
OpenLedger is one of the few AI-blockchain projects I’ve looked at recently where the infrastructure story is actually more interesting than the marketing
That alone makes it stand out
I spend a lot of time reading through AI and crypto architectures, and honestly, most of them collapse into the same pattern after ten minutes. A token. An “AI marketplace.” A vague decentralization pitch. Maybe an agent framework nobody will use. I’ve seen this fail over and over because the underlying economics never make sense
OpenLedger at least starts from a real problem
AI systems are consuming absurd amounts of data, but the pipeline around that data is still primitive. Centralized. Opaque. In some cases borderline chaotic. Companies scrape information from everywhere, train models behind closed doors, and the people contributing value are completely disconnected from the upside
That model scales technically. Socially, it’s a mess
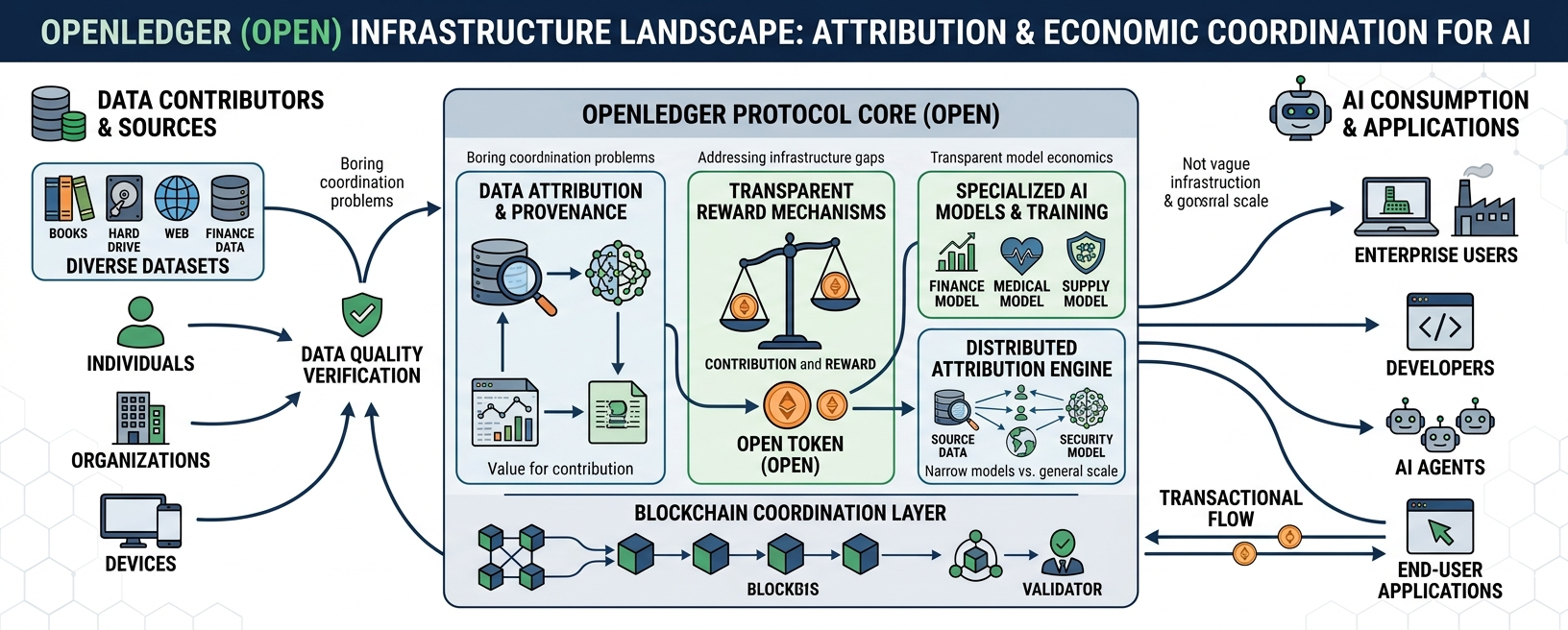
What caught my attention with OpenLedger is that the project seems less focused on “AI magic” and more focused on attribution infrastructure. That’s a very different conversation. The team is essentially asking whether AI can operate with transparent economic coordination instead of invisible extraction
And frankly, that question matters more than another chatbot demo
The architecture revolves around tracking how data contributes to model outputs and then building reward mechanisms around those contributions. On paper, it sounds clean. In practice, attribution systems are notoriously difficult. Anyone who has worked around distributed systems or machine learning pipelines knows this gets complicated fast. Data influence is rarely linear. Models don’t behave predictably Contributions overlap constantly
Still, I think OpenLedger is targeting the correct layer of the stack
Most AI discussions today obsess over model size. Bigger parameter counts. Bigger GPUs. Bigger funding rounds. But infrastructure history usually punishes that mindset eventually. I watched the same thing happen in cloud computing years ago. Everyone chased raw scale until operational complexity became the actual bottleneck
AI is moving toward the same wall
The future probably belongs to systems that can coordinate specialized intelligence efficiently rather than brute-forcing everything through giant monolithic models. That’s where OpenLedger’s approach becomes interesting to me. The project leans heavily into specialized AI models and structured data networks instead of pretending one universal model will solve every problem on earth.
That feels much closer to reality
In enterprise environments especially, narrow models trained on high-quality domain data often outperform generalized systems. Financial analysis. Medical research. Security monitoring. Supply chain forecasting. Precision matters more than broad conversational ability in those environments
OpenLedger seems built around that assumption
The blockchain side of the system is really functioning as an economic coordination layer. Contributors provide datasets. Developers build or fine-tune models. AI agents consume resources and interact with applications. The OPEN token sits underneath all of it as the transactional mechanism tying those activities together
I know some people immediately tune out when token mechanics enter the conversation. Fair enough. Most tokenized systems are badly designed. Incentives drift. Usage disappears. Speculation overwhelms utility
But AI infrastructure probably does need native economic coordination eventually. Compute costs money. Data has value. Inference workloads need pricing. Contributors expect compensation. Somebody has to manage those flows
Centralized platforms already do this internally. OpenLedger is trying to externalize it into a network model instead
That’s the real experiment here
And I think the timing is probably better than most people realize. The AI industry is entering an awkward phase where everyone suddenly understands that data quality matters more than endless scale, but nobody has solved how data ownership should work at internet scale
Meanwhile regulators are circling, copyright lawsuits are multiplying, and enterprises are becoming more cautious about black-box systems trained on unverifiable datasets
You can feel the tension building already
That creates an opening for infrastructure projects focused on provenance, attribution, and transparent model economics. Not because those topics are exciting — they usually aren’t — but because operational trust eventually becomes unavoidable once systems move beyond demos and into production environments
The hard part is execution
Distributed attribution systems are difficult enough on their own. Combining them with AI workloads and blockchain coordination adds another layer of complexity entirely. Latency, validation, fraud resistance, reward balancing, model integrity — every one of those becomes its own engineering problem
I’ve seen technically ambitious networks drown under incentive complexity before. Crypto is full of graveyards built on elegant whitepapers
So I’m still skeptical. I think that’s healthy
But I also think OpenLedger is asking smarter questions than most projects in this sector. Instead of chasing consumer hype cycles, it’s trying to address the infrastructure gaps underneath AI itself. That’s usually where durable systems come from
Not from hype
From boring coordination problems nobody else wants to solve until they become unavoidable
