Most people still talk about Artificial Intelligence like the model is the product.
They always say things like: model, more parameters, faster responses, better benchmark scores.
After watching this space for a while it starts feeling strange how little attention goes to the thing feeding those models in the first place.
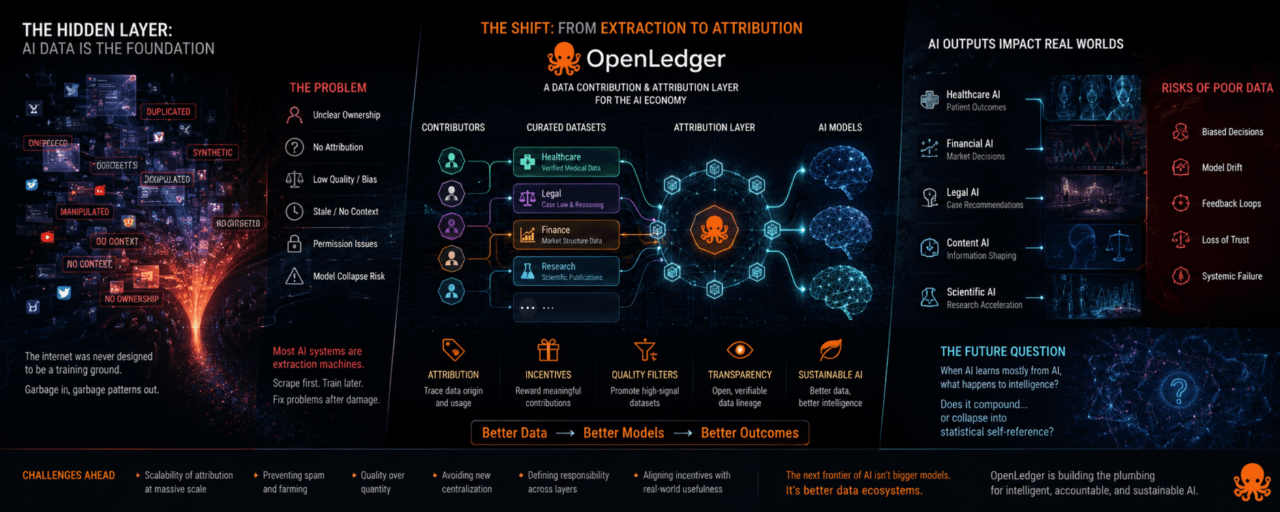
Artificial Intelligence data still feels like the hidden layer nobody wants to discuss
That is probably the thing that caught my attention with OpenLedger.
The project keeps pulling the conversation back toward Artificial Intelligence data itself of treating it like some invisible raw material that magically appears from the internet forever.
Honestly that changes the whole discussion around Artificial Intelligence learning algorithms.
Because once you stop assuming unlimited clean Artificial Intelligence data exists the entire system starts looking less stable than people think.
Most Artificial Intelligence learning algorithms today depend on scale more than elegance.
You feed information into an Artificial Intelligence model and eventually patterns emerge.
Useful patterns emerge, sometimes broken ones emerge.
The industry spent years acting like compute power was the bottleneck.
Now it increasingly looks like Artificial Intelligence data is the actual constraint.
Not just the quantity of Artificial Intelligence data. Also freshness, ownership, accuracy, bias, permission and context.
These things matter once Artificial Intelligence systems start operating continuously instead of being trained once and forgotten.
That creates a problem.
The internet was never designed to become a training ground for machine learning systems.
A lot of content online is duplicated a lot is synthetic already some of it is manipulated for engagement. Some of it is outdated but still treated as fact because Artificial Intelligence models cannot naturally understand time the way humans do.
So when OpenLedger pushes the idea of Artificial Intelligence data attribution and specialized Artificial Intelligence datasets it feels like a trendy crypto angle and more like somebody noticing where future cracks may appear.
The interesting part is not the blockchain itself it is the attempt to structure how Artificial Intelligence learns.
Most Artificial Intelligence ecosystems today behave like extraction machines: scrape first train later deal with ownership questions after regulators get involved.
That approach worked when Artificial Intelligence was experimental. It is not sure if it scales once companies begin depending on Artificial Intelligence models for actual workflows and decisions.
If a healthcare Artificial Intelligence model trains on medical Artificial Intelligence data the damage is obvious.
