@Fabric Foundation I was at my desk at 6:40 a.m. listening to the radiator tick when I reopened a note about AI training data because model demos are everywhere right now and one basic question still nags me whenever I see them: where did the inputs come from and can anyone prove it?
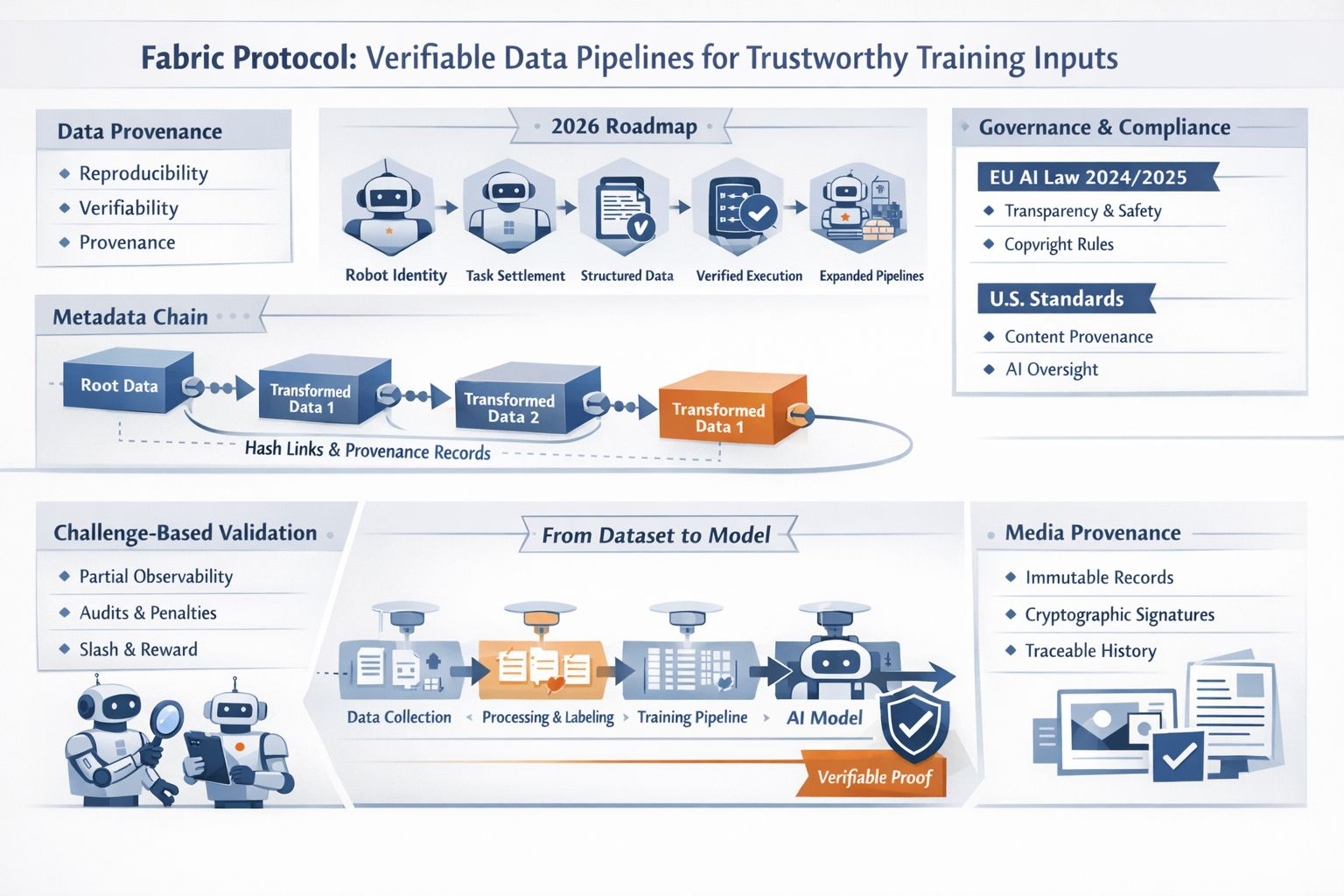
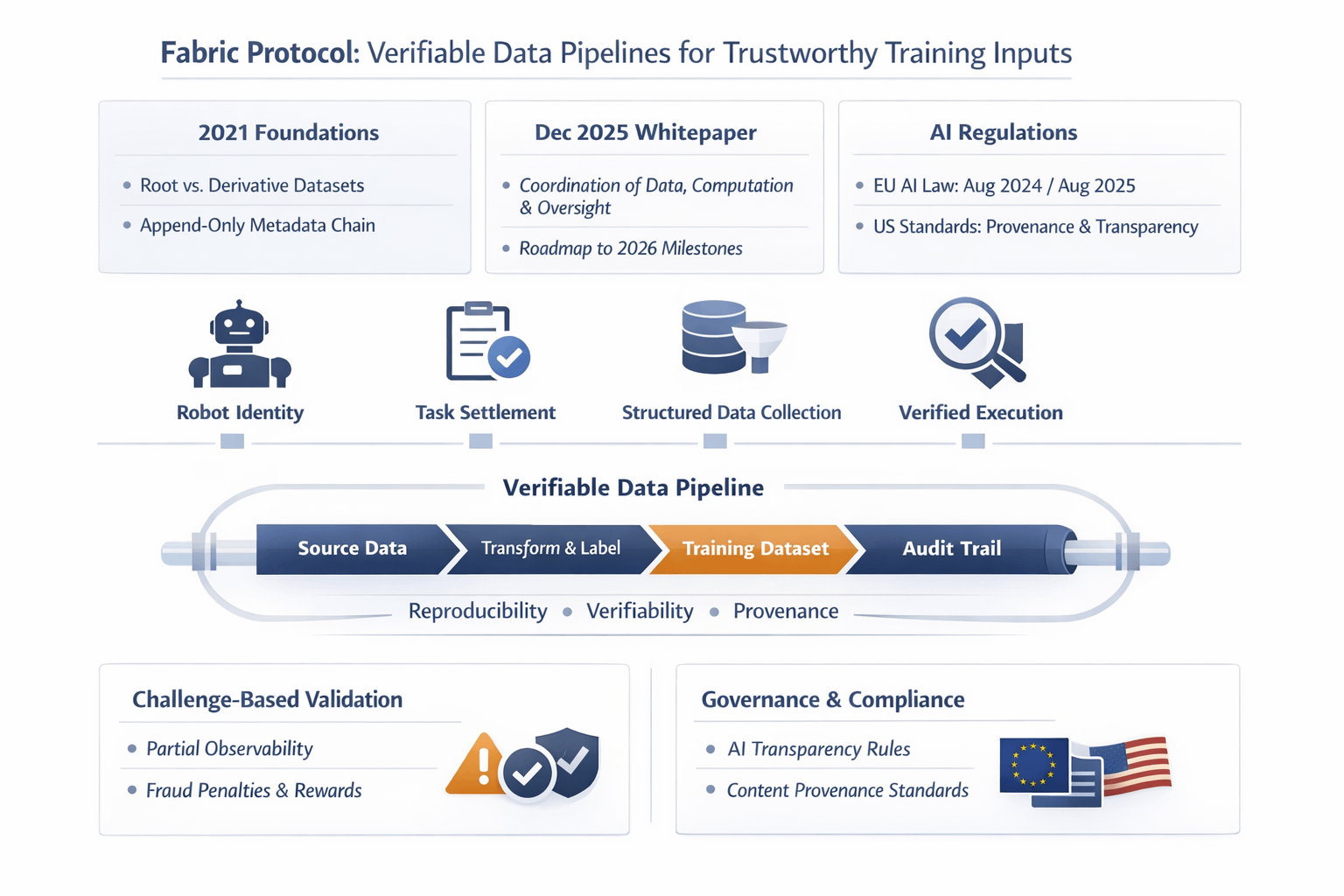
When I read the recent Fabric Protocol whitepaper, I didn’t see only another grand system for robots. I saw a practical response to a problem I keep running into across AI work: data gets collected, filtered, relabeled, recombined, and pushed into training loops until its origin is blurry. Fabric describes itself as a public network for coordinating data, computation, and oversight through immutable ledgers, and its 2026 roadmap is strikingly specific about robot identity, task settlement, structured data collection, verified task execution, and larger data pipelines. That combination matters to me because trustworthy models do not begin with better prompts. They begin with evidence about what entered the pipeline.
