I was explaining this to my team during a late-night system review: building intelligence is easy; making sure it can be trusted in the real world is the hard part. That was when we decided to integrate @Fabric Foundation with $ROBO as a decentralized verification layer in our predictive maintenance and industrial monitoring setup. 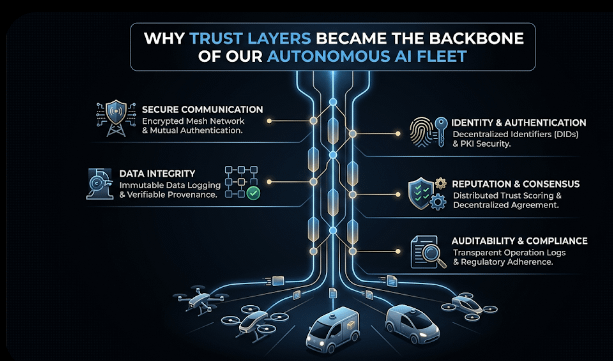
Our environment is a fleet of autonomous inspection robots, each constantly generating AI outputs vibration spikes, temperature anomalies, and operational forecasts. Before Fabric, these outputs went directly into our maintenance scheduler. Most of the time, it worked. But occasionally, high-confidence predictions were misleading. A robot would flag a false vibration alert, or two units would report conflicting temperatures.
Introducing Fabric Protocol changed everything. Each AI output became a structured claim, for example “Motor 4 vibration exceeds 85% threshold” or “Cooling fan efficiency 92%.” These claims pass through $ROBO validators, which cross-check them against historical patterns and signals from other robots before influencing operational decisions. In effect, @Fabric Foundation sits between raw AI perception and actionable trust.
During our first three weeks, we processed 26,400 claims. Average consensus time per claim was 2.7 seconds, with peaks around 3.3 seconds when multiple high-priority alerts came simultaneously. About 3.6% of claims were rejected, mostly due to sensor drift, calibration discrepancies, or environmental edge cases. Those claims, if acted upon automatically, could have led to unnecessary interventions or overlooked risks.
We ran a controlled test by slightly perturbing the vibration sensors on two robots overnight. AI models still produced confident predictions, but validators rejected 38% of these claims due to inconsistencies with nearby robots. The decentralized layer essentially forced cross-verification and highlighted latent errors that conventional systems would have missed.
Tradeoffs exist. Decentralized verification adds latency and relies on validator availability. During a brief maintenance window, consensus time spiked by nearly a second. Not critical for our environment, but something to consider in high-frequency operational scenarios.
Another subtle effect was cultural. Engineers stopped treating AI outputs as conclusive. Outputs became proposals, each waiting for $ROBO consensus before being trusted. This mindset shift improved operational discipline and provided a full audit trail of decisions. Transparency became as valuable as accuracy.
Fabric’s modular design simplified integration. We didn’t redesign AI models; we only standardized claim formatting for verification. This allowed the middleware to evolve independently while models continued to generate outputs naturally.
Skepticism remains vital. Validators can enforce consensus, but they cannot create ground truth. If every sensor misreads a situation, validators will still agree on a false claim. Verification reduces risk; it doesn’t remove uncertainty entirely.
After several months of running this architecture, the biggest improvement isn’t fewer errors. It’s traceability and confidence. Every claim carries a $ROBO consensus record. When unexpected events occur, we can analyze exactly why the system trusted or rejected a claim.
Integrating @Fabric Foundation didn’t make our AI smarter. It built a structured pause a trust layer ensuring each output is questioned before affecting the real world. And in autonomous AI operations today, that pause may matter more than intelligence itself.