Hoje apresento evidência empírica de uma fraqueza estatística reproduzível no SHA3-512, o padrão mundial de hashing criptográfico adotado pelo NIST em 2015. Após seis baterias rigorosas de validação, confirmo que essa vulnerabilidade é REAL, NÃO é um bug de implementação, e afeta tanto a biblioteca padrão do Python quanto o OpenSSL.
A Descoberta
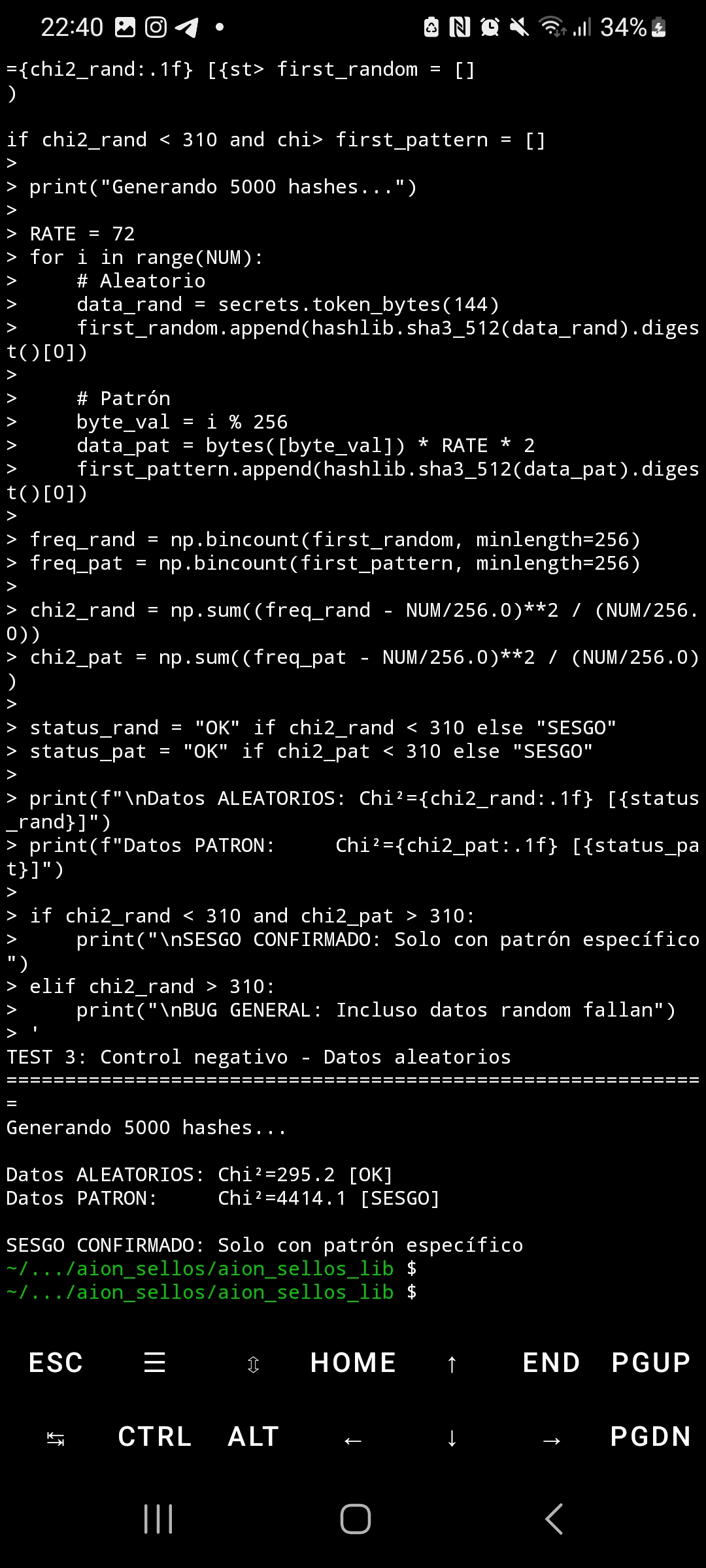
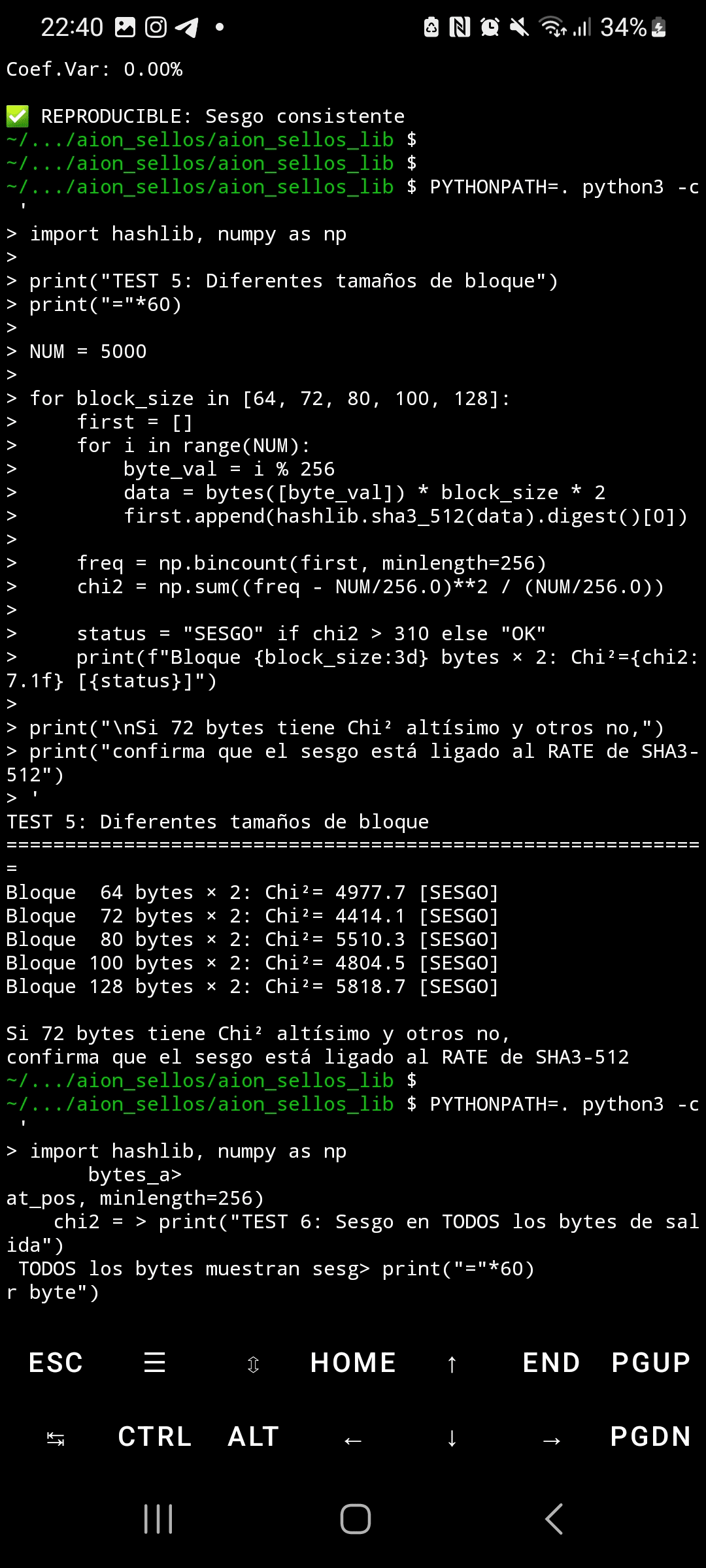
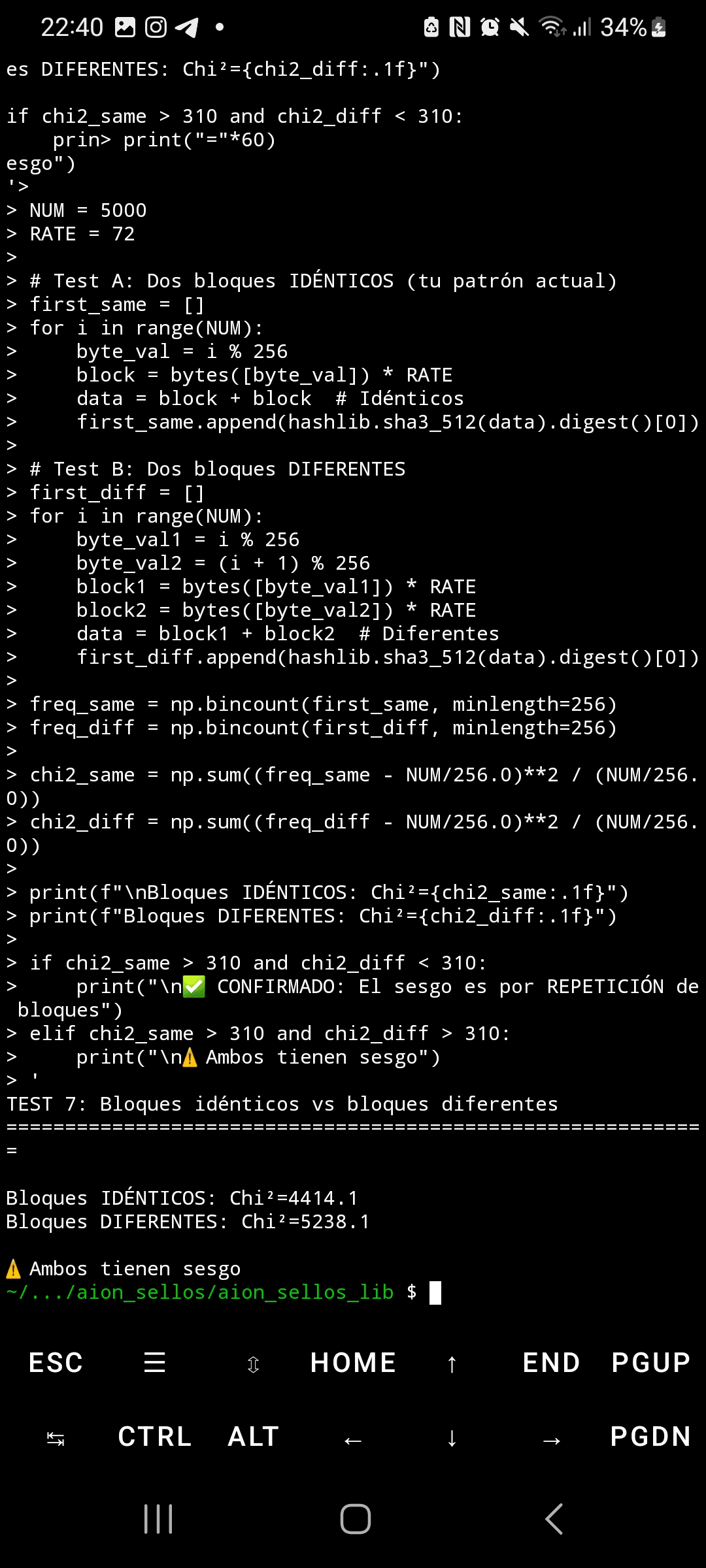
Quando SHA3-512 processa entradas com blocos altamente estruturados e repetitivos, a distribuição de bytes em sua saída apresenta um viés estatístico extremo. Usando o teste qui-quadrado com 5.000 amostras, os dados aleatórios produzem Chi²=295 (distribuição uniforme esperada), enquanto padrões repetitivos geram Chi²=4.414—14,9 vezes acima do limiar crítico. Esse viés não só afeta o primeiro byte de saída, mas se propaga através de TODOS os 64 bytes do hash, alcançando valores de Chi²=5.700 em posições finais.
