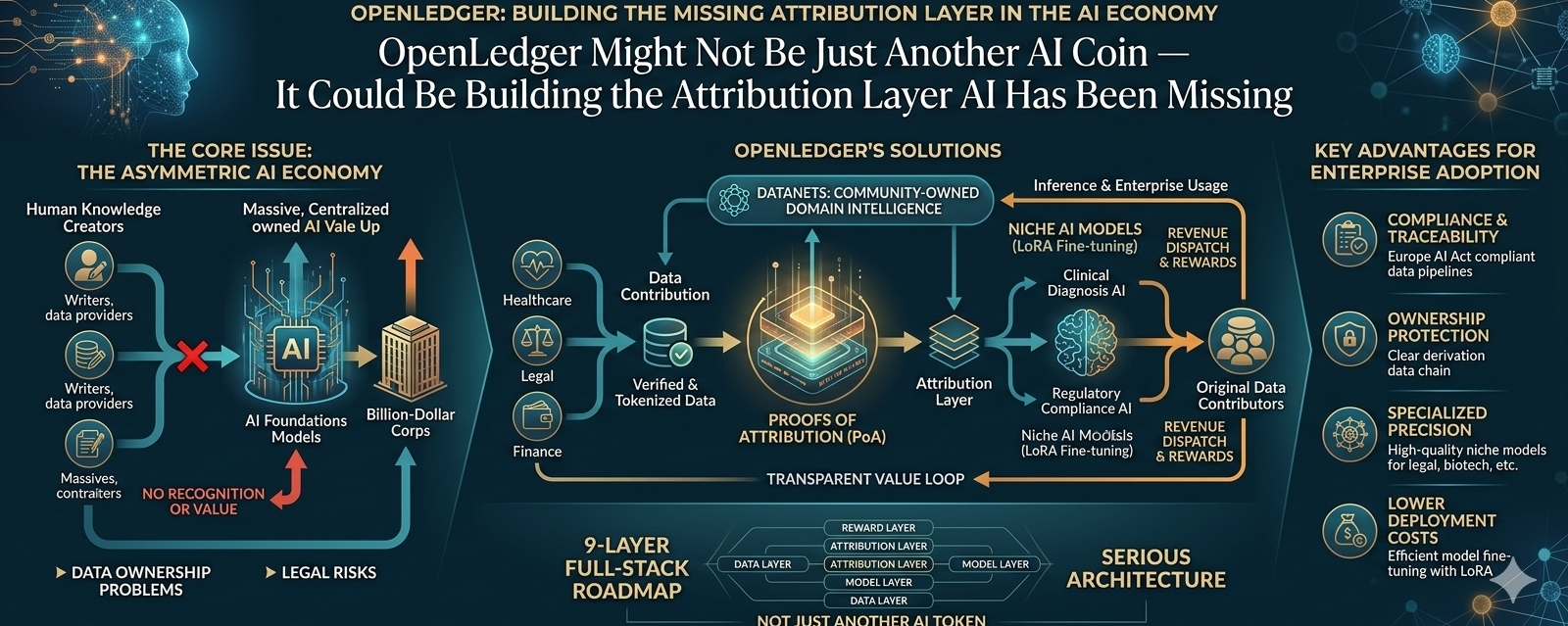
@OpenLedger At first glance, OpenLedger can easily look like another project riding the AI narrative. I had the same feeling in the beginning. These days, whenever a project combines AI with blockchain, it instantly starts sounding futuristic. But once you go deeper, many of them feel empty, like they are using big words without solving a real problem. OpenLedger started to feel different the more I looked into it, because the core issue they are targeting is not just AI hype. They are touching one of the biggest problems inside the AI economy: the people who provide data, create knowledge, build content, and contribute niche intelligence usually get nothing, while the infrastructure players use that material to build billion-dollar models. OpenLedger’s idea comes from a different angle. If AI is trained on human knowledge, then the value created by that AI should not only flow upward to large companies. Some of that value should also move back toward the people and communities that helped create the intelligence in the first place.
That sounds simple, but the execution is extremely difficult. It is easy to say “decentralized AI” or “community-owned data,” but the real challenge is attribution. Who provided the data? Which dataset helped train which model? Which model used that knowledge during inference? Who should receive revenue when an enterprise pays to use that output? These are not small questions. This is where OpenLedger’s Proof of Attribution concept becomes interesting. Imagine a future where there is a finance-focused AI model trained on verified financial datasets. If someone contributes useful financial data and later an enterprise uses that model through an API, OpenLedger wants the backend to trace which data contributed to that output and reward the correct contributors. That attribution layer may sound technical, but it is actually one of the most important missing pieces in the AI economy. The biggest issue in AI is no longer just performance. It is ownership.
