
Armazenamento não é um centro de custo, é o sistema de distribuição de valor do Bitroot AI Stack. Muitas equipes só percebem isso meses após o lançamento, que na verdade deveriam ter escolhido o nível de armazenamento com mais cautela desde o início. Os dados não foram perdidos, o serviço também não parou, mas o problema apareceu de outra forma: a recuperação dos dados de treinamento arquivados ficou cada vez mais lenta, a latência das consultas de vetores quentes saltou de milissegundos para segundos, e quando foi necessário revisar um incidente online, ninguém sabia qual versão dos dados de treinamento o modelo estava usando na hora. Neste ponto, o que precisa ser resolvido já não é a expansão, mas sim três problemas ainda mais complicados: quem pode provar que os dados sempre estiveram disponíveis, quem é responsável pela versão, e quem vai arcar com os custos a longo prazo.
Entenda o armazenamento como mover arquivos de uma nuvem centralizada para uma rede off-chain, que ainda pode suportar a era dos metadados NFT. Uma vez que os negócios se expandem para corpus de treinamento de IA, pesos de modelos e índices vetoriais, essa abordagem rapidamente se torna ineficaz.
A maioria das equipes ainda considera o armazenamento como um custo logístico que deve ser economizado, o que é precisamente o que mais subestima e mais fácil de errar: em uma blockchain de IA, ele é na verdade a camada que decide quem controla os dados e quem recebe os lucros. Este artigo responde a uma única pergunta: como construir uma solução de armazenamento distribuído que seja verificável, gerenciável e sustentável no cenário de fusão de IA e blockchain. A seguir, primeiro descreveremos as fronteiras de capacidade de três paradigmas principais, depois esclareceremos as dificuldades especiais dos dados de IA, e finalmente apresentaremos uma estrutura de cinco camadas e os limites de lançamento em fases. O critério de julgamento é baseado principalmente na documentação oficial do protocolo, tentando se basear em materiais verificáveis.
Tomando o Bitroot como exemplo, a camada de armazenamento é mais precisamente posicionada como a base de distribuição de valor da pilha de IA. O Bitroot, por um lado, fornece um ambiente de execução on-chain de alto desempenho através da EVM paralela e Pipeline BFT, e, por outro lado, conecta dados, modelos, poder computacional e aplicações de Agentes em uma rede gerenciável através de treinamento distribuído, rede de inferência, execução confiável e gerenciamento de ativos de IA. Nessa rede, o armazenamento não é um módulo isolado, mas a infraestrutura que determina se os dados podem ser certificados, se os modelos podem ser reproduzidos, se o poder computacional pode ser liquidado e se os contribuidores podem continuar recebendo lucros.

A totalidade na cadeia e a totalidade centralizada já não são viáveis em cenários de IA. Nos últimos anos, o problema de armazenamento frequentemente foi simplificado em uma escolha binária: ou tudo on-chain ou tudo centralizado. Nenhuma dessas duas abordagens é sustentável em cenários de IA.
A pressão para ir totalmente on-chain é muito específica. Dados de treinamento, pesos de modelos, logs de inferência e índices vetoriais geralmente são de grande volume e atualizações frequentes; mesmo que se comece fatiando antes de ir para a cadeia, isso ainda encontrará o teto de throughput e a curva de custo. Tudo centralizado é rápido, mas a verificabilidade, rastreabilidade, soberania de dados e a base de confiança necessária para colaboração entre entidades são frágeis; uma vez que envolvem múltiplas contabilidades e certificações, a abordagem não se sustenta.
A mudança mais crítica é que a IA transforma o armazenamento de um item de custo em um fator de produção. Quem gerencia a versão dos dados determina quem terá a iniciativa na iteração do modelo; a capacidade de provar que os dados estão disponíveis impacta diretamente o agendamento de poder computacional e a prioridade de liquidação; e a capacidade de capitalizar dados está relacionada à capacidade de uma equipe estabelecer incentivos a longo prazo dentro do ecossistema. A camada de armazenamento chegou a esse ponto e não é mais um sistema logístico, mas sim um sistema de distribuição de valor.
Portanto, uma arquitetura de armazenamento qualificada deve responder simultaneamente a quatro questões: os dados realmente existem e são continuamente acessíveis, a relação de versões entre dados e modelos é rastreável, as permissões e lucros são gerenciáveis, e o sistema pode equilibrar custos e desempenho a longo prazo.

