There was a moment not too long ago when I was trying to move funds during a busy evening on chain, and everything suddenly felt slower than usual. The wallet kept loading, confirmations were delayed, and every action seemed to take longer than it should have. Nothing had completely broken, but you could feel the pressure inside the network.
I remember sitting there thinking about how strange this space can be sometimes. We often talk about speed, scaling, and efficiency as if they are permanent qualities, but many systems only feel efficient when demand is low. Once activity increases, the weak points slowly start appearing.
After seeing this happen a few times across different ecosystems, I started paying more attention to infrastructure itself instead of surface level performance numbers. What matters in practice is not how fast a system looks during quiet conditions. What matters is how it behaves when thousands of tasks, users, and requests arrive at the same time.
In my experience watching networks evolve, coordination is usually the real challenge.
I think about it a lot like a shipping warehouse during peak season. If every package enters through the same checkpoint, eventually the entire workflow slows down no matter how fast the workers are moving. A good system is not just about speed. It is about organization. Which tasks get prioritized? Which processes can run separately? How does the system prevent one delay from affecting everything else?
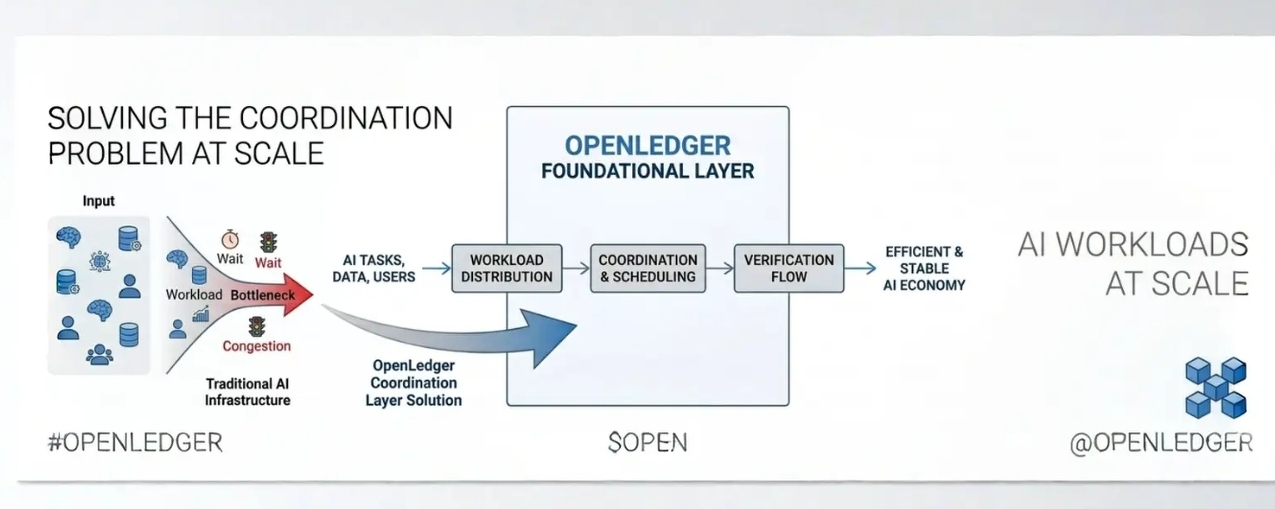
That same idea feels increasingly important as AI systems become more connected to blockchain infrastructure.
AI workloads are constant. Verification, data handling, computation, scheduling everything happens simultaneously and continuously. From a system perspective, the challenge is less about creating raw power and more about distributing workloads intelligently so congestion does not spread across the entire network.
That is honestly what made me curious about @OpenLedger
What caught my attention is how the project seems to approach infrastructure from a coordination perspective rather than purely a performance narrative. The design appears focused on how work moves through the network, how tasks are separated, and how verification can remain manageable even when activity scales.
And personally, that feels much more realistic to me.
Because most infrastructure problems do not appear dramatically at first. They start quietly. A small delay here. A synchronization issue there. Then over time, those small inefficiencies compound until the system becomes difficult to manage under pressure.
