I used to think most AI tokens were trying to borrow attention from the same place: model hype, compute demand, maybe some vague idea of decentralized intelligence. It made sense for a while. Traders like simple labels, and “AI token” is an easy one to price quickly. But the more I look at OpenLedger and $OPEN, the less comfortable I feel putting it in that bucket. Not because AI is irrelevant here. It clearly is. More because the token may be sitting closer to the accounting layer than the intelligence layer, and that changes the question completely.
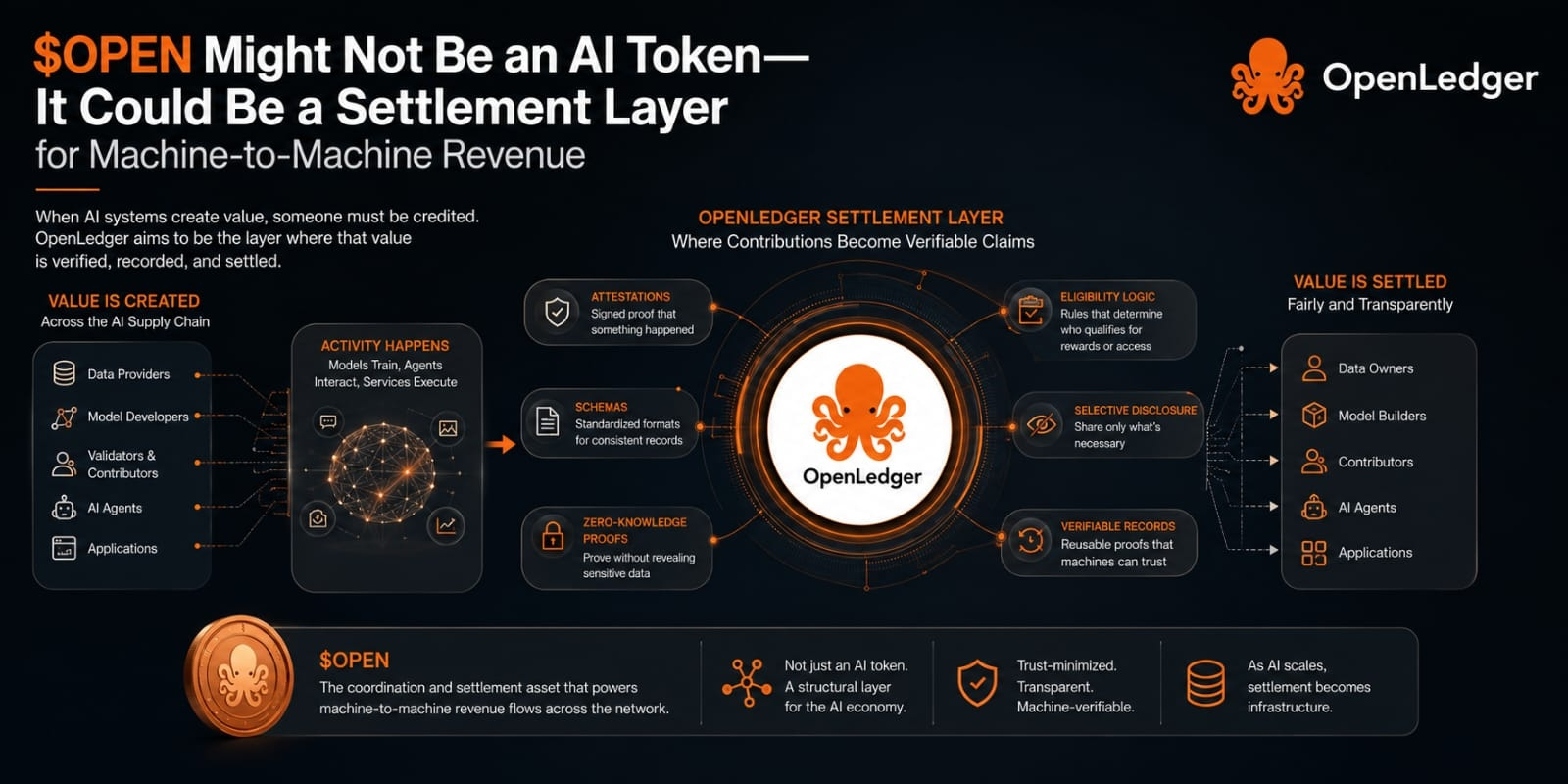
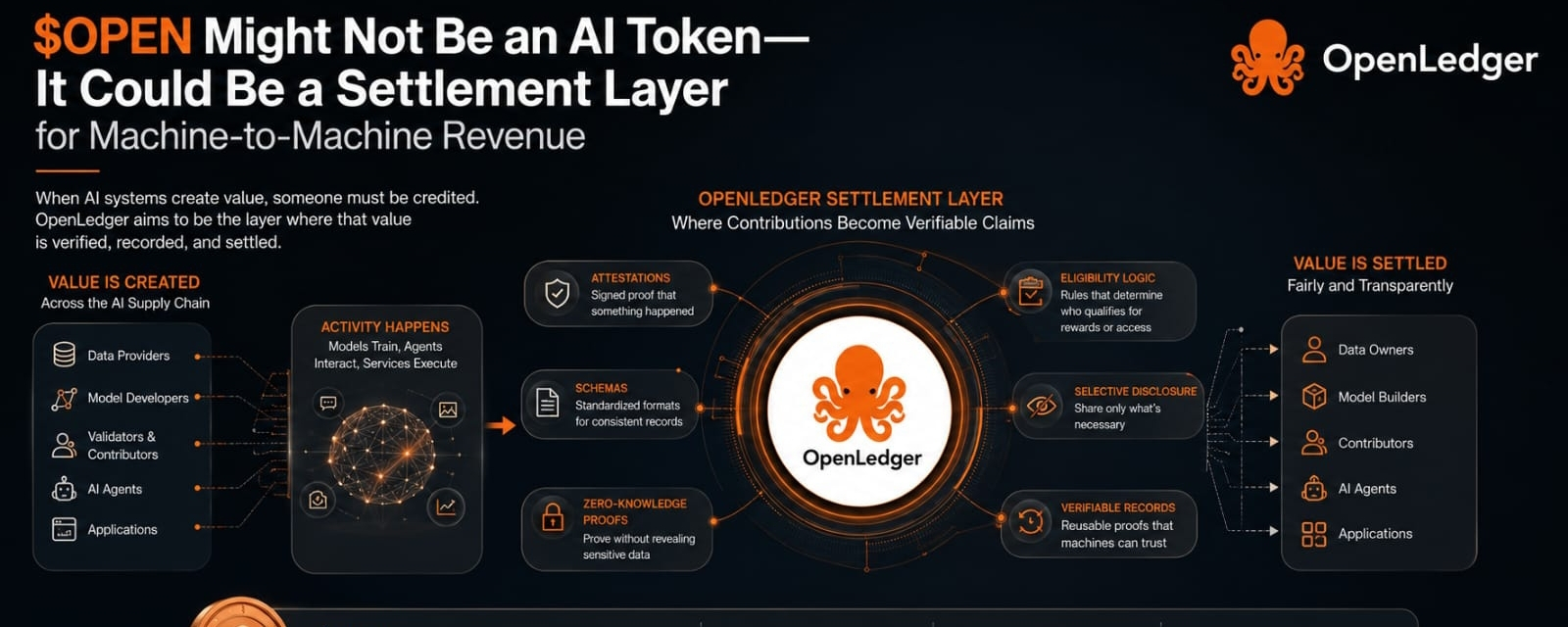
An AI model can create output, but output alone does not create a clean economy. Someone contributed data. Someone improved a dataset. Someone trained, validated, labeled, routed, or used a model in a way that produced value. In normal systems, a lot of that value disappears into the background. The platform owns the record, the user sees the result, and the contributor is usually reduced to an invisible input. OpenLedger seems to be pointing at a different problem: not just how machines generate value, but how machine-driven revenue gets attributed, verified, and settled between different participants.
That sounds abstract until you strip it down. A settlement layer is basically the place where a system decides who is owed what after activity happens. In crypto, we usually think of settlement as token transfers or final balances. But in AI networks, settlement may need to include proofs of contribution. Who supplied the data? Was it actually used? Did it improve a model? Did another agent depend on that output? These are not emotional questions. They are accounting questions. And if machine-to-machine markets grow, accounting may become more valuable than the model interface everyone is staring at.
This is where $OPEN starts to feel different from a normal “AI narrative” asset. If demand only comes from people speculating on AI growth, then it is mostly attention-driven. But if demand forms around repeated settlement events, then the token’s role becomes more structural. Machines do not care about branding. Agents, models, and applications need reliable records. They need eligibility rules, which simply means a system deciding whether a participant qualifies for payment or access. They need attestations, which are just signed claims saying something happened. They may need schemas too, which are standardized formats for recording what happened so different systems can understand the same proof.