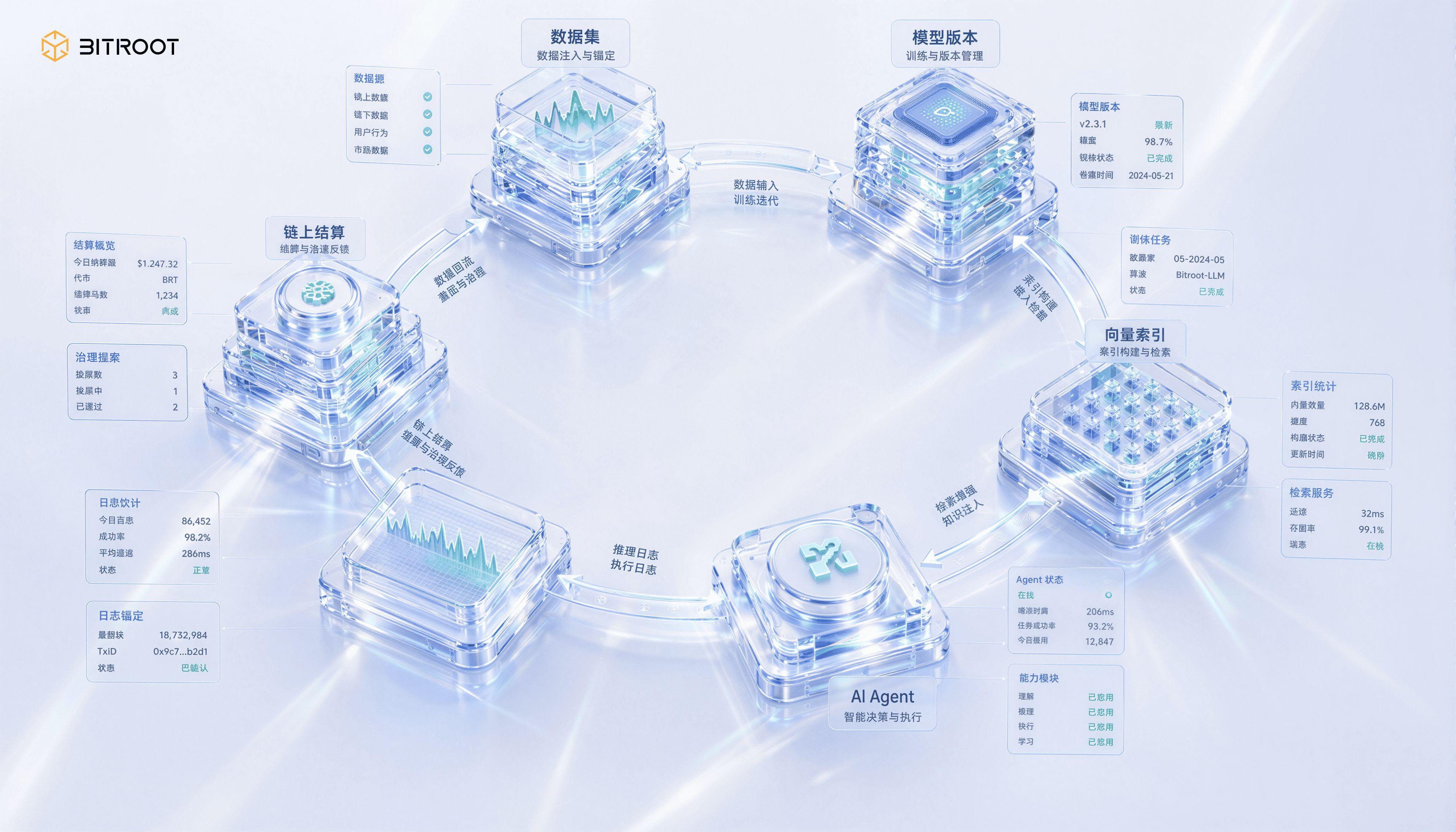
O ponto de entrada do Bitroot: transformar dados de IA de 'armazenáveis' em 'liquidáveis'.
Esse é precisamente o espaço que o Bitroot precisa preencher. Como uma blockchain pública de alto desempenho focada em cenários de IA, a narrativa de armazenamento do Bitroot não deve se limitar a 'onde os dados são armazenados', mas deve responder 'como os dados são provados, como são chamados e como participam da distribuição de lucros'. Dados de treinamento, pesos de modelos, índices vetoriais e logs de inferência podem ficar em camadas de armazenamento distribuído mais adequadas para grandes objetos, mas suas promessas de hash, relações de versão, políticas de permissão, registros de chamadas e eventos de lucros precisam formar uma evidência unificada on-chain no Bitroot.
Sob essa perspectiva, o alto throughput e a baixa latência do Bitroot não servem apenas para transações DeFi, mas para eventos de governança de granularidade mais fina e de alta frequência na pilha de IA: atualizações de conjuntos de dados precisam ser ancoradas, versões de modelos precisam ser registradas, chamadas de Agentes de IA precisam ser liquidadas, disputas sobre resultados de pesquisa precisam ser arbitradas, e a disponibilidade dos nós de armazenamento deve ser continuamente desafiada e recompensada. Somente se a cadeia de base puder suportar esses eventos, os ativos de dados de IA não estarão presos em bancos de dados centralizados, nem se tornarão caixas pretas off-chain sem responsabilidade.

Três paradigmas principais não conseguem sozinhos abranger todos os cenários. A competição no armazenamento distribuído nunca foi sobre quem é mais avançado, mas sim sobre quem se encaixa melhor na sua estrutura de dados.
A rede de endereçamento de conteúdo resolve se este ou aquele dado é o correto, não quem garante que está online. De acordo com a documentação oficial do IPFS, o CID é um identificador baseado em hash de conteúdo que não depende de endereçamento de localização: o mesmo conteúdo gera o mesmo CID sob as mesmas configurações de codificação e decodificação, e qualquer alteração de um único byte mudará o CID. Essa característica torna-o adequado para verificação de integridade, desduplicação e referência entre sistemas, sendo uma capacidade fundamental para certificação de dados. No entanto, endereçamento de conteúdo não é sinônimo de disponibilidade econômica persistente; o CID responde à questão de identidade, não à questão de quem garante que estará sempre online. Muitas equipes enfrentam o primeiro obstáculo após o lançamento: tecnicamente obtiveram o CID, mas não garantiram o compromisso de disponibilidade.
O mercado de armazenamento, por sua vez, compra a disponibilidade no tempo através de mecanismos econômicos. De acordo com a documentação do Filecoin, a rede estabelece um compromisso de armazenamento e prova contínua através de Proof-of-Replication e Proof-of-Spacetime. O PoRep prova que um setor específico armazenou uma cópia exclusiva no momento da embalagem inicial, enquanto o PoSt prova repetidamente que ele ainda está lá em ciclos subsequentes. O ciclo de prova do WindowPoSt geralmente é organizado a cada 24 horas, dividido em várias janelas de prova de 30 minutos; se o provedor de armazenamento não apresentar provas válidas dentro da janela, penalidades de garantia e redução da capacidade de armazenamento são acionadas. Nesse sistema, a disponibilidade é um item de avaliação contínua, não um compromisso único após a assinatura. Esse modo contratual e auditável é adequado para arquivamento de médio a longo prazo, backup e mercado de dados, mas se assemelha mais a armazenamento de longo prazo com prova do que a serviços online de baixa latência; se consultas online de alta frequência forem pressionadas diretamente, a experiência será arrastada pela latência final.
Redes de armazenamento permanente seguem um caminho diferente, trocando um pagamento único por uma história imutável. De acordo com o protocolo Arweave e dados da white paper, parte da taxa de upload vai para um fundo de doação de armazenamento, para cobrir incentivos de armazenamento a longo prazo, colocando a sustentabilidade a longo prazo na frente do modelo de cobrança, em vez de depender de hábitos de renovação. Isso é adequado para arquivamento histórico, registros críticos e materiais de direitos autorais. As desvantagens também são claras: a permanência não e automaticamente sinônimo de alta concorrência e baixa latência; na prática, ainda é necessário adicionar cache, gateways ou camadas de índice de linha para atender à experiência em tempo real do lado do usuário.