Even smaller failures matter: recommendation systems drift, financial sentiment Artificial Intelligence models overfit narratives, language Artificial Intelligence models slowly recycle their own generated content back into training loops.
Artificial Intelligence learning algorithms were originally improving by observing behavior and human writing patterns.
Now more and more internet content is machine generated.
So what happens when Artificial Intelligence models mostly learn from Artificial Intelligence models?
Does intelligence compound. Does the system slowly collapse into statistical self-reference?
Feels like nobody fully knows yet.
This is where OpenLedger’s design choices become more interesting than the decentralized Artificial Intelligence" branding.
The network seems focused on tracing where Artificial Intelligence data came from and rewarding contributors tied to useful Artificial Intelligence datasets.
Least conceptually that changes incentives.
Normally Artificial Intelligence data contributors disappear after uploading content platforms capture the value Artificial Intelligence models absorb the information and original sources become irrelevant.
OpenLedger appears to be trying to keep the connection alive between Artificial Intelligence data origin and Artificial Intelligence model output.
That sounds simple on paper much harder in reality.
Because attribution inside machine learning systems is messy once patterns merge inside a network it becomes difficult to isolate exactly which Artificial Intelligence data point influenced which behavior.
So the idea itself makes sense. Implementation feels like the real battlefield here.
Can attribution stay meaningful at scale?
Can contributors actually verify Artificial Intelligence data usage?
Can low-quality spam Artificial Intelligence datasets flood reward systems the way farming destroyed incentives in other crypto sectors?
That risk feels very real.
There is also another issue underneath all this.
Good Artificial Intelligence data is not evenly distributed.
Some industries naturally produce structured information others produce noise.
So if Artificial Intelligence ecosystems begin rewarding Artificial Intelligence data then eventually certain groups gain disproportionate influence over how future Artificial Intelligence systems behave.
That introduces another layer of centralization inside supposedly decentralized systems.
People talk about compute monopolies all the time Artificial Intelligence data monopolies may end up important and harder to detect.
Still there is something about OpenLedger focusing on the input layer instead of pretending Artificial Intelligence model architecture alone solves everything.
A lot of crypto Artificial Intelligence projects feel disconnected from how machine learning evolves.
They attach tokens to GPU marketplaces. Call it infrastructure but Artificial Intelligence learning algorithms do not improve just because more hardware exists.
They improve when signal quality improves: training sets, better labeling, more domain-specific context more feedback loops grounded in reality instead of synthetic engagement metrics.
That part matters, probably than most retail traders notice right now.
Another thing worth watching is whether smaller specialized Artificial Intelligence models become more valuable than general-purpose systems.
Because if that happens then curated Artificial Intelligence datasets become assets.
A legal Artificial Intelligence model trained on verified reasoning, a biotech Artificial Intelligence model trained on real research environments a trading Artificial Intelligence model trained on reliable market structure behavior instead of random social noise.
That future would naturally increase the importance of networks trying to organize Artificial Intelligence data contribution systems.
Maybe that is where OpenLedger fits best not replacing Artificial Intelligence labs more like becoming plumbing underneath narrower intelligent systems.
There is still a trust problem here.
Crypto systems love talking about transparency Artificial Intelligence systems are usually black boxes.
Combining the two does not automatically solve accountability it may even create confusion.
Who gets blamed when Artificial Intelligence model outputs fail?
The Artificial Intelligence dataset provider, the Artificial Intelligence model builder, the inference layer, the network validators?
Responsibility becomes blurry fast once enough layers stack together.
Then there is the economic side.
Decentralized systems eventually struggle with incentive quality.
People optimize for rewards, not usefulness that pattern repeats everywhere: liquidity mining, airdrop farming, content farming, governance participation.
So the real test for OpenLedger probably is not architecture it is whether the network can distinguish genuinely valuable Artificial Intelligence learning data, from mass-produced garbage designed only to extract rewards.
That sounds easier than it is because humans themselves barely agree on what "high-quality information" even means anymore.
The deeper I look at Artificial Intelligence learning systems the less they resemble engineering problems.
They start looking like social systems disguised as software.
Human behavior enters the loop everywhere bias enters, economic pressure enters, manipulation enters attention incentives enter.
That changes how these Artificial Intelligence algorithms evolve over time.
Maybe that is why projects focusing on Artificial Intelligence data structure feel more important lately not because they solved Artificial Intelligence more because they noticed where the current Artificial Intelligence model may quietly start breaking first.
