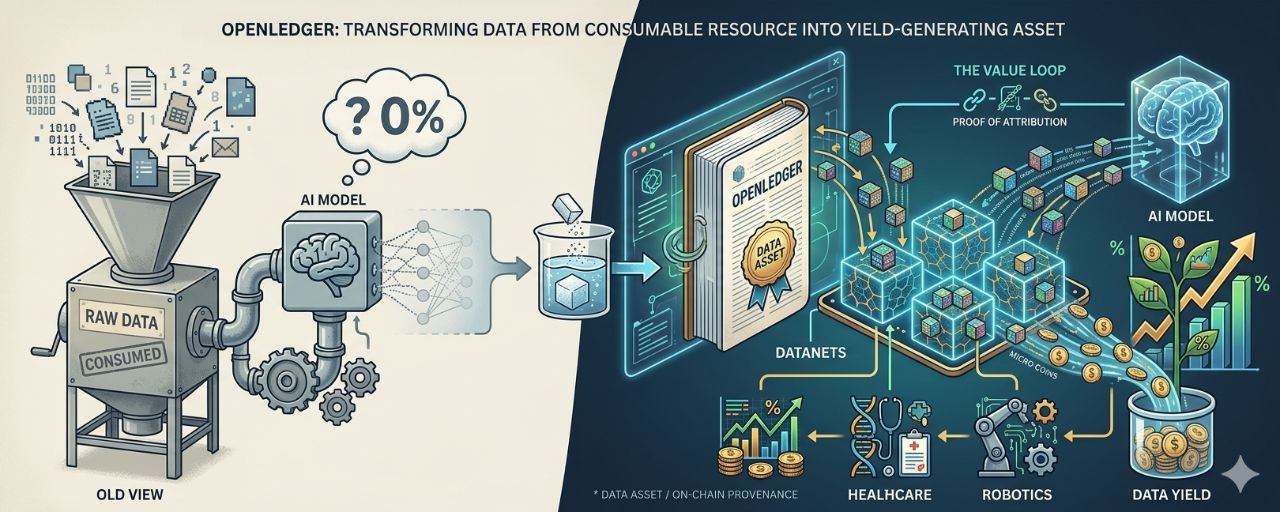
Am înțeles odată datele într-un mod foarte simplu: sunt materia primă. Modelul AI are nevoie de date pentru a învăța, iar după ce învață, datele nu mai apar nicăieri. Ele dispar în greutățile modelului, precum sarea în apă. Nu le vezi, nu le poți urmări, și cu siguranță nimeni nu se gândește să plătească pe cineva care le-a creat.
Logica asta e extrem de comună. Și extrem de problematică.
Organizația WIPO estimează că piața IP globală, care include drepturile digitale și datele, se apropie de 80 de trilioane de dolari. Cea mai mare parte a acestei valori este absorbită de companiile AI fără nicio mecanism pentru a redistribui înapoi creatorilor. Datele generează o valoare uriașă, dar într-o singură direcție.
OpenLedger pornește de la o presupunere diferită: datele nu sunt materie consumabilă. Ele sunt active. Și activele pot genera randament.
Pentru a înțelege de ce, trebuie să vorbesc despre Datanets mai întâi. În sistemul OpenLedger, atunci când contribui cu date, acestea nu intră într-un depozit anonim centralizat. Ele intră în Datanets, care sunt rețele de date comunitare folosite pentru a antrena modele specializate. La acel moment, datele tale au un proprietar clar. Au o locație. Au o proveniență înregistrată on-chain. Aceasta este prima deviere în modul în care sistemul nu mai percepe datele ca input anonim, ci ca o contribuție care poate fi urmărită.
Dar mai important este ceea ce se întâmplă în continuare.
