When I hear a new chain highlight its throughput numbers, my first reaction isn’t awe — it’s skepticism. Not because performance doesn’t matter, but because raw TPS claims have become the industry’s favorite way to win headlines while avoiding the harder question: throughput for whom, under what conditions, and at what cost to reliability and decentralization?
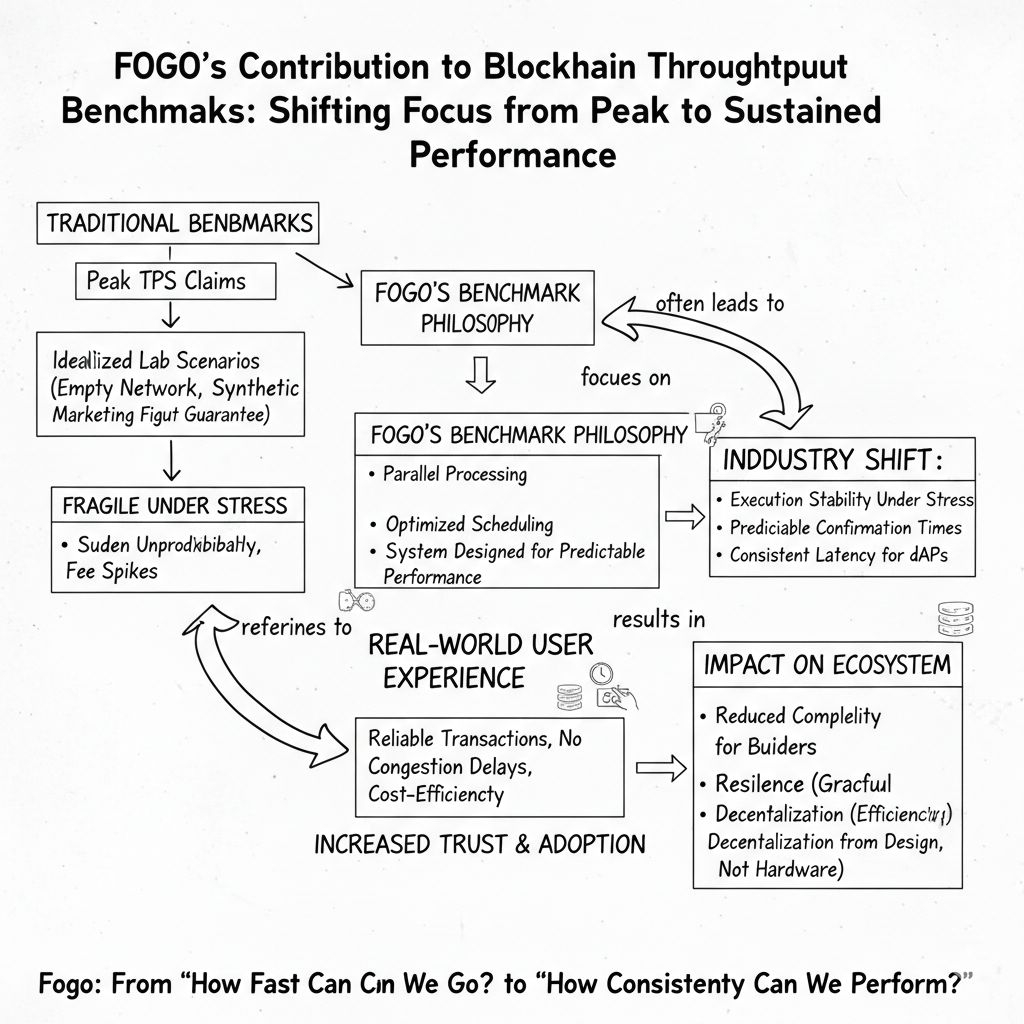
Benchmarks, in theory, exist to create comparability. In practice, they often measure idealized lab scenarios: empty networks, synthetic workloads, perfectly optimized validators, and zero adversarial behavior. The result is a number that looks impressive but tells users almost nothing about whether their transaction will confirm during volatility, congestion, or coordinated demand spikes. Throughput becomes a marketing figure instead of an operational guarantee.