Além desses três paradigmas básicos, há duas combinações comuns que valem a pena considerar. Uma é a combinação de camada de disponibilidade de dados e armazenamento de objetos, onde a publicação de dados e a prova de disponibilidade tornam-se mais padronizadas, com o custo sendo a complexidade da colaboração entre camadas e os altos custos de governança de interfaces. A outra é a colaboração entre múltiplas nuvens e bordas, que melhora a latência e a recuperação de falhas, mas torna a governança de custos e a gestão de consistência mais desafiadoras.
Independentemente de como escolher, um protocolo que cobre todos os cenários não é viável em termos de engenharia. Uma abordagem eficaz é compor por tipo de dado: separar persistência, latência de pesquisa e conformidade, combinando cada uma com suas respectivas camadas de capacidade, e então orquestrar isso com a camada de ancoragem on-chain e governança.

A escolha do Bitroot também deve ser baseada nessa lógica de combinação: não se trata de substituir IPFS, Filecoin, Arweave ou armazenamento de objetos, mas de colocá-los em diferentes camadas de responsabilidade. Endereçamento de conteúdo é usado para identidade de dados e integridade, prova de armazenamento para disponibilidade a longo prazo, camada permanente para histórico crítico e comprovações, e camada de pesquisa quente para a experiência de aplicativos de IA; a camada on-chain do Bitroot deve unificar a ancoragem de versões, políticas de permissão, liquidações de chamadas e resolução de disputas. Em outras palavras, o Bitroot não precisa ser o depósito físico de todos os dados, mas deve ser o livro-razão confiável do fluxo de valor dos dados de IA.
As dificuldades do armazenamento de IA não estão em apenas armazenar arquivos, mas em gerenciar a cadeia de produção. Nos cenários de IA, os objetos de armazenamento podem ser pelo menos quatro categorias: dados de treinamento, pesos de modelos, índices vetoriais e logs de inferência. O ciclo de vida, o padrão de acesso e a densidade de valor de cada uma dessas quatro categorias são completamente diferentes; gerenciá-las com uma única estratégia pode ser conveniente a curto prazo, mas a longo prazo certamente levará a uma governança descontrolada.
O problema dos dados de treinamento não é a capacidade, mas a deriva de versão. Muitas equipes equiparam o problema dos dados de treinamento com custos de armazenamento em nível de TB, mas o que é realmente mais complicado é a deriva: assim que as regras de limpeza, os limites de seleção de amostras ou os critérios de rotulagem mudam, o comportamento do modelo também mudará. Sem o vínculo entre versão de dados e versão de modelo, a avaliação offline se torna difícil de reproduzir. Com base nas práticas de rastreamento de modelos e dados do MLflow, vincular a execução de treinamento à versão de dados é a premissa para reproduzir experimentos. Este princípio ainda se aplica na blockchain: os dados brutos não precisam ser totalmente on-chain, mas os compromissos de versão, resumos críticos e impressões digitais de origem devem ser ancorados na blockchain. Em termos de engenharia, pelo menos três identificadores devem ser vinculados: versão de dados, execução de treinamento e versão de modelo; se faltar um, a retroanálise de problemas online se degradará de verificar evidências para adivinhar razões.
O problema dos pesos de modelo muitas vezes não é se podem ser baixados, mas quem gerencia os limites de chamada. Um modelo que entra em produção geralmente passa por estados de graduação, principal, retrocesso e desativação; sem um sistema padronizado de registro e autorização, as chamadas online tornam-se uma caixa preta não auditável. Um centro de registro de modelos maduro registrará simultaneamente linhagem, apelidos de versão, restrições de assinatura e etiquetas de auditoria. Para sistemas on-chain, a versão do modelo não deve ser apenas um hash de arquivo, mas também deve estar vinculada a políticas de permissão, distribuição de lucros e limites de responsabilidade.
As dificuldades do índice vetorial estão concentradas em um lugar: a consistência após a separação entre quente e fria. A busca vetorial tem uma contradição inerente, onde baixa latência e baixo custo se opõem: a camada quente deve garantir respostas online com memória ou serviços de índice de alto desempenho, enquanto a camada fria deve controlar os custos de longo prazo com armazenamento de objetos. Sem metadados unificados e estratégias de sincronização, as duas camadas rapidamente se bifurcam, resultando em problemas com a mesma consulta retornando resultados semânticos diferentes em diferentes nós. Portanto, um sistema vetorial deve suportar duas coisas: o processo de construção do índice deve ser rastreável e a versão do índice na camada quente deve ser verificável com os dados principais da camada fria, que é exatamente o que a recuperação verificável deve resolver.
Logs de inferência precisam que privacidade, auditoria e conformidade coexistam, o que é desafiador. Eles são ao mesmo tempo material de auditoria de segurança e fonte de risco de privacidade: a retenção de texto completo traz riscos de conformidade, enquanto não reter nada resulta na perda de capacidade de revisão de acidentes. Uma abordagem viável é sobrepor três camadas: armazenar conteúdo desensibilizado, comprometer hashes na blockchain e exigir auditoria para acesso, realizando a não adulteração e o acesso revogável em camadas.
Na pilha de IA do Bitroot, essas quatro categorias de objetos podem corresponder a quatro ações de governança: dados de treinamento fazem ancoragem de versão e registro de origem, pesos de modelos fazem registro de ativos e chamadas autorizadas, índices vetoriais fazem separação de calor e frio e verificação de consistência, logs de inferência fazem armazenamento desensibilizado e compromisso de auditoria. Eles não precisam ser colocados on-chain da mesma maneira, mas todos precisam formar uma ID de ativo unificada, linhagem de versão e eventos de chamada no Bitroot. Assim, ativos de dados, ativos de modelos e aplicações de Agentes podem potencialmente formar um ciclo comercial reutilizável.

Verificável é o limite, a prova de disponibilidade é a linha de demarcação. Sem prova de disponibilidade, os compromissos de armazenamento, em um ambiente de produção, basicamente não valem nada. Para que o armazenamento distribuído entre em produção, deve pelo menos passar por três níveis: integridade verificável, disponibilidade verificável e comportamento auditável; uma vez que se entra no cenário de recuperação de IA, mais uma camada deve ser adicionada, a recuperação verificável.
