
@Vanarchain Când oamenii spun că vor „dApps native AI”, ceea ce înseamnă de obicei este ceva mai simplu și mai inconfortabil: s-au săturat de software care uită. S-au săturat de unelte care pot „genera”, dar nu pot rămâne consistente, nu pot păstra un fir, nu pot învăța fără a se transforma într-un coșmar al confidențialității și nu pot acționa fără a cere constant permisiunea ca un intern nervos. Ultimul an a scos această frustrare în evidență. Agenții au devenit mai buni în a face lucruri, dar majoritatea dintre ei se comportă încă de parcă ar avea amnezie. Ei pot redacta, tranzacționa, rezuma, ruta bilete, chiar și coordona cu alți agenți, totuși, în momentul în care repornești un proces, schimbi modele sau muți dispozitive, inteligența se scurge din sistem.
De aceea cadrul lui Vanar a început să rezoneze cu oamenii care chiar construiesc: tratează memoria și raționamentul ca infrastructură, nu ca o caracteristică de dorit adăugată unei aplicații. În materialele proprii ale lui Vanar, lanțul este poziționat ca fiind “construit de la bază pentru a alimenta agenți AI,” cu suport nativ pentru sarcini de lucru AI și primitive precum stocarea vectorială și căutarea similarității integrate în stivă. Partea care contează pentru mine nu este sloganul. Este implicația: dacă lanțul în sine presupune că aplicațiile tale vor fi inteligente, atunci cele mai utile dApps încetează să mai arate ca interfețe statice și încep să arate ca sisteme care pot să-și amintească, să prezică și să coordoneze sub presiune reală.
Mișcarea “AI-native” cea mai concretă pe care Vanar continuă să o sublinieze este Neutron. Neutron nu este prezentat ca un alt strat de stocare unde îți parchezi fișierele și te rogi ca linkurile să nu putrezească. Este descris ca transformând fișiere și conversații în “Semințe programabile”, comprimând și restructurând datele astfel încât să devină interogabile și pregătite pentru agenți. Vanar pune un număr clar pe asta: comprimarea a 25MB în 50KB, și chiar menționând un raport de comprimare de 500:1 ca un obiectiv operațional mai degrabă decât o demonstrație de laborator. Indiferent dacă credeți fiecare afirmație de marketing sau nu, obiectivul este clar: faceți datele suficient de mici pentru a fi partajate ușor, organizate suficient pentru a fi examinate și solide suficient pentru a fi verificate.