
Isso soa pequeno. Não é. Os mercados de dados de IA têm muito peso de lixo. As pessoas podem despejar arquivos, raspar textos de baixa qualidade, renomeá-los e esperar que a escala esconda o valor fraco da fonte. Se as recompensas seguirem a entrada bruta, o spam vence. Se as recompensas seguirem o verdadeiro impulso, a qualidade tem um caminho.
Isso é difícil de fazer. Não vou disfarçar. A atribuição em IA não é um brinquedo matemático limpo. Os modelos aprendem de maneiras bagunçadas. Um conjunto de dados pode ajudar uma tarefa e prejudicar outra. Algumas entradas adicionam habilidades em casos extremos. Algumas apenas repetem o que o modelo já sabe. Portanto, a reivindicação do OpenLedger deve viver ou morrer com a eficácia de rastrear o impacto dos dados, direitos, uso de modelos e fluxo de recompensas. Documentação legal não será suficiente. Prova ao vivo será importante.
Os dados precisam de um rastro de recibos. Não um emblema falso. Não uma pontuação de vaidade. Um rastro que mostre de onde veio uma entrada de dados, como foi usada e qual papel desempenhou. É isso que os provedores de dados querem se forem sérios. Eles não querem ficar na multidão esperando por migalhas. Eles querem saber se seus dados tiveram impacto.
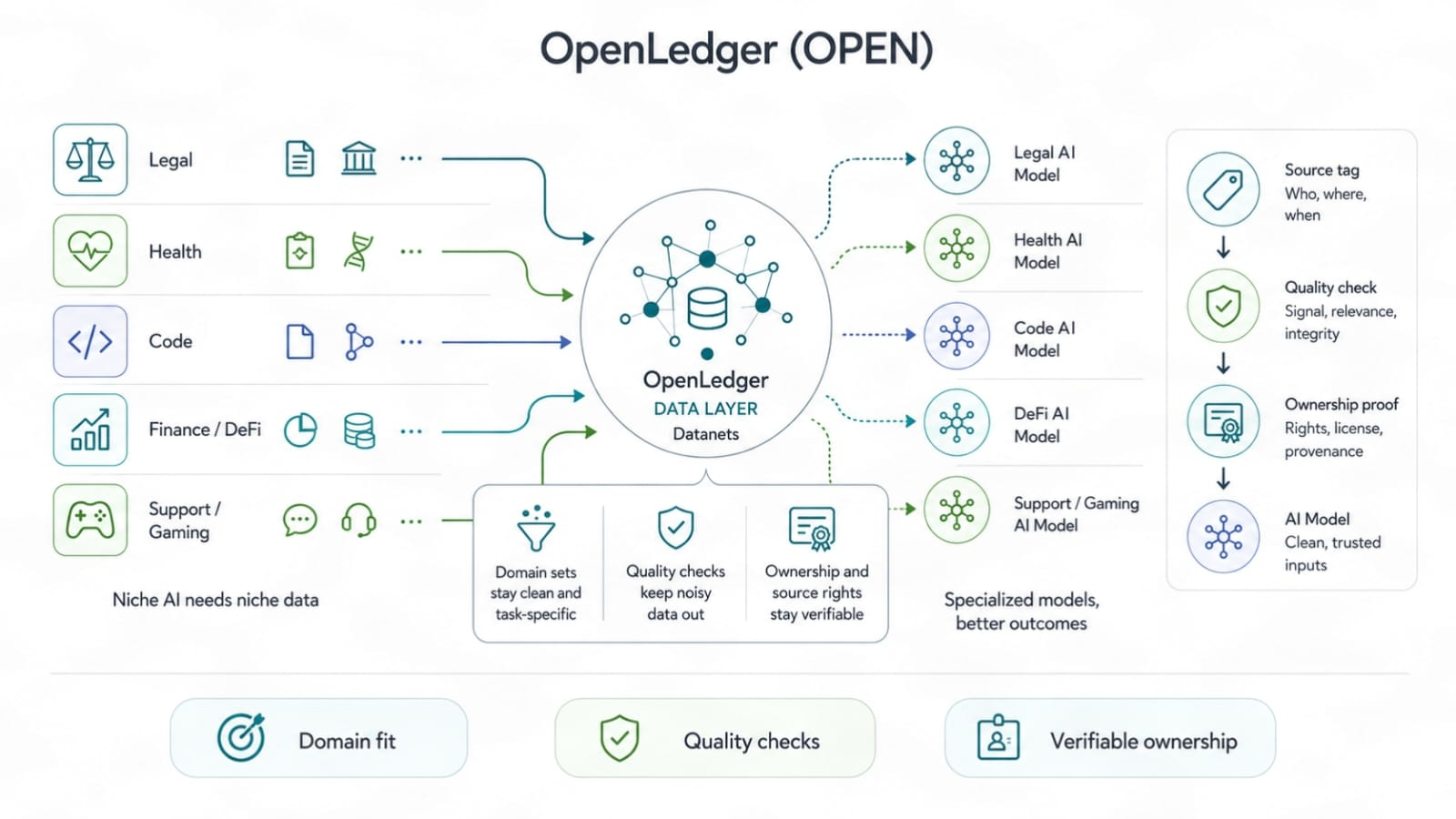
Os Datanets são onde isso começa a ficar mais real. Os dados amplos de IA têm limites. Você pode treinar um modelo geral em enormes pilhas de texto, claro. Mas quando você precisa de um modelo para direito, código, administração de saúde, ativos de jogos, risco de DeFi, estatísticas esportivas ou operações de suporte, dados amplos começam a parecer escassos. Dados de tarefa vencem. Dados limpos vencem. Dados próprios vencem.