This matters even more because the regulatory pressure around AI is only getting stronger. Questions like “what data was used,” “was permission given,” and “was commercial usage legal” are becoming serious. With frameworks like Europe’s AI Act pushing the industry toward more accountability, AI projects that cannot explain their data pipelines may struggle with enterprise adoption. That is why OpenLedger’s partnership with Story Protocol does not feel like a random marketing move. It looks more strategic than that. OpenLedger seems to understand that open-source AI alone is not enough for the next phase. Legal AI, compliant AI, and traceable AI may become much more important, especially when real enterprise money enters the market. Big clients do not just want innovation. They want clarity, ownership protection, and reduced legal risk.
The Datanets concept also stands out because it is not only about storing datasets. It feels more like an attempt to create community-owned domain intelligence. This is important because the future of AI will probably not be controlled by one giant general-purpose model alone. Niche AI models may become extremely valuable. Healthcare AI, legal AI, trading AI, biotech AI, research AI, and other specialized systems will need highly specific data. General models can answer broad questions, but serious industries need precision. OpenLedger is trying to build a structure where niche knowledge can be collected, verified, tokenized, and used inside specialized models while giving contributors a way to participate in the value they helped create. That is a much deeper thesis than simply launching another AI token.
Technically, this direction is becoming more realistic than it would have been a few years ago. With LoRA architecture, efficient fine-tuning, and lighter model adaptation methods, it is no longer necessary to train every model from zero with massive GPU budgets. Smaller specialized models can now be built and deployed at a lower cost compared to older AI infrastructure models. This makes OpenLedger’s vision of running thousands of fine-tuned models more believable on paper. If they can optimize that system properly, it could become a powerful direction. But this is also where the reality check begins. AI infrastructure is not easy. It is expensive, competitive, and technically unforgiving. A blockchain narrative cannot carry it forever. Revenue has to exist. Demand has to exist. Real businesses have to use it.
The biggest challenge for decentralized AI is still enterprise adoption. Builders may build, communities may contribute, and token holders may get excited, but real companies care about stability, latency, uptime, compliance, and cost. They do not want experiments when their business depends on reliable infrastructure. So OpenLedger’s long-term success will depend on two major things. First, can they actually deliver an enterprise-grade AI pipeline that performs well under real usage? Second, can their attribution system work at scale, not only in a clean demo environment but in a messy global inference economy? Small-scale proof is one thing. Handling real commercial demand, legal requirements, data contribution tracking, and revenue distribution at scale is a completely different game.
Still, OpenLedger deserves attention because at least it is trying to solve something real. Many AI tokens in the crypto market are mostly attention farming. Some talk about AI agents, some talk about autonomous economies, and some use futuristic language without showing much depth underneath. OpenLedger feels more serious because there is an actual architecture behind the narrative. Their 9-layer full-stack roadmap shows that they are not only trying to launch a token and attach AI branding to it. They are trying to build something closer to an on-chain AI operating layer, where data, attribution, models, usage, rewards, and governance can potentially connect into one system.
Of course, this does not mean success is guaranteed. There are real risks. Token economics will be difficult to balance. Buyback narratives can create short-term excitement, but long-term value needs actual revenue. Decentralized governance also sounds cleaner in theory than it works in practice. Community voting is attractive, but complicated protocol decisions are not always easy for the average holder to understand. If governance becomes messy, if attribution becomes too complex, or if enterprise demand does not arrive, the project could struggle. OpenLedger is ambitious, but ambition alone is not enough in infrastructure.
Even with those risks, the project is not boring from a builder’s perspective. There is a real thesis here. If the AI economy keeps growing, then data ownership, attribution, and revenue sharing will become increasingly important. The current model, where human knowledge is absorbed into large systems while contributors remain invisible, cannot stay unquestioned forever. OpenLedger is betting early that the next AI economy will need a transparent value layer beneath it. Maybe it fails. Maybe it pivots. Maybe it becomes part of a bigger infrastructure category that does not fully exist yet. But one thing feels clear: this does not look like just another shallow AI coin. It is trying to attack an infrastructure-level problem, and that alone makes it worth watching closely.