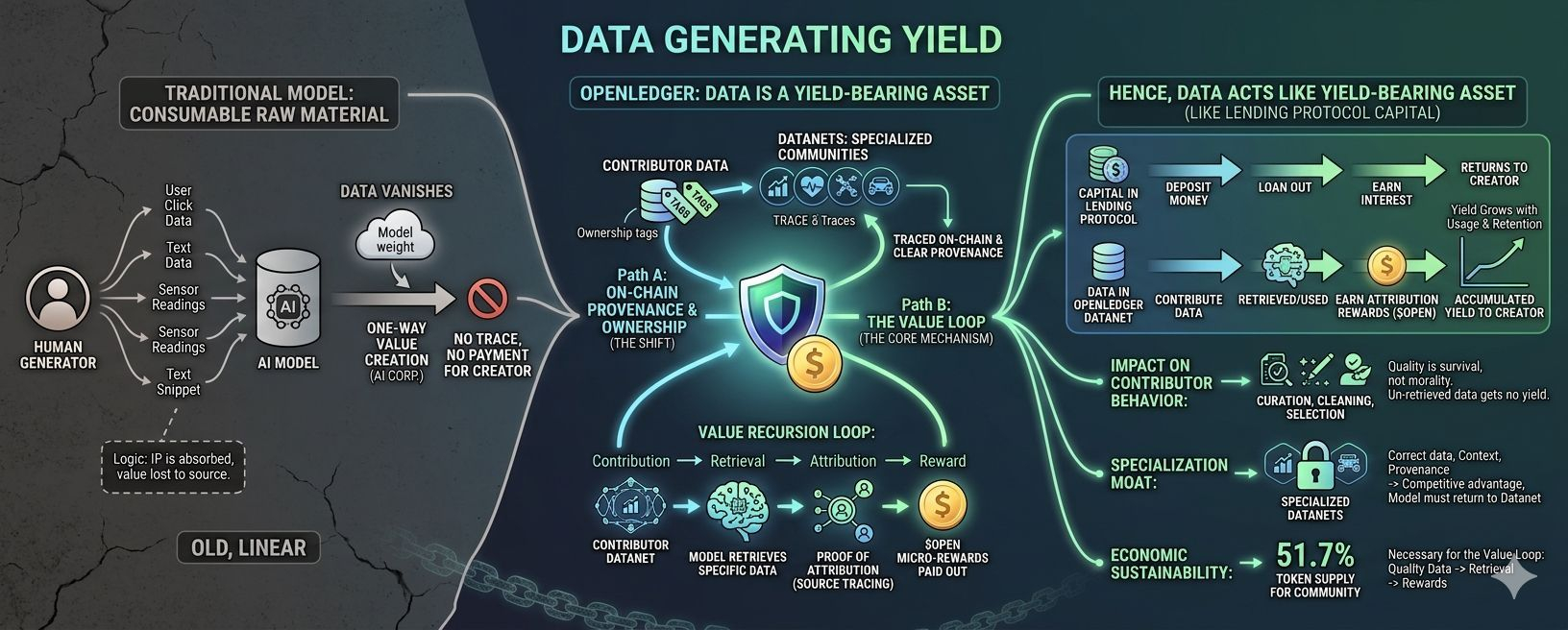
OpenLedger folosește un mecanism pe care îl numesc ciclul de regresie a valorii: contribuție → recuperare → atribuire → recompensă. Acesta nu este un singur tranzacție. Este un ciclu. De fiecare dată când datele tale sunt recuperate și utilizate în output-ul unui model, Proof of Attribution de la OpenLedger urmărește înapoi sursa, iar tu primești o micro-recompensă corespunzătoare cu influența reală a acelor date asupra output-ului. Aceasta înseamnă că valoarea datelor nu se află în momentul în care le încarci. Apare de fiecare dată când datele sunt utilizate din nou.
Aceasta este motivul pentru care datele încep să se comporte mai mult ca un activ care generează randamente decât ca materie primă.
Gândește-te în felul acesta. Când îți depui banii într-un protocol de împrumut, acei bani nu dispar. Sunt împrumutati, generează dobândă, iar dobânda curge înapoi la tine în funcție de frecvența utilizării. Datele din Datanets de la OpenLedger funcționează pe o structură similară. Datele nu dispar după prima utilizare. Continuă să existe în sistem, continuă să fie recuperate, continuă să genereze semnal de atribuire, continuă să genereze recompensă. Cu cât sunt folosite mai mult, cu atât randamentul acumulat devine mai mare.
Și aici devine interesant.