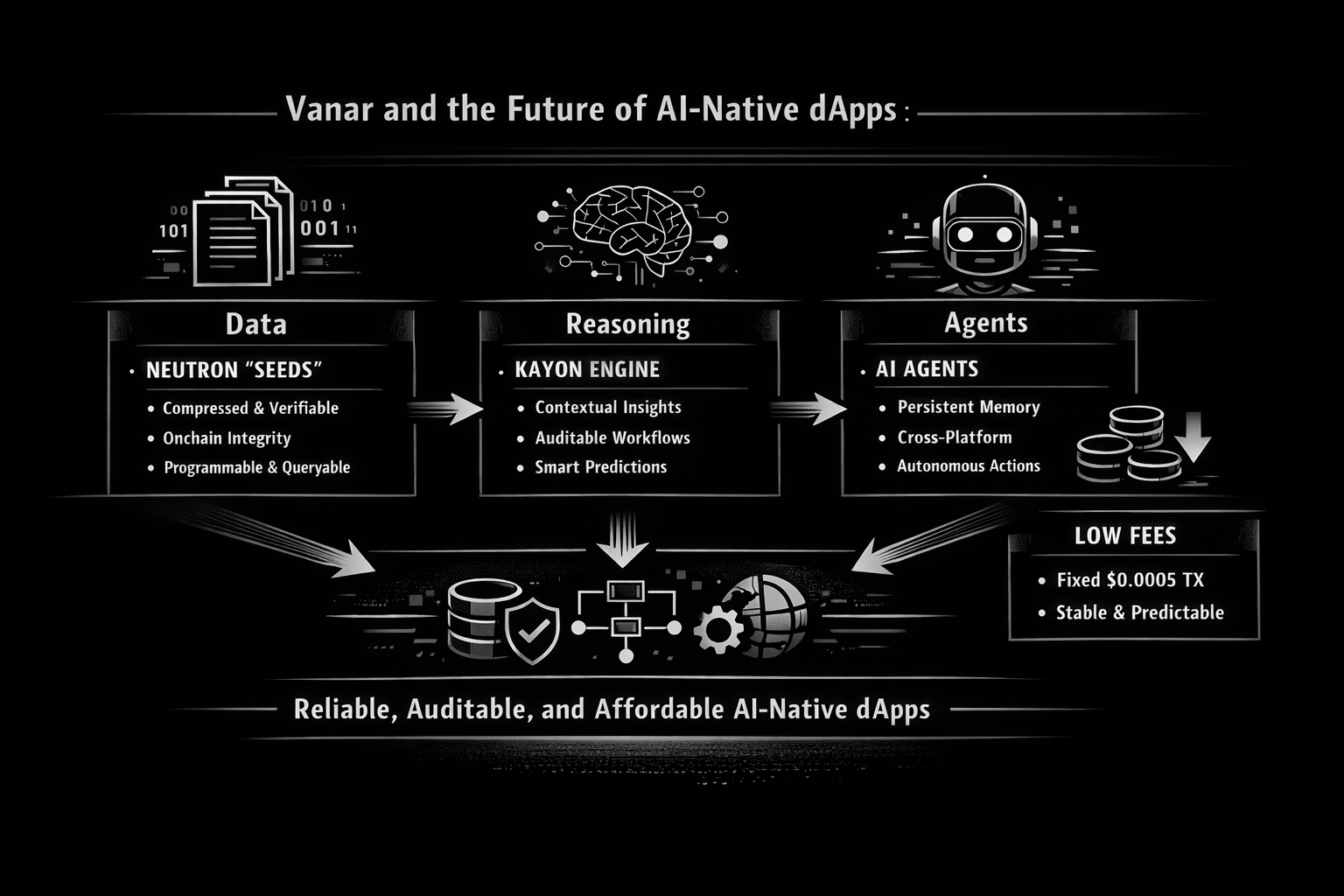 Încrederea este constrângerea tăcută din fiecare poveste de agent. Cele mai multe “instrumente predictive” de astăzi sunt inteligente până când greșesc, iar apoi devin periculoase pentru că nu își pot arăta munca. Limbajul Neutron al lui Vanar se concentrează puternic pe dovadă și verificabilitate: Semințele sunt prezentate ca fiind “complet verificabile”, iar sistemul vorbește despre dovezi criptografice și “fidelitate bazată pe dovezi”, astfel încât ceea ce recuperați rămâne valid chiar și atunci când este comprimat puternic. În documente, aceeași filozofie apare într-o formă mai sobria: Semințele pot fi stocate offchain în mod implicit pentru viteză, cu un strat opțional onchain pentru verificare, proprietate și integritate pe termen lung, plus lucruri precum metadate imuabile, urmărirea proprietății și trasee de audit. Îmi place această divizare pentru că recunoaște o adevăr pe care constructorii îl trăiesc: nu totul aparține onchain, dar lucrurile care contează cel mai mult au nevoie adesea de un ancoraj final, rezistent la manipulare.
Încrederea este constrângerea tăcută din fiecare poveste de agent. Cele mai multe “instrumente predictive” de astăzi sunt inteligente până când greșesc, iar apoi devin periculoase pentru că nu își pot arăta munca. Limbajul Neutron al lui Vanar se concentrează puternic pe dovadă și verificabilitate: Semințele sunt prezentate ca fiind “complet verificabile”, iar sistemul vorbește despre dovezi criptografice și “fidelitate bazată pe dovezi”, astfel încât ceea ce recuperați rămâne valid chiar și atunci când este comprimat puternic. În documente, aceeași filozofie apare într-o formă mai sobria: Semințele pot fi stocate offchain în mod implicit pentru viteză, cu un strat opțional onchain pentru verificare, proprietate și integritate pe termen lung, plus lucruri precum metadate imuabile, urmărirea proprietății și trasee de audit. Îmi place această divizare pentru că recunoaște o adevăr pe care constructorii îl trăiesc: nu totul aparține onchain, dar lucrurile care contează cel mai mult au nevoie adesea de un ancoraj final, rezistent la manipulare.
Odată ce accepți asta, poți vedea cum “agenții” devin mai mult decât un cuvânt la modă. Ei devin o nouă interfață utilizator pentru finanțe, fluxuri de lucru și conformitate—zone unde uitarea este costisitoare. Vanar descrie explicit Semințele Neutron ca fiind capabile să “ruleze aplicații,” inițieze contracte inteligente sau servească ca input pentru agenți autonomi, și chiar afirmă că execuția AI onchain este integrată direct în nodurile validatorilor. Asta este o direcție ambițioasă, dar indică problema corectă: agenții nu ar trebui să fie lipiți de conducte offchain fragile care se rup în momentul în care o limită de rată API te limitează sau o bază de date își schimbă forma.