This is where Fogo’s approach starts to matter. Rather than treating throughput as a peak number achieved in isolation, it frames performance around sustained execution under realistic load. Parallel processing, optimized scheduling, and fast finality aren’t presented as isolated features they function together as a system designed to keep execution predictable when activity scales. The shift is subtle but important: from “how fast can we go?” to “how consistently can we perform?”
The distinction becomes clearer when you consider what actually limits throughput in production environments. It’s rarely raw compute. It’s state contention, inefficient ordering, network propagation delays, and validator coordination overhead. A chain can claim massive TPS, but if transactions frequently collide on shared state or require sequential execution, effective throughput collapses under real usage. Fogo’s design acknowledges this by prioritizing parallel execution paths that reduce contention rather than simply increasing block size or hardware demands.
But benchmarks don’t just measure systems they shape them. When ecosystems reward peak TPS metrics, builders optimize for synthetic throughput rather than user experience. You get chains that perform brilliantly in demos but degrade under composable DeFi workloads, NFT mint storms, or arbitrage bursts. By emphasizing sustained throughput and predictable confirmation times, Fogo implicitly shifts the optimization target toward workloads that resemble actual on-chain behavior.
There’s also a market structure effect hiding inside benchmarking culture. High headline TPS encourages infrastructure arms races: more powerful hardware, fewer validators, tighter operational requirements. Performance improves, but participation narrows. If throughput gains depend on specialized environments, the network risks trading openness for speed. Fogo’s contribution here is less about a single metric and more about demonstrating that throughput improvements can come from execution efficiency and scheduling intelligence rather than pure hardware escalation.
Failure modes tell the real story. In many high-TPS systems, congestion doesn’t look like gradual slowdown — it looks like sudden unpredictability: stalled confirmations, fee spikes, dropped transactions, and inconsistent ordering. Benchmarks rarely capture these edge behaviors. A throughput model built around sustained performance aims to degrade gracefully instead of failing abruptly, which is far more relevant to traders, applications, and automated systems that depend on execution guarantees.
Trust shifts alongside these performance claims. Users don’t experience TPS; they experience whether their actions complete reliably. If throughput benchmarks align with lived performance, confidence grows organically. If they don’t, the gap erodes trust faster than any outage. By focusing on execution consistency, Fogo treats throughput not as a bragging right but as a reliability contract between the network and its users.
There’s a security dimension as well. Systems optimized purely for maximum throughput often reduce safety margins — shorter propagation windows, tighter timing assumptions, and higher sensitivity to network variance. Sustainable throughput, by contrast, implies tolerance: the ability to maintain performance without operating at the edge of failure. That resilience become invisible when benchmarks focus only on peak numbers.
As applications scale responsibility shifts up the stack. Wallets, relayers and dApps depends on predictable execution windows to manage retries, batching, and user feedback. Throughput that fluctuates wildly forces each layer to compensate with heuristics and safeguards. Throughput that holds steady simplifies the entire stack. In that sense, Fogo’s benchmark philosophy doesn’t just affect validators — it reduces complexity for every builder integrating with the network.
This creates a new competitive axis. Chains won’t just compete on maximum TPS; they’ll compete on execution stability under stress. How does performance hold during market shocks? Do confirmation times remain predictable when arbitrage bots saturate the mempool? Can applications rely on consistent latency for automated strategies? These questions matter more than isolated peak metrics, and they redefine what “fast” actually means in a production environment.
The strategic implication is that throughput benchmarks are evolving from marketing artifacts into operational standards. If Fogo succeeds in normalizing sustained-performance metrics, it could push the broader ecosystem to adopt benchmarks that reflect real workloads rather than synthetic extremes. That would make performance claims more comparable, more honest, and ultimately more useful to builders deciding where to deploy.
The long-term value of this shift will only become clear during stress. In calm conditions, almost any chain appears fast. In volatile markets, only systems designed for consistent execution maintain their guarantees without resorting to fee spikes, throttling, or silent prioritization. Benchmarks that survive chaos become credibility, not just numbers.
So the question that matters isn’t how high Fogo’s throughput can climb in a controlled test. It’s whether its benchmark philosophy — sustained, predictable, contention-aware performance — can redefine what the industry measures, and whether users will finally judge speed not by peaks, but by reliability when it counts.
@Fogo Official $FOGO #fogo $DOT