A integridade pode ser provada com endereçamento de conteúdo e compromisso Merkle. O endereçamento de conteúdo garante a estabilidade da impressão digital dos dados, enquanto o compromisso Merkle garante a verificabilidade local. O significado de engenharia é que você pode verificar um subconjunto de um objeto com provas em nível de fragmento, sem precisar ler todo o volume de dados a cada vez. Para pesos de modelos grandes, grandes corpora e dados multimídia, isso determina diretamente o custo da verificação.
A disponibilidade pode ser comprovada com mecanismos de desafio e verificação de amostras. A prática do Filecoin já demonstrou que a disponibilidade não é um SLA verbal, mas um desafio periódico com provas on-chain, abstraindo como uma arquitetura genérica composta por três elementos: inspeção passiva, inspeções ativas e penalidades por falhas: os nós devem responder a desafios dentro de uma janela estipulada, caso contrário, penalidades ou redução de peso são acionadas. A mesma lógica se aplica à camada de disponibilidade de dados, de acordo com o design de amostragem de disponibilidade de dados do Celestia, os dados são expandidos de k×k para uma matriz de 2k×2k, onde nós leves, através de múltiplas amostragens aleatórias e acumulação de probabilidade, não precisam baixar dados completos para estabelecer alta confiança na disponibilidade. Isso oferece uma inspiração transferível para cenários de IA: diante de grandes objetos e acessos de alta concorrência, nem toda a disponibilidade precisa ser verificada por download completo, a confirmação estatística é mais realista em sistemas de grande escala.
A auditoria comportamental depende de ancoragem on-chain e registro de eventos. O que realmente é difícil de gerenciar em um sistema de armazenamento são os comportamentos: quem fez o upload de quê, quem alterou a estratégia, quem acionou a migração, quem chamou um modelo sensível e quando. Se esses comportamentos não se unirem em um fluxo de eventos unificado, em caso de disputa, tudo voltará a ser apenas palavras sem provas. O que a camada de governança precisa fazer não é colocar todos os detalhes na blockchain, mas ter em mãos, em caso de disputa, um conjunto mínimo, certo e verificável de evidências.
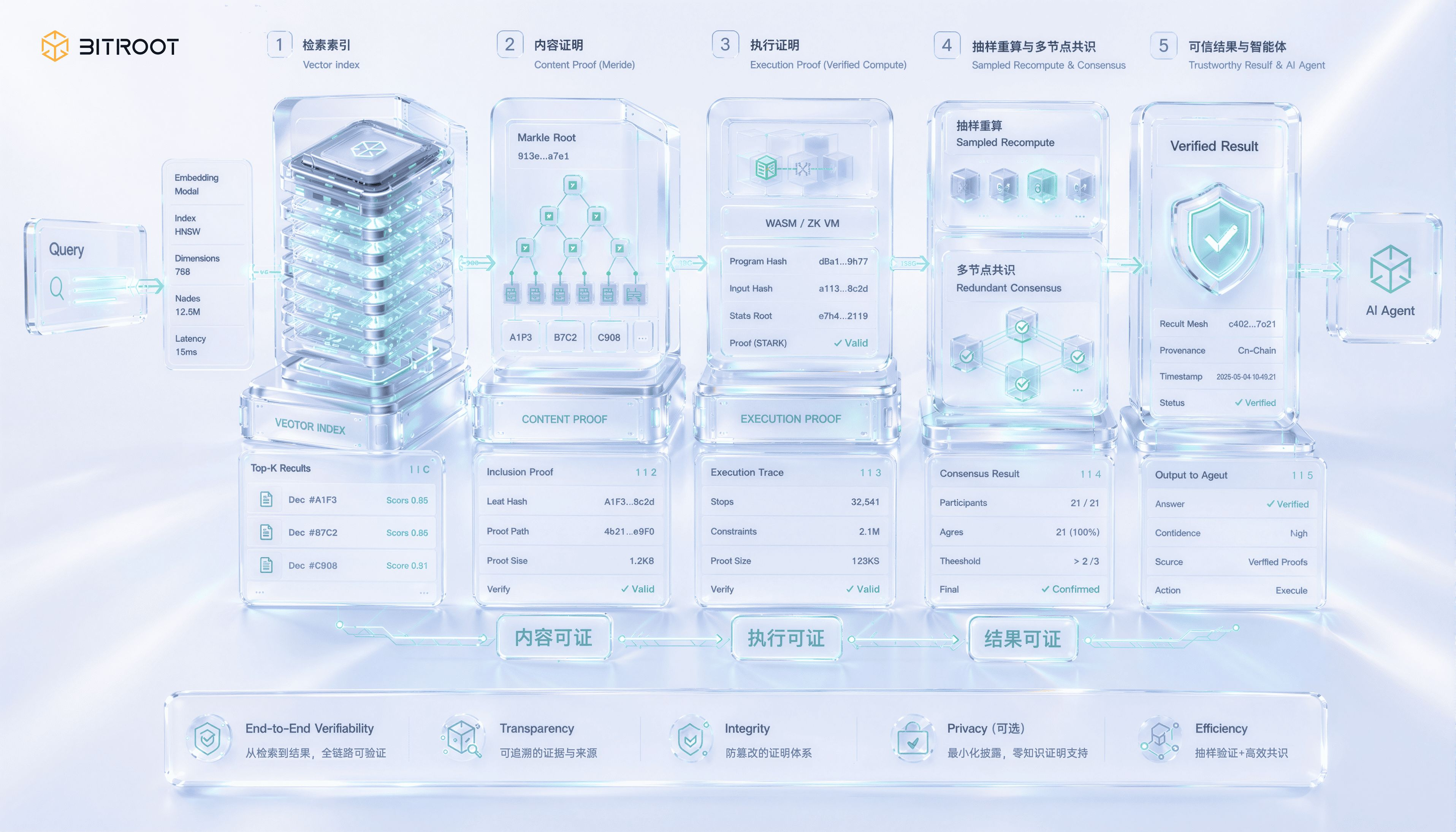
Recuperação verificável é a mais única e desafiadora no cenário de IA, o problema está em uma lacuna facilmente ignorada: retornar resultados não significa retornar resultados corretos. Um nó de pesquisa vetorial pode facilmente pegar um índice desatualizado ou até mesmo pular vizinhos realmente próximos, fornecendo um top-k que parece razoável, enquanto você não consegue distinguir apenas observando o valor retornado. A saída da pesquisa semântica não possui auto-prova; erros não geram mensagens de erro, apenas diminuem silenciosamente a qualidade de recall e o desempenho do modelo. Quando os resultados de pesquisa são usados para liquidação, autorização ou decisão on-chain, essa lacuna se transforma de um problema de qualidade em um problema de confiança.