Când recompensa este legată de recuperare, comportamentul contributorilor începe să se schimbe. Nu mai încarcă doar date pentru a le avea. Încep să curate. Să curețe. Să selecteze. Să mențină datele cu o adevărată capacitate de recuperare, cu o calitate reală, cu o relevanță reală pentru domeniul pe care modelul îl deservește. Deoarece datele de calitate slabă nu sunt recuperate mult, adică nu generează randament. Calitatea nu mai este un concept moral vag. Este o condiție de supraviețuire a fluxului de venit.
Și de aici apare un concept foarte financiar: moat prin specializare.
@OpenLedger subliniază în mod special Datanets pentru domenii specializate, finanțe, sănătate, robotică, mobilitate. Când datele intră în aceste domenii restrânse, valoarea nu mai provine din cantitatea de date. Ea provine din a avea datele corecte. Datele financiare exclusive, cu tot contextul și proveniența curate, nu sunt ușor de înlocuit. Modelul care vrea să funcționeze bine în acel domeniu trebuie să revină la acel Datanet. Contributorii din acel Datanet au un fel de moat natural fără a fi nevoie să construiască ziduri sau să obțină patente.
Cred că acesta este partea cea mai puțin discutată în povestea economiei datelor.
Cel mai mult discurs actual se învârte în jurul "cine deține datele", cine are dreptul să folosească datele, cine ar trebui să fie plătit. Dar întrebarea mai profundă este: ce mecanism face ca "a fi plătit" să devină o realitate continuă și nu doar o dată unică? OpenLedger a construit ciclul de regresie a valorii ca un mecanism de infrastructură, nu ca o caracteristică UI. Fiecare interacțiune din sistem este un eveniment monetizabil pentru contributor. De aceea ei descriu tokenul $OPEN nu doar ca un token de guvernanță simplu, ci ca ceva care distribuie recompense pe baza utilizării reale în traseul de atribuire.
Conform designului lor, 51,7% din oferta totală de tokenuri este alocată comunității, legată de contribuția reală la ecosistem. Nu pentru că vor un narațiune frumoasă, ci pentru că este singura modalitate prin care ciclul de regresie a valorii poate funcționa. Dacă recompensa nu este suficientă, contributorul nu are motivația de a menține calitatea. Dacă contributorul nu menține calitatea, rata de recuperare scade. Dacă rata de recuperare scade, output-ul modelului devine slab. Întregul sistem se prăbușește.
Dar nu vreau ca acest articol să se încheie pe o notă prea optimistă.
Există o tensiune reală în acest model. Când recompensa devine clară și măsurabilă, riscul de farming apare. Oamenii pot optimiza nu pentru adevăr, ci pentru semnalul de atribuire. Încărcarea de date este proiectată pentru a fi recuperată mult, dar nu neapărat să fie cele mai bune date. Aceasta este problema cu care se confruntă orice sistem de stimulente, iar OpenLedger nu este o excepție.
Și mai este un alt punct: randamentul datelor nu este fix. Datele pot deveni depășite. Domeniul se poate schimba. Modelul antrenat pe acel Datanet poate să nu mai fie folosit. Atunci fluxul de randament se restrânge. Spre deosebire de obligațiunile guvernamentale cu cupon fix, randamentul datelor depinde de un ecosistem pe care poți controla doar o parte.
Cred că acesta este motivul pentru care afirmația "datele sunt active care generează randamente" trebuie înțeleasă mai bine ca "datele sunt active care generează randamente într-un sistem cu trasabilitate și cerere reală". Randamentul nu se află în date pe cont propriu. Se află în ciclul de regresie a valorii: contribuție corectă, recuperare suficient de frecventă, atribuire suficient de transparentă, recompensă suficientă pentru a menține comportamentul de curare.
OpenLedger nu construiește doar un blockchain cu Proof of Attribution. Se străduiește să creeze condițiile pentru ca acest ciclu să se susțină de-a lungul timpului. Dacă va reuși sau nu depinde de lucruri mult mai greu de măsurat: dacă contributorii au cu adevărat motivația de a curata pe termen lung, dacă motorul de atribuire este suficient de precis pentru a distinge calitatea datelor reale și dacă cererea pentru modelele AI specializate este suficient de mare pentru a menține Datanets întotdeauna active?
Întrebarea aceea nu am încă un răspuns.