O Datanet pode agir como uma sala de trabalho para um campo. Ele pode armazenar dados de origem, links de direitos, registros de uso e ajuste de tarefas. Isso é mais útil do que um grande balde onde todos os dados são misturados até ninguém saber de onde veio o que. Se o OpenLedger puder ajudar cada domínio a manter seu próprio rastro de dados, então os construtores de nicho terão uma base melhor para treinar. Não perfeito. Melhor.
Isso também dá aos pequenos proprietários de dados uma chance justa. A equipe pode não ter uma escala gigante, mas pode ter dados raros com alto valor de uso. Nos mercados antigos, o tamanho tende a esmagar a habilidade. Em mercados baseados em atribuição, um pequeno conjunto que melhora a saída do modelo pode importar mais do que uma enorme pilha que adiciona ruído. Essa é uma moldura mais saudável. Ela recompensa a verdadeira vantagem, não o volume alto.
O OpenLoRA se encaixa então em um segundo ponto de dor, o custo de implantação do modelo. Modelos finamente ajustados parecem ótimos até que o custo da GPU atinja. O trabalho completo do modelo pode consumir rapidamente o orçamento. Métodos no estilo LoRA ajudam porque adaptam um modelo base com mudanças mais leves. Você não precisa carregar um novo modelo completo toda vez. Você pode executar muitos caminhos ajustados com menos carga.
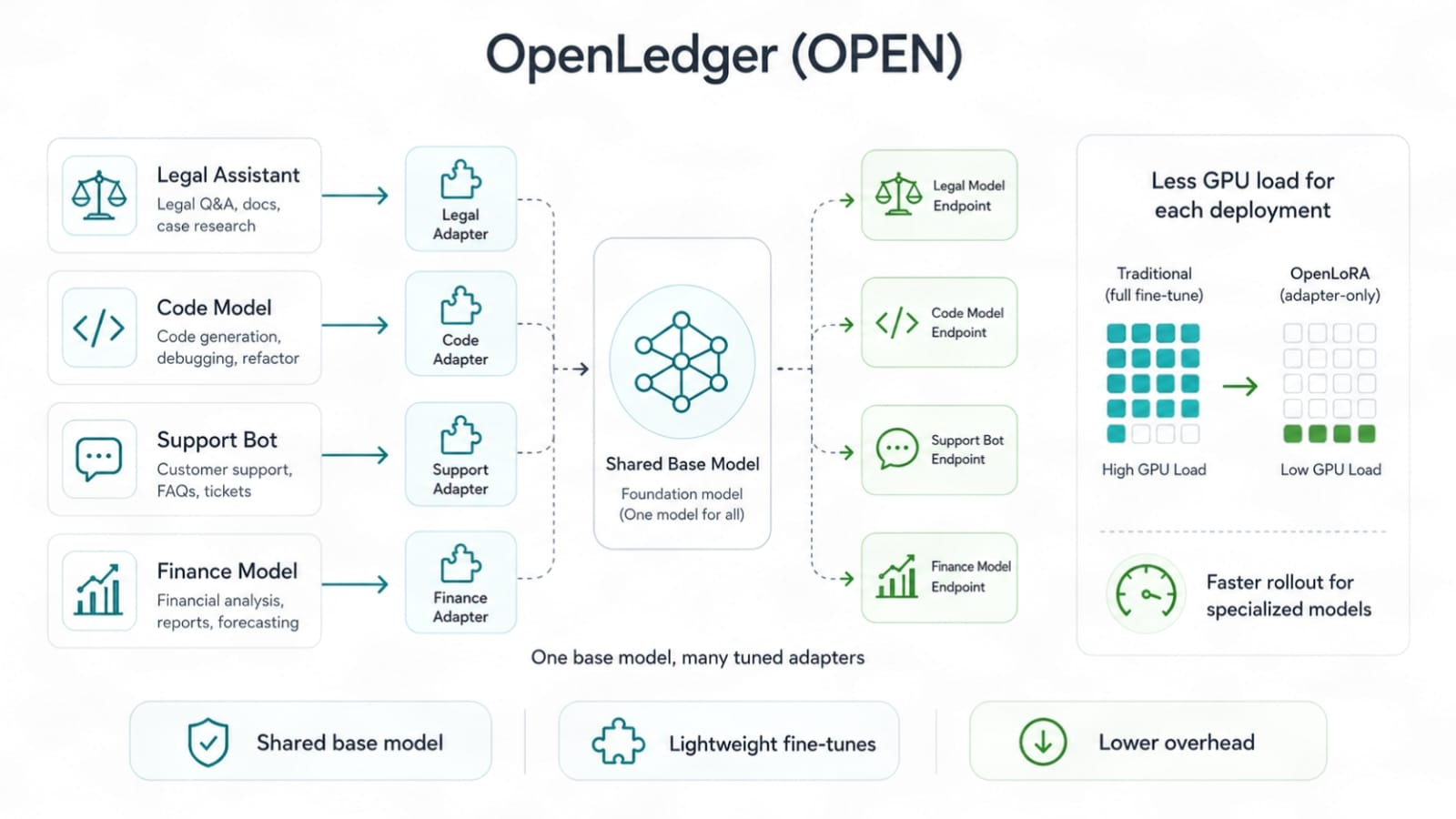