Desmembrar a recuperação verificável é, na verdade, uma garantia em três camadas que se torna progressivamente mais desafiadora. A primeira camada é a prova de conteúdo, que garante que o vetor retornado pertence de fato a uma versão de índice prometida, a abordagem é construir uma estrutura de dados de autenticação para o índice, usar o compromisso Merkle para ancorar a raiz do índice na blockchain e, ao retornar resultados, incluir provas de inclusão, garantindo que o nó não fabricou ou trocou dados. A segunda camada é a prova de execução, que garante que esta consulta foi realmente executada na versão prometida, e não em uma versão alterada; isso requer que o processo de consulta esteja dentro do âmbito de computação verificável. A terceira camada, a mais desafiadora, é a prova de resultado, que garante que os top-k retornados são, de fato, os mais próximos sob a métrica dada, e não omitem vizinhos mais próximos; isso essencialmente requer que a correção da busca de vizinhos mais próximos seja provada.
Provar resultados rigorosos para vizinhos mais próximos em alta dimensão em uma escala de produção ainda é um desafio de ponta; métodos criptográficos como provas de conhecimento zero estão avançando, mas o custo da prova para operações vetoriais de alta dimensão ainda não está em um nível utilizável em grande escala online. A solução pragmática de engenharia é uma rede de camadas em vez de um único passo: primeiro, comprometer as versões do índice e os parâmetros de construção na cadeia, garantindo rastreabilidade; em seguida, fazer recontagens de amostras de consultas, extraindo proporcionalmente cópias confiáveis para reexecutar e comparar resultados, substituindo provas linha a linha por confiança estatística; ao mesmo tempo, permitir que vários nós independentes façam pesquisas redundantes e obtenham consenso sobre os resultados retornados, tornando o custo de fraude pontual mais alto; somente quando discrepâncias de comparação ou consenso ocorrerem, deve-se atualizar para recontagens completas de consultas contestadas e decisões on-chain. Esta abordagem está em linha com a prioridade de verificação de amostras na prova de disponibilidade: em sistemas de grande escala, confirmação estatística e escalonamento de disputas muitas vezes são mais viáveis do que provas rigorosas linha a linha.
Para o Bitroot, a recuperação verificável não é apenas uma função de armazenamento isolada, mas parte da execução confiável do Agente de IA. Um Agente on-chain que depende de bibliotecas de conhecimento externas, pesos de modelo ou índices vetoriais para tomar decisões, deve ser capaz de responder pelo menos três perguntas: qual versão de dado está sendo lida, qual versão de modelo está sendo chamada e se o resultado vem de uma versão de índice registrada. O Bitroot pode compactar essas evidências em eventos verificáveis on-chain, transformando o comportamento do Agente de 'parecer inteligente' para 'rastreável, contestável e liquidável'.

O verdadeiro problema na escolha é: não é sobre escolher um protocolo, mas sobre compor combinações. Muitas falhas em avaliações de soluções ocorrem porque a pergunta é formulada incorretamente. A maneira correta de formular não é se devemos usar um determinado protocolo, mas qual é a nossa combinação de dados, quais são nossos objetivos e quais são nossas condições restritivas. Sugiro seguir quatro ações.
Primeiro, faça um inventário dos ativos de dados. Pelo menos, classifique dados de estado, dados de objeto, dados de pesquisa e dados de auditoria, e faça o modelo de inventário com campos fixos, no mínimo oito: tipo de dado, incremento diário, pico de concorrência, razão de leitura/gravação, ciclo de retenção, nível de conformidade, latência alvo, limite de custo. Uma vez que os campos sejam unificados, a comunicação para seleção entre equipes será muito mais rápida.
Redefina as metas de nível de serviço. Defina claramente os limites de P95/P99, tempo de recuperação RTO, ponto de recuperação RPO, metas de disponibilidade e limites de custo por TB, caso contrário, todas as discussões subsequentes não terão um referencial.
Em seguida, estabeleça o mapeamento de capacidades. Diferentes capacidades como armazenamento permanente, provas periódicas de disponibilidade, pesquisas de baixa latência e governança de acesso devem ser mapeadas para diferentes camadas de tecnologia, em vez de esperar que uma única camada cubra tudo.
Finalmente, determine os limites de migração. Quais dados são permitidos para gerenciamento centralizado durante o período de transição, quais métricas acionam a migração e quando deve ser concluída a substituição descentralizada. Uma prática útil é pré-definir limites duplos: se o custo por TB ultrapassar o orçamento por dois ciclos estatísticos consecutivos, ou se a latência P95 ultrapassar a meta por duas semanas consecutivas, a revisão da arquitetura de migração é acionada automaticamente. Sem limites, não há governança, e o período de transição se tornará um estado permanente.
Solução prática: estrutura de cinco camadas, unindo o que pode ser armazenado, retirado e gerido em um ciclo. O valor da arquitetura não está na quantidade de camadas, mas na capacidade de formar um ciclo verificável. Com base no quadro anterior, a solução se concentra em cinco camadas: camada de ancoragem on-chain, camada de armazenamento de objetos, camada de pesquisa de índice, camada de prova de disponibilidade e camada de controle de chave.
Dentro do Bitroot, essas cinco camadas podem ser entendidas como um módulo de governança de armazenamento para uma pilha de IA: EVM Paralela fornece ancoragem e capacidade de liquidação de alta frequência, Pipeline BFT oferece determinismo de baixa latência, a rede de armazenamento distribuído suporta grandes objetos e dados históricos, a camada de pesquisa de índice serve Agentes de IA e chamadas de aplicativos, a camada de prova de disponibilidade transforma a qualidade do serviço dos nós em reputação e recompensas, enquanto a camada de controle de chave conecta a soberania do usuário, proteção de privacidade e autorização comercial do modelo.
