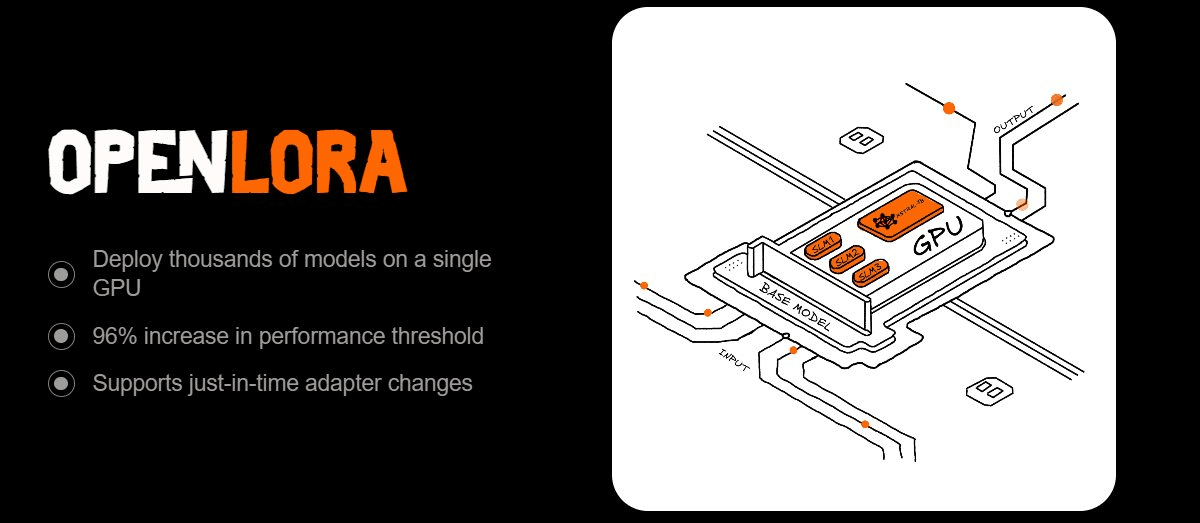
Cei mai mulți oameni nu își dau seama cât de haotic devine când încerci să deservi o grămadă de modele fine-tuned. Fiecare adaptor consumă memorie GPU, comutarea pare a fi un efort, iar costurile se acumulează rapid.
De aceea OpenLoRA mi-a atras atenția. Este construit pentru a deservi mii de modele LoRA pe un singur GPU fără a se obosi. Trucul? Încărcarea dinamică a adaptorilor. În loc să preîncărcați totul, trage doar ceea ce aveți nevoie, fuzionează cu un model de bază pe parcurs și îl returnează după inferență. Memoria rămâne subțire, debitul rămâne ridicat, iar latența rămâne scăzută.

Ce o face puternică pentru mine:
Hugging Face, Predibase, sau chiar adaptoare personalizate? Le aduce JIT.
Ai nevoie de inferență în ansamblu? Multiple adaptoare pot fi combinate per solicitare.
Gestionarea contextului lung? Atenție paginată + atenție flash o acoperă.
Vrei să reduci costurile? Quantizarea și optimizările la nivel CUDA reduc foarte mult consumul GPU.
Aceasta nu este doar o bomboană infra. Este diferența dintre pornirea unei instanțe separate pentru fiecare model și rularea a mii eficient într-un singur loc. Pentru dezvoltatori, asta înseamnă că poți lansa chatboți cu personalități diferite, asistenți de cod adaptați pentru sarcini de nișă sau modele specifice domeniului - fără dureri de cap legate de scalare.
Și cea mai bună parte, cel puțin pentru mine, este cum se leagă de motorul de atribuire OpenLedger. De fiecare dată când un adaptor rulează, sistemul înregistrează cine l-a antrenat, ce date a folosit și cum a contribuit. Recompensele revin în timp real. Aceasta este proprietatea țesută direct în pipeline.
Teza mea: OpenLoRA nu este doar despre a face LoRA mai ușoară, ci despre a face infrastructura AI scalabilă, eficientă din punct de vedere al costurilor și corectă. Dacă AI va fi personalizată și răspândită, aceasta este genul de bază de care are nevoie.
#OpenLoRA #OpenLedger $OPEN @OpenLedger