Kayon este cealaltă jumătate a argumentului “utilitate reală”: raționamentul. Vanar poziționează Kayon ca un motor de raționament contextual care transformă Semințele și datele de afaceri în “informații auditabile, predicții și fluxuri de lucru,” și menționează API-uri native bazate pe MCP care se conectează la exploratori, tablouri de bord, ERP-uri și backend-uri personalizate. Aici instrumentele predictive devin mai puțin mistice și mai practice. O predicție utilă într-un cadru de afaceri este rar “prețul va crește.” Este “acest model de plată al furnizorului pare anormal,” sau “aceste portofele s-au comportat așa înainte de un vot de guvernanță,” sau “acest cluster de adrese a atins recent entități sancționate.” Exemplele proprii ale lui Vanar se îndreaptă în această direcție, inclusiv monitorizarea conformității în între jurisdicții și transformarea rezultatelor în alerte și cazuri.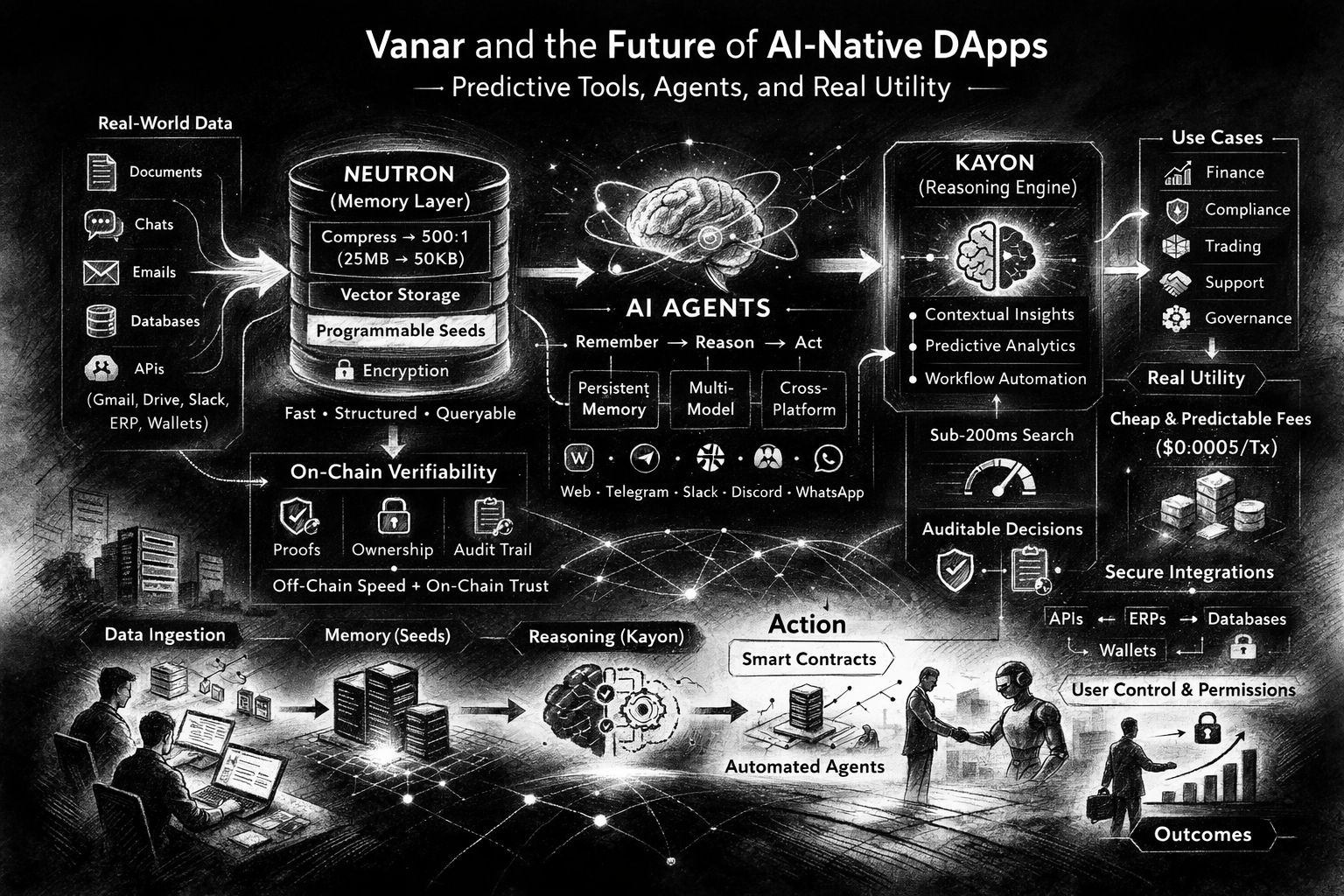
Ceea ce face ca această tendință să pară deosebit de actuală este că lumea AI standardizează în sfârșit modul în care se mișcă contextul. În minutul în care conexiunile de tip MCP devin normale, întrebarea se schimbă de la “poate agentul meu să facă X?” la “poate agentul meu să-și amintească în mod fiabil lucrurile pe care ar trebui să și le amintească și să uite lucrurile pe care ar trebui să le uite?” Documentele Neutron ale lui Vanar subliniază conexiuni sigure, permisiuni acordate de utilizatori, tokenuri criptate, sincronizare continuă și eliminarea promptă a conținutului revocat—practic, guvernarea plictisitoare a accesului la date pe care implementările reale o necesită. Lista de integrări este o dovadă, de asemenea: Gmail și Google Drive sunt “disponibile în prezent,” cu un plan pe termen lung de sisteme de locuri de muncă care urmează, de la Slack și Notion la GitHub și API-uri bancare. Asta nu este o listă de dorințe crypto. Asta este o hartă a locului unde memoria instituțională trăiește de fapt.