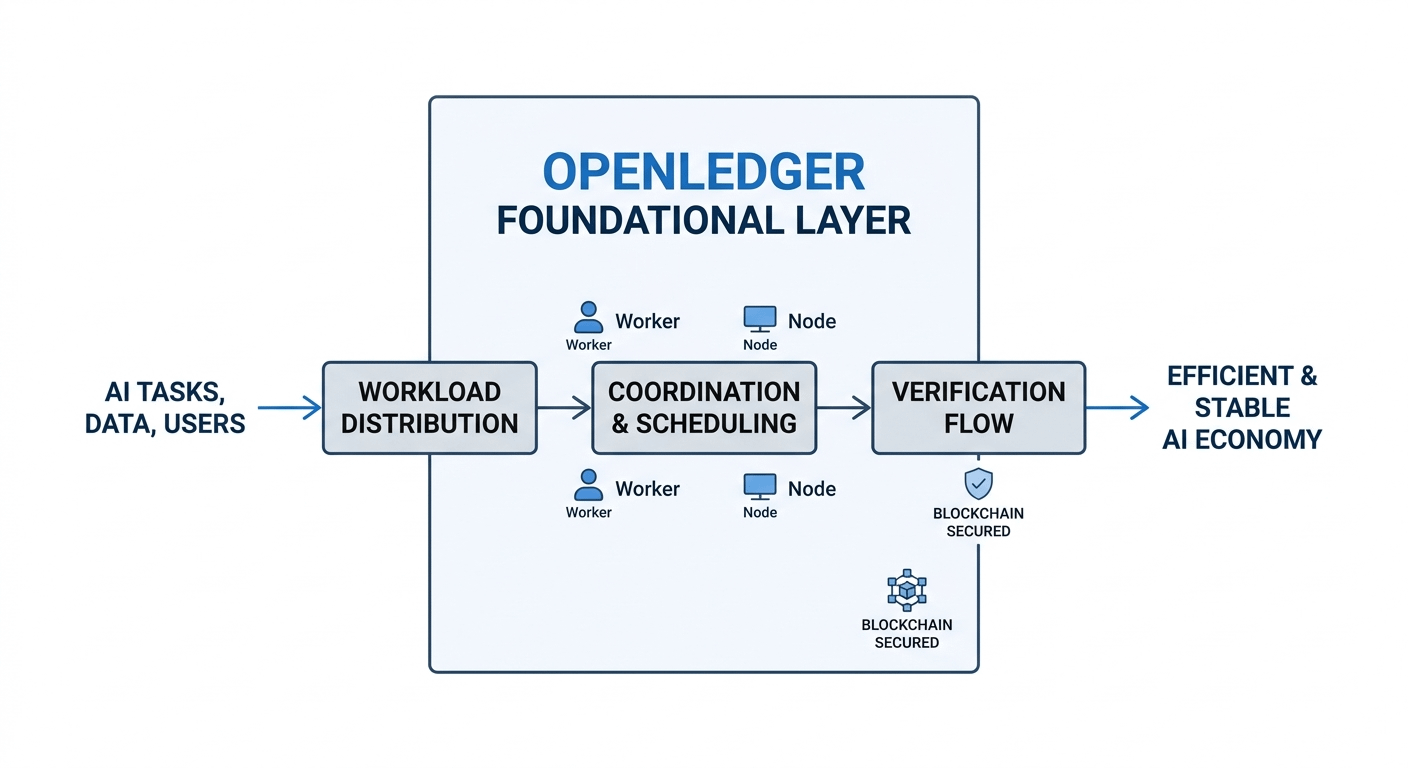
What I noticed in OpenLedger is the emphasis on workload distribution and structured processing. Scheduling logic, worker coordination, verification flow, and controlled parallelism all seem designed around reducing bottlenecks before they become systemic problems.