OpenLedger, OpenLoRA poderiam significar mais modelos de tarefa servidos com menos arrasto computacional. Isso importa porque o futuro da IA não será um único grande modelo fazendo todos os trabalhos bem. Provavelmente será muitos modelos focados, cada um ajustado para uma área específica. Um para pesquisa legal. Um para operações financeiras. Um para suporte de jogos. Um para checagens de dados em cadeia. Um para uso de ferramentas de agentes. Pequenos, afiados, baratos o suficiente para operar. Isso não é hype. É para onde muito trabalho de IA já aponta.
Mas cortes de custo não podem vir à custa da confiança. Um modelo barato que ninguém consegue rastrear é apenas um problema rápido. As equipes precisam do histórico do modelo. Quais dados foram usados? Qual versão mudou? Quem adicionou o que? Um novo conjunto de dados piorou as respostas? Um construtor pode reverter? Um proprietário de dados pode provar uso? Esses não são itens opcionais. Eles são como equipes reais mantêm o controle quando a IA entra nas operações diárias.
IA em caixa-preta ainda tem um cheiro fraco ao seu redor. Não porque a IA seja ruim, mas porque a confiança se quebra quando ninguém pode auditar um caminho. O rastro de auditoria do OpenLedger visa facilitar a inspeção do histórico de construção do modelo. A rastreabilidade e a prova de fonte parecem secas até que algo quebre. Então elas se tornam ferramentas essenciais. Qualquer um que tenha enviado sistemas reais sabe disso. Registros superam sensações.