A camada de ancoragem on-chain armazena apenas o estado mínimo necessário: compromissos de dados, impressões digitais de versão, resumos de políticas de permissão e eventos de liquidação. Grandes objetos não são armazenados na blockchain; o que é armazenado são os comprovantes de que esse objeto existe e sua versão está correta. Isso mantém a verificabilidade on-chain sem deixar que o throughput seja arrastado por grandes arquivos.
No contexto da arquitetura do Bitroot, a camada de ancoragem on-chain não é apenas um lugar para 'registrar hashes', mas a entrada comum para registro de ativos de IA, governança de permissões, distribuição de lucros e resolução de disputas. Conjuntos de dados, pesos de modelos, índices vetoriais e logs de inferência podem ser armazenados off-chain da maneira mais adequada, mas seus compromissos de versão, estados de autorização, registros de chamadas e eventos de lucros precisam entrar no estado on-chain do Bitroot. Assim, o armazenamento off-chain é responsável por suportar volumes, enquanto o Bitroot é responsável por suportar a confiança.
A camada de armazenamento de objetos suporta dados reais, adotando uma estratégia híbrida de códigos de correção e cópias: objetos de alto valor e baixo acesso priorizam tolerância a falhas, enquanto objetos de médio valor e alto acesso priorizam eficiência de pesquisa. Essa estratégia não é uma configuração estática; deve ser ajustada dinamicamente de acordo com a frequência de acesso e a classificação do negócio.
A camada de pesquisa de índice inclui índices de metadados e índices vetoriais em um diretório unificado, com a camada quente lidando com pesquisas online e a camada fria gerenciando arquivamento e reconstrução. Todas as versões de índice devem registrar a versão dos dados de origem e os parâmetros de construção, caso contrário, a deriva do índice não poderá ser responsabilizada.
A camada de prova de disponibilidade quantifica o comportamento dos nós. A taxa de sucesso em responder a desafios, o tempo de resposta, a taxa de recuperação bem-sucedida entram na pontuação de reputação, que é vinculada à distribuição de recompensas, evitando que apenas a capacidade seja recompensada, sem recompensar a disponibilidade.
O controle de acesso e conformidade do nível de chave. Dados altamente sensíveis são geridos com chaves hierárquicas e autorizações temporais, logs de inferência usam armazenamento desensibilizado e replay de auditoria, chamadas de modelo utilizam permissões revogáveis. As próprias operações de permissão também devem deixar rastros para evitar deriva de configuração.
Essas cinco camadas formam um ciclo na execução, não uma linha de fluxo unidirecional: após a entrada de dados, primeiro fatiar e codificar na camada de objetos, depois escrever e gerar índices ancorados na blockchain; consultas online vão pela camada quente, e se a taxa de acerto for insatisfatória, voltam para a camada fria; ao retornar os resultados, a verificação de integridade e de permissões é acionada, e comportamentos críticos entram na liquidação e auditoria. O verdadeiro valor dessa cadeia de processos é que qualquer nó, a qualquer momento, pode responder a quatro perguntas: de onde vêm os dados, qual é a versão atual, quem tem permissão para acessar, e o sistema pode provar que é utilizável.
Essa também é a razão-chave pela qual o Bitroot é adequado para gerenciar a governança de armazenamento de IA. As chamadas dos Agentes de IA, as mudanças nas versões dos modelos, as alterações nas autorizações de dados e as disputas nos resultados de pesquisa não são operações de fundo de baixa frequência, mas eventos on-chain que ocorrerão continuamente com o crescimento das aplicações. Se a cadeia subjacente não puder fornecer confirmação suficientemente baixa e throughput suficientemente alto, a governança de armazenamento será forçada a voltar para tabelas off-chain e reconciliação manual. A combinação de EVM Paralela e Pipeline BFT do Bitroot não traz apenas TPS mais alto, mas permite que esses eventos de governança de alta frequência sejam ancorados, liquidadas e responsabilizados em tempo real.

Quem pagará a conta: fazer com que a disponibilidade, e não a capacidade, decida a receita. Para que o armazenamento funcione a longo prazo, os incentivos devem estar alinhados com a disponibilidade, em vez de acumular capacidade. Recompensar apenas a capacidade equivale a incentivar nós a acumular discos rígidos, mas oferecer serviços leves. O Filecoin já corrigiu isso em seu mecanismo: introduziu o conceito de poder ajustado pela qualidade, onde setores que suportam pedidos de armazenamento reais, especialmente aqueles que têm pedidos válidos, obtêm mais peso na medição de poder, inclinando as recompensas para a capacidade que realmente oferece serviço, e não para a capacidade vazia encapsulada. Essa abordagem vale a pena para qualquer camada de incentivo autoconstruída.
Para torná-lo um função de recompensa executável, é necessário considerar quatro dimensões ao mesmo tempo e esclarecer a lógica de peso de cada uma. A capacidade determina a parte básica, respondendo ao espaço prometido. A taxa de online e o tempo de resposta determinam o coeficiente de qualidade do serviço, respondendo se esse espaço é realmente acessível quando necessário, e esse item deve ter um peso alto; caso contrário, a disponibilidade se tornará um slogan. A taxa de sucesso na recuperação de dados determina a confiabilidade da recuperação, respondendo se cópias podem ser reconstruídas após a falha de um nó, o que está diretamente relacionado à sobrevivência dos dados de cauda longa. A densidade de valor dos dados determina o acréscimo do lado da demanda, configurando multiplicadores diferenciados para conjuntos de dados de alto valor e modelos de alta demanda, garantindo que dados escassos e frequentemente chamados recebam retornos mais altos. As recompensas devem ser destinadas a serviços que podem ser comprovados, e não à capacidade declarada.