Cea mai vie ilustrare a problemei memoriei—și motivul pentru care oamenii discută despre asta acum—este ecosistemul agenților în sine. Pagina Neutron orientată către OpenClaw a lui Vanar descrie memoria persistentă pentru agenți pe canale de mesagerie precum WhatsApp, Telegram, Discord, Slack și iMessage, și devine neobișnuit de specifică în ceea ce privește performanța: căutare semantică sub 200ms, recuperare bazată pe pgvector și încorporări Jina v4 de 1024 dimensiuni pentru căutare multimodală pe text, imagini și documente. De asemenea, menționează izolarea multi-tenant, pachete pentru organizarea cunoștințelor și un API REST cu un SDK TypeScript. Aceste detalii contează pentru că mută ideea din “magia AI” în “suprafața de dezvoltare.” Îți poți imagina construind un agent de suport care nu doar răspunde la bilete, ci își amintește istoricul clientului pe canale și poate dovedi ce versiune de politică a folosit când a luat o decizie.
Există de asemenea o constrângere mai tăcută care apare de îndată ce agenții încep să facă muncă reală: previzibilitatea costurilor. Dacă sistemul tău se bazează pe milioane de interogări mici și micro-acțiuni, nu poți să-l funcționezi pe taxe care se comportă ca o schimbare de stare. Materialele pentru dezvoltatori ale lui Vanar afirmă un obiectiv fix de preț al tranzacțiilor de $0.0005 pe tranzacție. Și în documentație, există chiar o descriere a arhitecturii despre cum sunt agregate și curățate feed-urile de prețuri ale token-urilor, cum sunt eliminate extremele și cum sunt actualizate taxele la nivel de protocol pe o cadenta de blocuri cu comportament de rezervă dacă feed-ul eșuează. Asta nu este glamorous, dar este diferența dintre un agent care poate acționa continuu și unul care se oprește pentru că economia s-a schimbat peste noapte.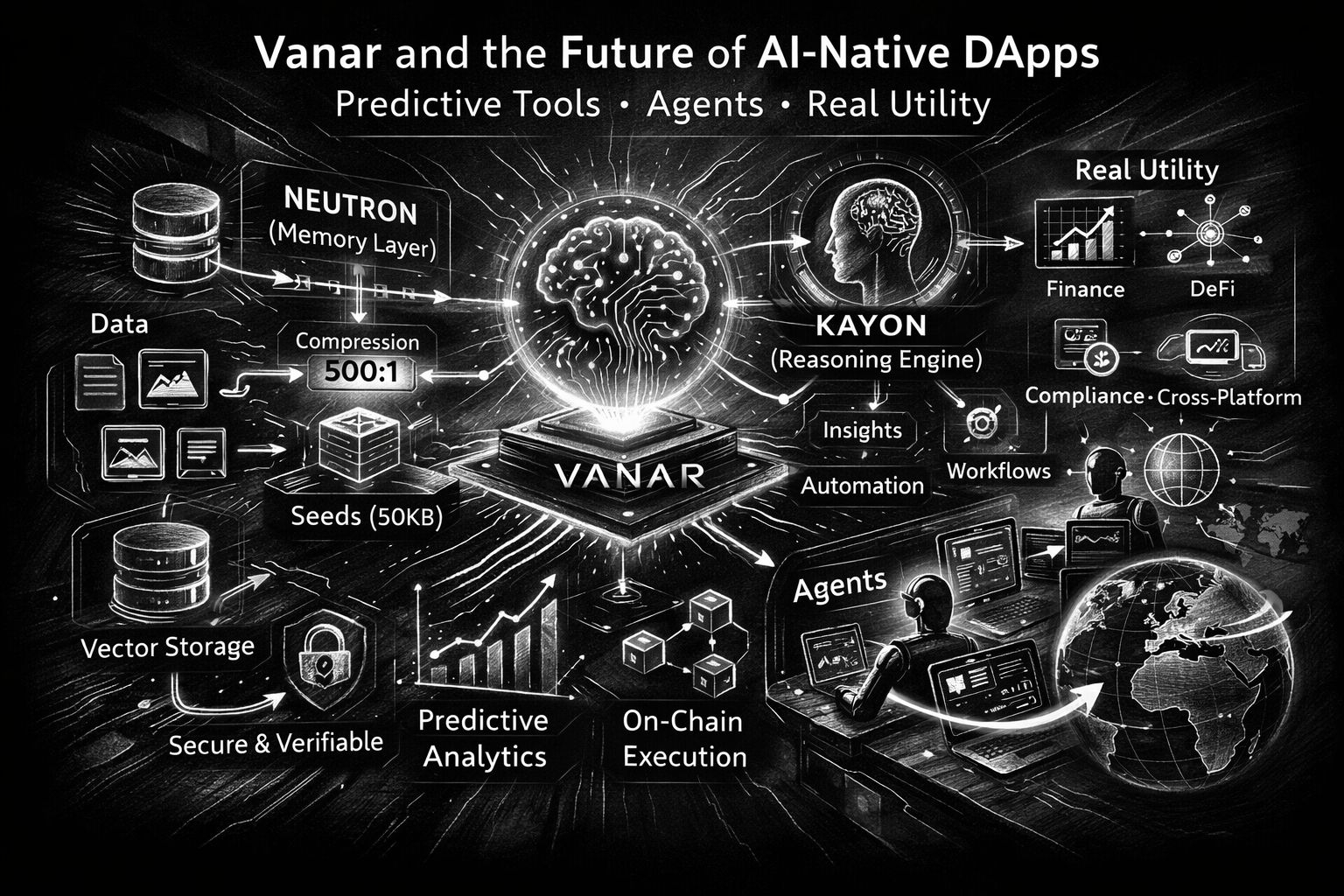