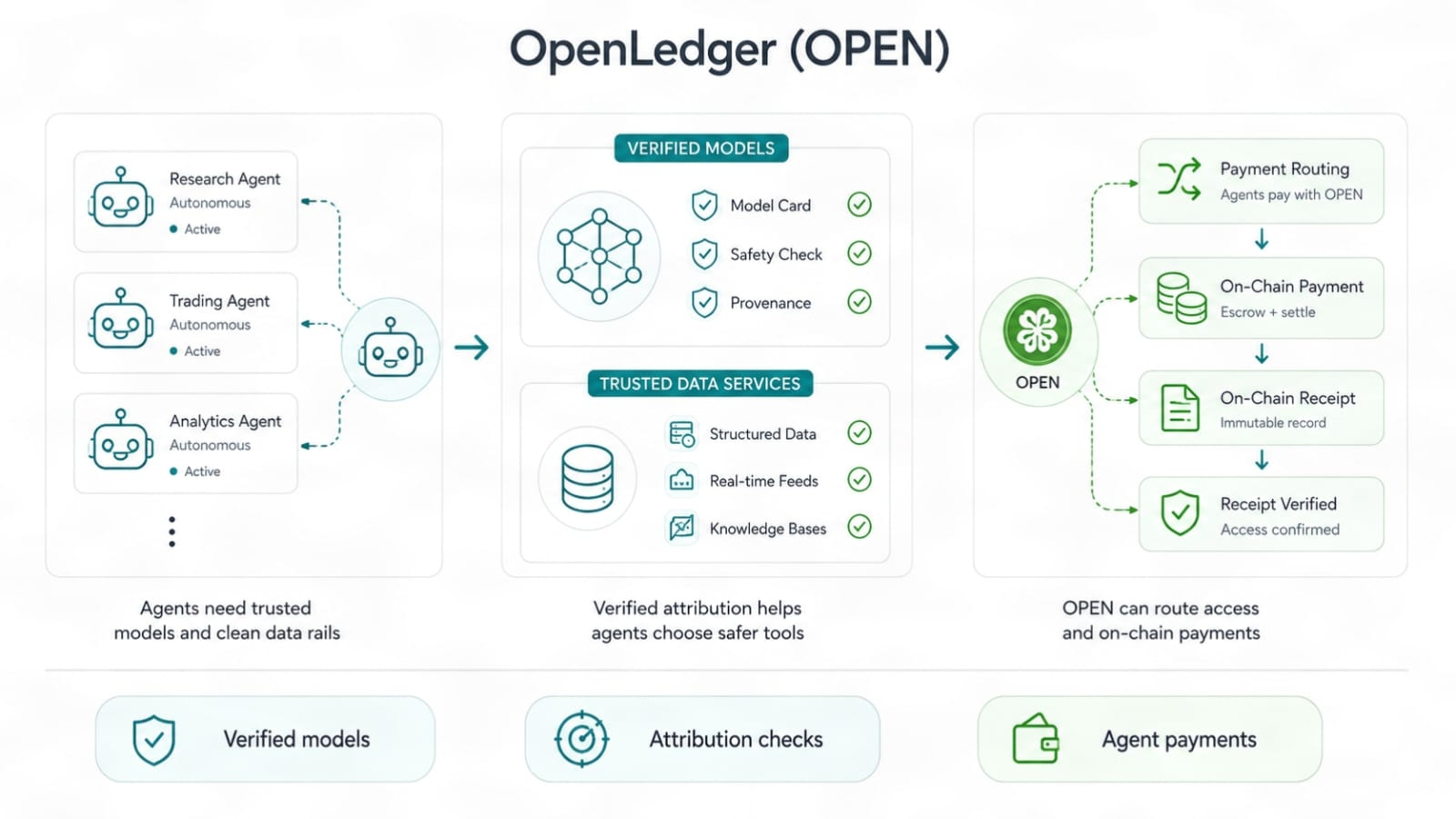
Os agentes de IA aumentam as apostas novamente. Os agentes não apenas respondem. Eles agem. Eles chamam modelos, usam dados, roteiam tarefas e podem pagar pelo acesso entre sistemas. Uma vez que os agentes começam a tomar mais decisões por conta própria, as trilhas de confiança são importantes. Um modelo com histórico de dados verificado é mais seguro para integrar ao fluxo do agente do que um com raízes desconhecidas. Uma camada de pagamento ligada ao OPEN poderia ajudar a roteirizar taxas e recompensas dentro dessa configuração, mas apenas se o uso for real e as regras permanecerem claras.
O OpenLedger aponta para uma necessidade real do mercado, recompensa justa por dados de IA úteis. A Prova de Atribuição não é sobre entregar tokens a qualquer um que apareça. É sobre vincular recompensa ao impacto. Os Datanets dão aos dados de domínio um lugar para provar seu valor. O OpenLoRA dá aos modelos ajustados um caminho de implantação leve. Ferramentas de auditoria trazem o histórico da fonte à vista. Pagamentos de agentes indicam um futuro trabalho de IA onde modelos, dados e tarefas se movem com menos arrasto humano.
DYOR, sempre. Leia a documentação. Acompanhe o uso. Observe como as recompensas funcionam em visão aberta. Verifique se a qualidade dos dados permanece alta quando os incentivos crescem. Verifique se o OPEN tem uma necessidade clara no fluxo de trabalho, não apenas um logotipo em cima. Um design limpo não é o mesmo que um ajuste de mercado sólido.
Não estou aqui para coroar nada. O crypto queimou muitas pessoas inteligentes que se apaixonaram por palavras bonitas. Mas eu realmente acho que o OpenLedger está fazendo uma das perguntas certas. Na Inteligência Artificial, o valor não virá apenas de possuir dados. Virá de provar quais dados ajudaram, quem os possuía, para onde foram e por que merecem uma parte. É aí que essa história tem importância.