Apenas ter incentivos positivos não é suficiente; as restrições de garantia, penalidades e arbitragem também devem estar em vigor, e devem atender a uma desigualdade subjacente: o ganho esperado da fraude deve ser inferior ao custo esperado da penalidade, caso contrário, qualquer mecanismo de prova será contornado pela racionalidade econômica. A garantia faz com que os nós coloquem seu custo em jogo pelo compromisso de disponibilidade, e a escala de garantias deve ser proporcional ao poder computacional que prometeram e ao valor dos dados; no design do Filecoin, os provedores de armazenamento devem pagar garantias antecipadas de acordo com o poder prometido; se falharem na janela de prova, isso aciona uma taxa de falha, e se o setor for abandonado permanentemente, isso acionará uma penalidade mais severa. O significado desse sistema de penalidades em camadas é distinguir entre quedas de curto prazo e saídas maliciosas. A arbitragem usa evidências on-chain para impulsionar a resolução de disputas: quando um usuário reclama que os dados não estão disponíveis e o nó afirma que está servindo normalmente, os registros de desafio, provas de amostra e logs de eventos constituem a base de decisão legível por máquina, comprimindo disputas que antes necessitavam de intervenção manual em um julgamento on-chain verificável.
O cenário de IA também precisa sobrepor uma camada ainda mais difícil de governança: como dividir o lucro entre três partes. Um modelo que é repetidamente chamado é sustentado por contribuidores de dados que fornecem o corpus, contribuidores de modelos que investem no treinamento e nós de armazenamento que fazem a hospedagem; todos têm contribuições para o valor da chamada final, mas a contribuição é difícil de observar diretamente. Uma abordagem viável é construir a atribuição de valor em eventos on-chain que possam ser medidos: a chamada é cobrada por uso e liquidada automaticamente, dados e modelos são vinculados a cada chamada por impressões digitais de versão e relações de linhagem, e então divididos automaticamente segundo proporções de contabilidade programável previamente definidas, evitando disputas posteriores. Um sistema de blacklist e penalidades para comportamentos como upload de dados maliciosos, violação de direitos autorais e roubo de modelos, uma vez reconhecido e arbitrado, resulta em apreensão de garantias e congelamento de lucros subsequentes. Caso contrário, ocorrerá um resultado contra-intuitivo: quanto mais bem-sucedida a capitalização, mais disputas de divisão e certificação surgirão, minando a própria confiança do ecossistema.
A conformidade não é um remendo pós-lançamento, mas uma restrição durante a fase de arquitetura: a linha de base de segurança é criptografia de ponta a ponta, gerenciamento de chaves em camadas e rotação periódica, além de verificação de hash e compromisso Merkle para garantir que os downloads sejam verificáveis, usando múltiplas cópias e códigos de correção para cobertura de recuperação de falhas; o lado de privacidade deve implementar controle de acesso de menor privilégio com base no nível de dados, suportando autorizações revogáveis, autorizações de uso único e autorizações temporais, enquanto o acesso e operações críticas devem deixar rastros em toda a cadeia, facilitando a reprodução de auditoria. A conformidade também é a parte mais fácil de ser postergada e a mais cara: políticas de localização de dados e de transferência entre domínios devem ser configuráveis, e os pedidos de exclusão, acesso e auditoria devem ter interfaces de processo padrão; a parte mais complicada é o conflito natural entre não adulteração e exclusão. A solução viável é a exclusão criptográfica combinada com a invalidação de índices: destruir chaves torna os dados criptografados irrecuperáveis, enquanto a invalidação de índices torna os dados não recuperáveis, mantendo um registro na blockchain, mas atendendo à demanda de exclusão. Existem três limites de fase de produção: primeiro, estabelecer um ciclo mínimo confiável, estabilizando o armazenamento de objetos, ancoragem on-chain, verificação de integridade e monitoramento básico, aceitando a verificação com base em disponibilidade, taxa de sucesso de leitura e gravação, consistência de ancoragem e versão de objeto, e recuperação de falhas que pode ser praticada; em seguida, fazer a capitalização de ativos de IA e governança de índices, introduzindo gerenciamento de conjuntos de dados e ativos de modelo, linhagens de versão, separação de calor e frio para índices, chamadas de autorização de modelos e registro de origem de dados de treinamento, aceitando a rastreabilidade de treinamento, a auditoria e reversibilidade do modelo, a latência da camada quente e o impacto da reconstrução do índice; finalmente, introduzir recuperação verificável e governança automatizada, com provas de desafio, migração de políticas e automação de recompensas e penalidades, aceitando a cobertura de provas de disponibilidade, tempo de resposta para mitigação de riscos, redução de custo unitário e rastreabilidade e reversibilidade nas mudanças de política. O sistema de métricas deve ser um sistema de políticas, e não apenas relatórios de exibição. Se apenas itens técnicos forem escritos, sem resultados de negócios, o plano de armazenamento se tornará um centro de custo puro; sugiro dividir em três camadas: métricas técnicas básicas (disponibilidade, latência P95/P99, throughput, RTO/RPO, taxa de erro) que respondem se o sistema está saudável, métricas específicas de IA (taxa de rastreabilidade de dados de treinamento, taxa de reprodutibilidade de modelos, cobertura de validação de inferências, consistência de índices) que respondem se a qualidade do modelo pode ser gerida, e métricas de resultados de negócios (crescimento da oferta de dados, redução de custo de chamada, atividade de nós, escala de transações de ativos) que respondem se o sistema está criando valor, com mapeamento entre as três camadas. O verdadeiro propósito das métricas é servir como entrada para a otimização de políticas, e não apenas relatórios de exibição. Os cinco pontos de falha mais comuns podem ser evitados antecipadamente: apenas fazer armazenamento sem gerenciar versões, dados em não representam disponibilidade, disponibilidade não significa reprodutibilidade; apenas olhar para capacidade sem verificar provas de disponibilidade, recompensar com base na capacidade levará a incentivar o armazenamento de capacidade com serviços leves; fazer separação quente e fria, mas não ter estratégia de sincronização, a sincronização de versões de índice e o tratamento de falhas não estão em ciclo; políticas de conformidade postergadas, permissões, logs, desensibilização e respostas a exclusões, quanto mais tarde forem corrigidas, maior será o custo; arquiteturas de transição sem mecanismo de saída, primeiro centralizar e depois descentralizar é um caminho razoável, mas a falta de um limite de migração pode solidificar o estado de transição, desviando-se do objetivo inicial.