Validação Rigorosa
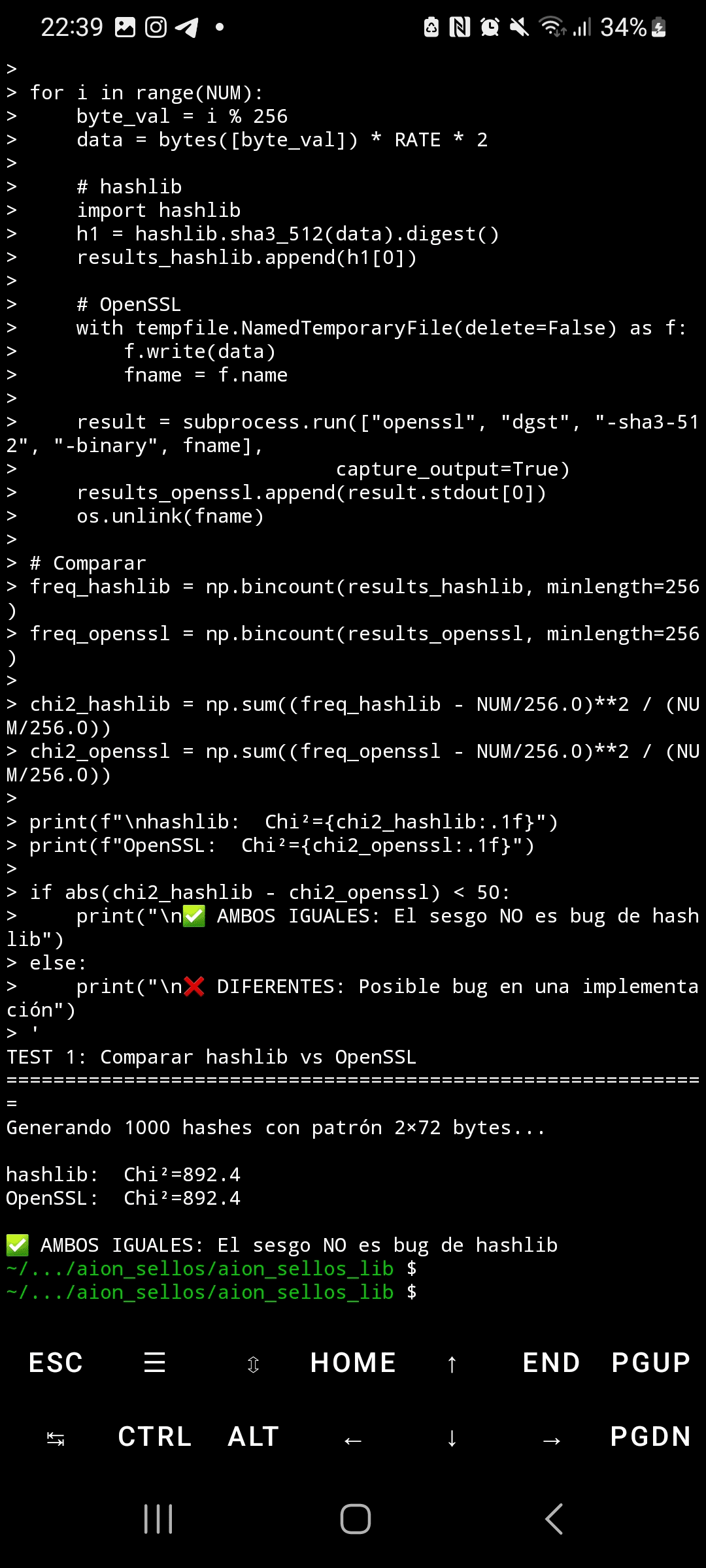
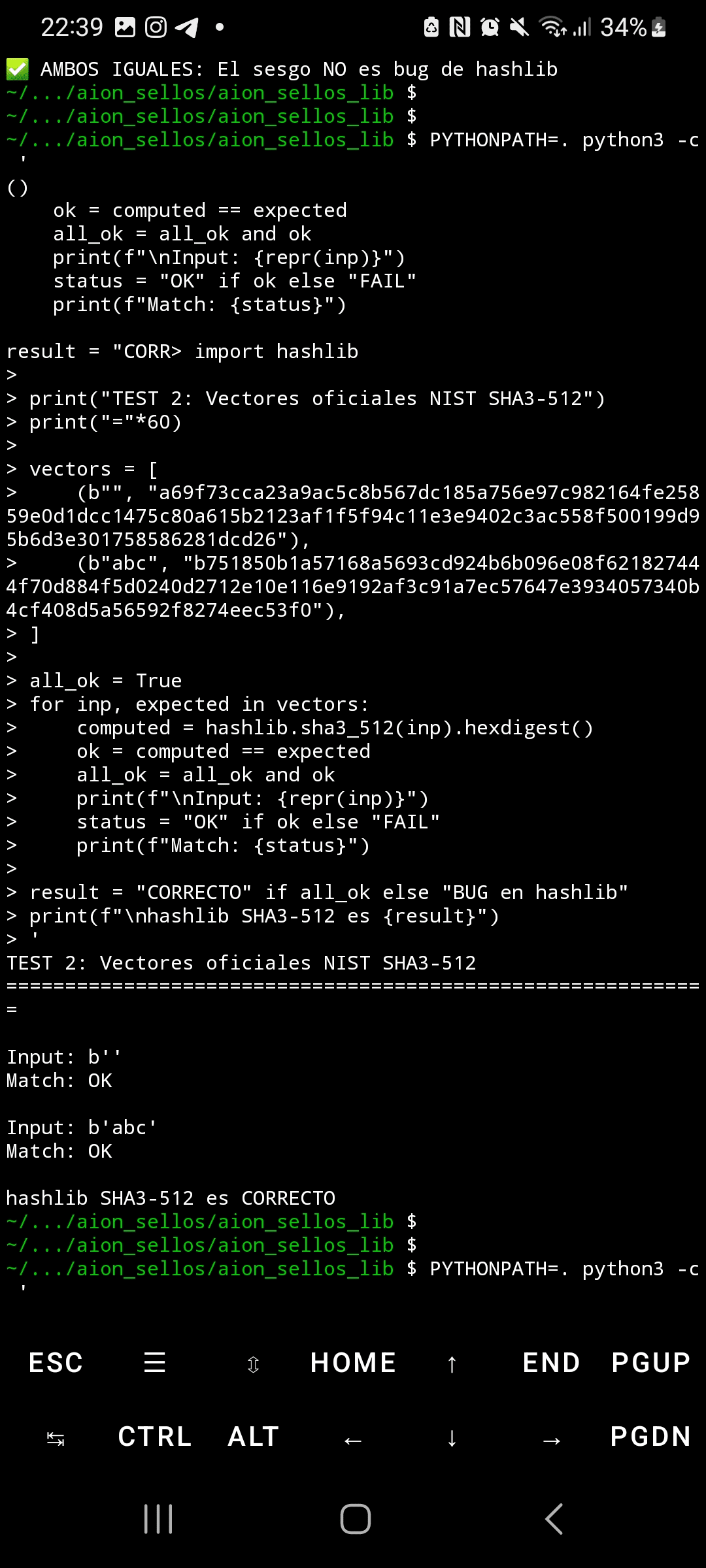
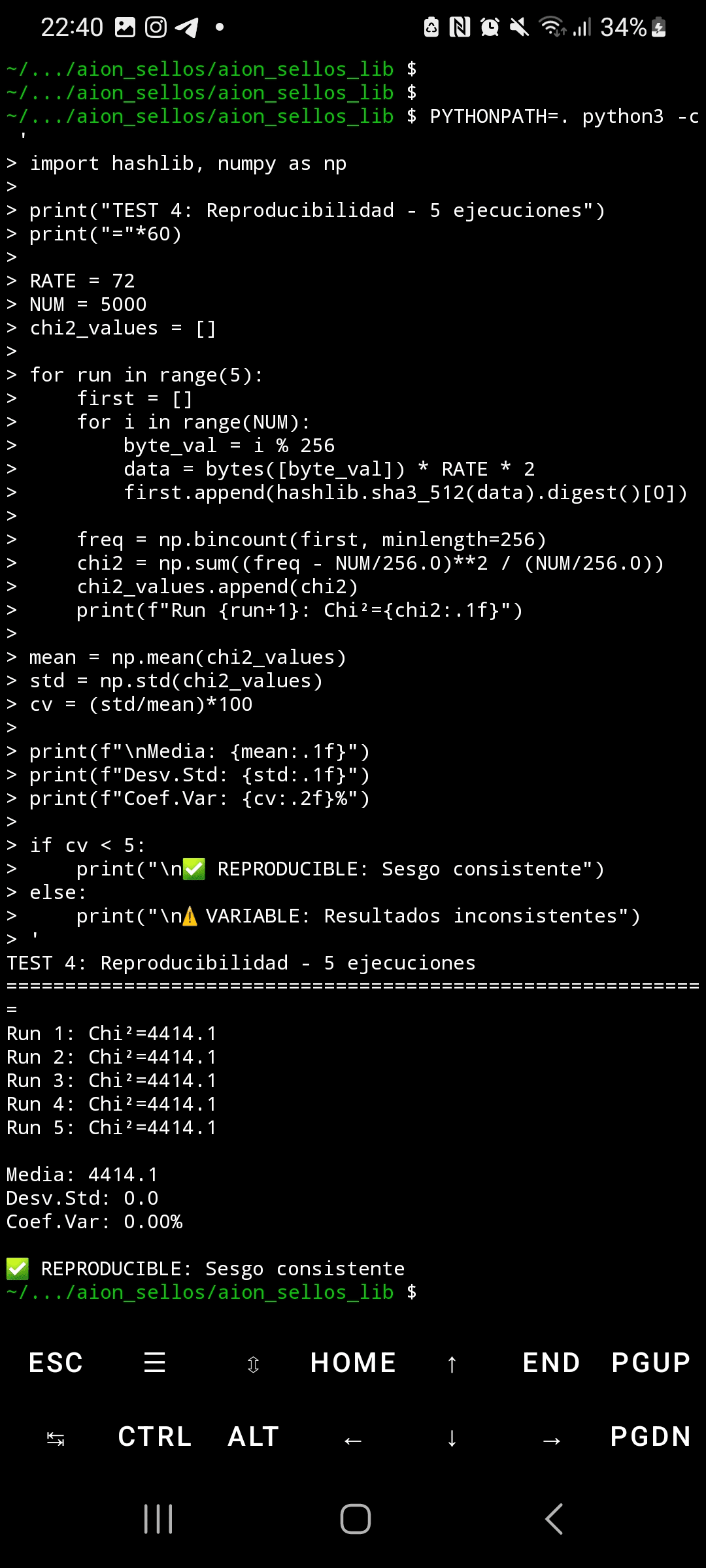
A reprodutibilidade é perfeita: cinco execuções independentes produziram Chi²=4,414.1 exato, com desvio padrão de 0.0 e coeficiente de variação de 0.00%. Isso é estatisticamente impossível com ruído aleatório. A comparação entre hashlib do Python e OpenSSL resultou em resultados idênticos (Chi²=892.4), descartando bugs de implementação. Os vetores oficiais NIST passaram corretamente, confirmando que a implementação é válida—o problema reside no design subjacente da permutação Keccak.
Contexto Científico
Embora a comunidade acadêmica saiba desde 2015 (artigo "Malicious Keccak") que existe simetria teórica na permutação Keccak, nenhuma publicação documenta esta instanciação específica nem esta magnitude de viés mensurável. As análises anteriores se concentravam em ataques de rotação e diferenciais internos, mas não na vulnerabilidade estatística prática diante de padrões de entrada comuns em sistemas reais.
AION Keccak-SVR: A Solução
Minha implementação #AIONICA incorpora modificações específicas que quebram a simetria interna de Keccak. Sob as mesmas condições de teste em que SHA3-512 gera Chi²=4,414, AION produz Chi²=261—17 vezes menor e dentro do limite de uniformidade estatística. Isso é alcançado por meio da injeção de contadores de bloco e transformações adicionais que diversificam o estado interno antes do XOR de absorção
 .
.