Dacă mă uit de la distanță, teza lui Vanar pentru dApps AI-native este practic aceasta: faceți cunoștințele durabile, faceți raționamentul auditabil, faceți acțiunile ieftine și previzibile și oferiți constructorilor un drum pentru a se integra cu instrumentele unde viața se întâmplă de fapt. Neutron transformă datele brute în Semințe compacte, căutabile cu integritate onchain opțională. Kayon transformă acele Semințe în întrebări pe care le poți pune în limbaj simplu, apoi în fluxuri de lucru pe care le poți apăra într-un audit. Iar stratul agenților devine credibil atunci când memoria este rapidă, portabilă și corect autorizată, nu prinsă în fereastra de context a unui singur model.
Concluzia mea, pentru cât valorează, este că următoarea generație de dApps nu va câștiga simțindu-se mai futuristă. Vor câștiga simțindu-se mai fiabile. Instrumentele predictive vor fi judecate mai puțin după cât de inteligente par și mai mult după cât de bine rămân consistente pe parcursul săptămânilor de utilizare. Agenții vor fi judecați mai puțin după o demonstrație impresionantă și mai mult după dacă inteligența lor supraviețuiește repornirilor, migrațiilor și schimbărilor de furnizori de modele. Dacă Vanar poate continua să își traducă stiva în rezultate plictisitoare și repetabile—memorie care nu putrezește, raționament care poate fi verificat și costuri care nu te surprind—atunci “dApps AI-native” încetează să mai fie o narațiune și începe să devină o categorie în care oamenii pot avea cu adevărat încredere.