O ciclo completo do Bitroot: desde dados, modelos até Agentes de IA. Dentro desse ciclo, o Bitroot pode transformar cada ação crítica dos ativos de IA em eventos liquidáveis: registro de conjuntos de dados, lançamento de versões de modelos, reconstrução de índices vetoriais, chamadas de Agentes de IA, ancoragem de logs de inferência, autorizações e revogações de permissões, desafios de disputas e resultados de arbitragem. A cadeia não precisa suportar todos os dados, mas deve suportar as evidências mínimas dessas ações. Somente assim, a relação de valor entre dados, modelos, poder computacional e aplicações não ficará apenas em promessas verbais, mas entrará em contabilidade programável e governança auditável.
Colocar esse mecanismo na operação e expansão ecológica do Bitroot, os incentivos de armazenamento não devem ser desenhados como subsídios de hardware separados, mas sim como parte do fluxo de valor da pilha de IA: contribuidores de dados recebem lucros quando seus dados são usados para treinamento ou chamadas, contribuidores de modelos recebem lucros por serviços de modelos, e nós de armazenamento e recuperação recebem lucros por serviços de disponibilidade contínua e baixa latência, enquanto nós de verificação e desafio recebem recompensas por descobrir problemas de disponibilidade, deriva de índices ou anomalias de permissões. Dessa forma, o sistema econômico do Bitroot recompensa não o ato de 'subir dados', mas sim o que é 'continuamente provadamente útil'.
O armazenamento não é um centro de custo, mas um sistema de confiança e distribuição de valor. O armazenamento distribuído na era da IA deve resolver não apenas a substituição de um produto de armazenamento de objetos, nem buscar uma narrativa descentralizada, mas quatro questões mais desafiadoras: provas confiáveis de disponibilidade a longo prazo, ordem de governança para colaboração entre entidades, cadeia de responsabilidades entre dados e modelos, e incentivos econômicos sustentáveis.
Uma arquitetura de protocolo único em uma única camada não pode cobrir esses objetivos. Um caminho mais realista é uma arquitetura combinada: endereçamento de conteúdo para garantir integridade, prova de armazenamento para garantir a disponibilidade no tempo, camada permanente para garantir histórico crítico, camada quente para garantir experiência online, e ancoragem on-chain para garantir governança e liquidação verificável. Isso não é um compromisso, mas sim racionalidade de engenharia. O foco na implementação não deve ser ter a funcionalidade mais completa, mas ter o ciclo fechando primeiro, começando com o ciclo de confiança mínimo, e então sobrepondo a capitalização de ativos de IA, recuperação verificável e governança automatizada camada por camada.
Comprimir esse método em uma semana de ação envolve apenas três passos: no primeiro dia, completar uma tabela de inventário de dados com oito campos, no terceiro dia, executar uma vez um fluxo mínimo de entrada, armazenamento, recuperação e verificação em um domínio de negócios real, e no sétimo dia, realizar uma revisão do limite de migração com base na latência P95 e no custo unitário. Cumprindo essas três etapas, a equipe passará de um consenso conceitual para um consenso de engenharia.
Deve-se também reconhecer um limite de realidade: independentemente do protocolo combinado, há trocas entre custo, latência e persistência; não existe uma única resposta que seja ideal para todos os negócios ao mesmo tempo. A verdadeira solução sustentável vem de iterações contínuas sob limites claros, e não de configurações estáticas a longo prazo após uma decisão única.
O que frequentemente elimina um projeto no futuro não é a TPS insuficiente, mas sim a incapacidade de esclarecer a cadeia de responsabilidades de dados; na era das blockchains de IA, o armazenamento não é apenas sobre colocar dados, mas sobre garantir que os dados possam ser provados a qualquer momento.
Conclusão
A verdadeira competição entre blockchains de IA, no final, não se limitará a comparações de TPS, Gas ou tempo de confirmação. O desempenho é a porta de entrada, mas não é o fim. Entrando na era das aplicações nativas de IA, os sistemas on-chain não devem apenas suportar transações, mas também versões de dados, chamadas de modelos, agendamento de poder computacional, registros de inferência, comportamentos de Agentes e distribuição de lucros entre múltiplos.
Essa também é a avaliação do Bitroot sobre a camada de armazenamento: armazenamento não é um módulo acessório, mas a camada mais próxima da fonte de valor na pilha de IA. A capacidade de provar que os dados podem ser provados, que os modelos podem ser reproduzidos, que as chamadas podem ser auditadas e que os lucros podem ser distribuídos automaticamente determina se uma rede de IA descentralizada realmente possui vitalidade a longo prazo.
O que o Bitroot quer construir não é uma cadeia que apenas busca uma execução mais rápida, mas uma infraestrutura que permita que os ativos de IA sejam confirmados, chamados, liquidadas e geridas. A EVM Paralela e o Pipeline BFT resolvem a capacidade de suporte a eventos on-chain de alta frequência, enquanto o armazenamento distribuído e os mecanismos verificáveis resolvem a base de confiança para dados e modelos de IA, e a contabilidade programável e a governança on-chain transformam as contribuições em incentivos econômicos sustentáveis.
Quando o Agente de IA começa a agir em nome do usuário, quando modelos e dados começam a se tornar ativos negociáveis, quando poder computacional, armazenamento e serviços de inferência entram na mesma rede de valor, o armazenamento deixa de ser uma questão de 'onde colocar arquivos'.
Isso se tornará a base de confiança da blockchain de IA e o sistema de distribuição de valor da próxima geração de redes inteligentes.
Para o Bitroot, o que realmente importa no futuro não é quem possui mais dados, mas quem pode fazer com que os dados sejam prováveis, chamáveis e responsabilizáveis a qualquer momento, e finalmente participar da liquidação de valor.
Sobre o Bitroot: O Bitroot é um projeto de blockchain público Layer 1 focado em execução paralela e arquitetura nativa de IA. O Bitroot adota uma rota tecnológica compatível com EVM e, através de mecanismos de execução paralela, otimização de consenso e design de interfaces relacionadas à IA, explora proporcionar um ambiente de execução on-chain de alto desempenho e baixo custo para Agentes de IA, DeFi e aplicações Web3.
Junte-se a nós:
Site oficial: https://bitroot.co/
Twitter: https://twitter.com/Bitroot_
Telegram: https://t.me/bitroot_official