What makes Fabric interesting is that it does not start from nothing. I can trace a clear line back to an earlier protocol paper from 2021 that framed data supply chains in terms of reproducibility, verifiability, and provenance. That earlier work separated root datasets from derivative datasets and proposed an append-only metadata chain with cryptographic links and hashes of associated data slices. I like that detail because it sounds less like ideology and more like accounting. Instead of asking me to trust a polished dataset on reputation alone, the system tries to preserve a durable record of source, schema, transformation, and timing. For training inputs, that is the difference between a story and a receipt.
I think more people are paying attention to this now because the pressure around AI has become much more real. A major European AI law came into force in 2024 and some of its requirements are already in motion. By August 2025 the rules for general-purpose AI models had also kicked in. Then a code of practice published in July 2025 brought transparency and copyright into the same practical conversation. A major U.S. standards body has also treated content provenance as one of the core considerations in its generative AI profile. None of that turns provenance into a solved problem, but it does change the mood around it. I no longer hear provenance discussed as a nice extra. I hear it described, more often, as operating discipline.
I also think Fabric lands at a useful moment because machine learning is moving out of the lab notebook and into systems that act in the world. Once a model can route tasks, operate a robot, or submit work for payment, I stop caring only about benchmark scores. I care about whether the data trail survives contact with reality. Fabric’s fresh angle is that it admits a hard limitation: in physical settings, task completion can be attested without being perfectly provable. Its answer is not magic. It is a challenge-based design with validators, penalties, slashing conditions, and rewards for fraud detection, all meant to make cheating expensive rather than impossible. To me, that is real progress, because grown-up infrastructure usually begins when somebody stops pretending certainty is free.
What I find most promising is the cultural shift underneath the mechanics. Media provenance standards have already normalized the idea that provenance can travel with an asset as a signed history of source and changes. Fabric seems to apply a related instinct to machine training and machine behavior: keep the chain, keep the context, and keep the incentives honest enough that later audits are possible. I don’t think verifiable pipelines will make training data pure, neutral, or dispute-free. I do think they can make arguments about training inputs less foggy and less theatrical. That alone would improve audits, procurement reviews, and postmortems after failures. Right now, that feels like a modest goal worth taking seriously. I’d rather inspect a messy ledger than accept a polished myth about quality, consent, ownership, and the labor behind datasets.
For the factual scaffolding behind the piece: Fabric’s December 2025 whitepaper describes the protocol as coordinating data, computation, and oversight through public ledgers, and its roadmap lists 2026 milestones including robot identity, task settlement, structured data collection, verified task execution, and expanded data pipelines.
The historical through-line comes from a 2021 protocol paper, which explicitly frames the problem around reproducibility, verifiability, and provenance, distinguishes root from derivative datasets, and describes an append-only metadata chain cryptographically linked to associated data slices.
The “why now” context comes from current governance and standards work: a major European AI law says it entered into force on 1 August 2024, that general-purpose AI obligations became applicable on 2 August 2025, and that a code of practice published on 10 July 2025 addresses transparency, copyright, and safety; a major U.S. standards body’s generative AI profile identifies governance, content provenance, pre-deployment testing, and incident disclosure as four primary considerations.
The paragraph about limits and penalties is grounded in Fabric’s own text: it says robot service provision has partial observability, that task completion can be attested but not cryptographically proven in general, and that the protocol uses challenge-based verification and slashing conditions to make fraud unprofitable in expectation. The media provenance point comes from an official specification source, which describes such standards as certifying the source and history of media content.