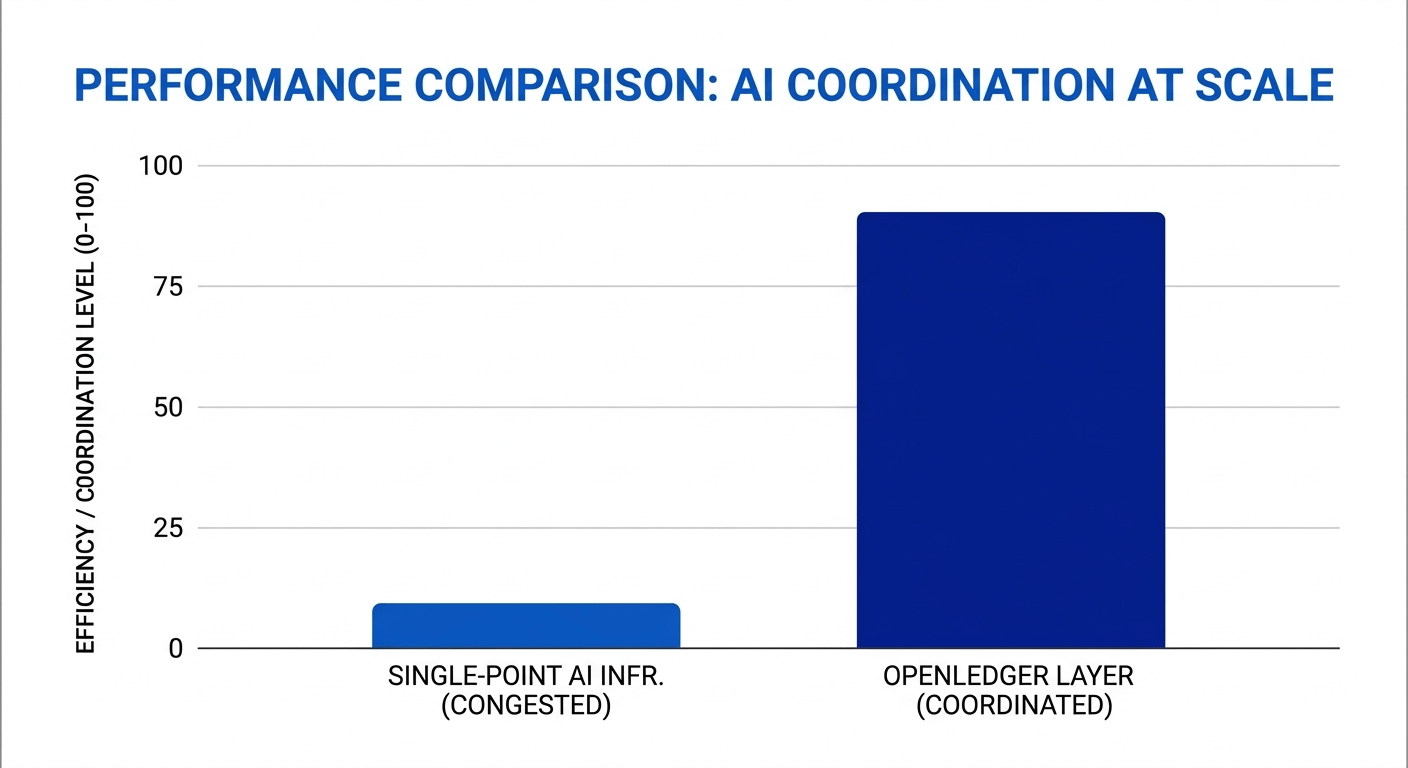
Backpressure is another thing I think about often. In weaker systems, congestion spreads everywhere once incoming demand exceeds capacity. In stronger systems, pressure gets absorbed gradually without destabilizing the whole environment.
That difference may not sound exciting on the surface, but in practice it changes everything.
Good infrastructure rarely looks dramatic. Most people never notice it when it works properly. It simply stays stable while everything around it becomes unpredictable.
And honestly, the more time I spend studying infrastructure projects, the more I feel the next stage of the AI economy will depend less on hype and more on systems that quietly solve coordination problems at scale.