The market often misses this distinction because usage and demand look similar at first. A network can show activity, tasks, integrations, and users, but that does not automatically mean the token is necessary. Real demand appears when the system cannot repeat its core behavior without the token or without the records the token helps coordinate. That is the harder question for $OPEN. Is it attached to AI activity as a label, or is it attached to the settlement logic underneath that activity? One is narrative exposure. The other is dependency.
I keep coming back to machine-to-machine revenue because it creates a strange pressure that human-facing apps do not always have. A person can tolerate messy records. A platform can hide complexity behind a dashboard. But machines interacting with machines need reusable proof. They cannot renegotiate trust every time. If an AI agent pays for data, uses a model, triggers a service, or routes revenue to contributors, the system needs records that survive beyond one session. This is where selective disclosure and zero-knowledge proofs may eventually matter. Selective disclosure means showing only the information needed, not the whole private record. Zero-knowledge proofs mean proving something is true without exposing all the underlying data. In AI markets, that could become useful if contributors need credit without revealing sensitive datasets.
Still, I would be careful not to overstate it. A token does not become important just because the architecture sounds intelligent. The real test is repetition. Do developers keep using the settlement layer when incentives fade? Do contributors care because revenue actually routes back to them, or only because rewards are available? Do machines and apps create recurring settlement demand, or does activity spike during campaigns and then thin out? These questions matter more than the AI label.
From a creator mindshare angle, the fresher framing may be this: OPEN is not competing to be the smartest AI asset in the room. It may be trying to become the receipt layer for AI value flows. That is less flashy, but maybe more durable if the system works. A good visual for this would not be a robot or glowing brain. I would show a revenue stream splitting between data owners, models, agents, and apps, with $OPEN sitting where claims become payable records. Boring on the surface. Important underneath.
And maybe that is why I find the topic interesting. The obvious AI trade is about intelligence becoming abundant. But OpenLedger’s deeper bet seems closer to the opposite idea: as AI output becomes easier to generate, verifiable ownership and settlement may become scarcer. If that is true, $OPEN might not be priced by how many people call it an AI token. It might be priced by whether machine economies eventually need a neutral way to remember who earned what. That part is still unproven, and honestly, that is where the tension is.