
I’ve been staring at this screen for six years. I’ve watched the "AI x Crypto" narrative come and go like fashion week. First, it was decentralized compute (boring, commoditized). Then it was "ZK-ML" (too early, too nerdy). Then it was just people slapping a chatbot on a node and calling it an agent.
I was bored. Honestly, I was angry.
Because everyone missed the point. They built race cars without fuel. They built libraries with no books. They built AI marketplaces where nobody actually owned the brain.
Then I spent two weeks inside the OpenLedger litepaper and testnet logs. And I didn’t see a blockchain. I saw a funeral. The funeral of the data monopoly.
Let me walk you through the corpse. I’ll keep it street. No moonshots. No "revolutionary paradigm shifts." Just the raw mechanics of why this might be the first time I actually believe the tech matches the philosophy.
1. The Data Liquidity Layer (Stop Hoarding, Start Flowing)
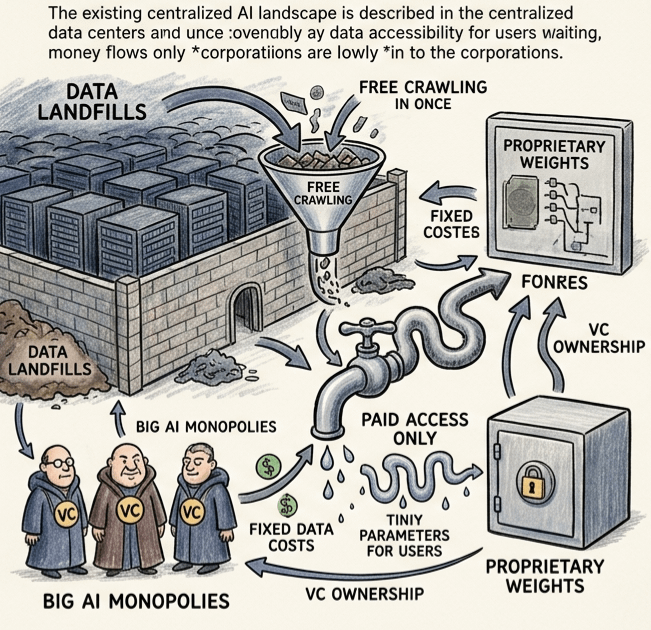
Most projects treat data like a landfill. You dump it in, you hope to mine something valuable later. OpenLedger looks at data like a river. You don't own the river. You rent the current.
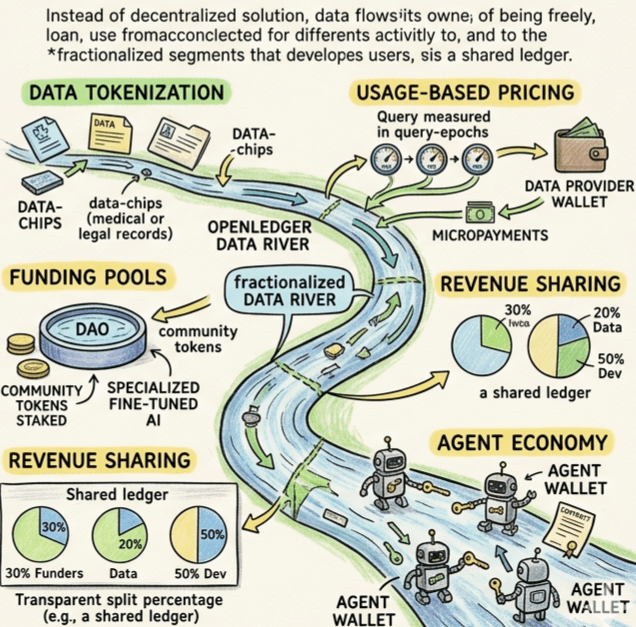
Tokenization of Data isn't an NFT gimmick here. I'm watching them turn datasets into fractionalized assets. Think about that. If I own 1% of a high-quality legal transcript dataset used to train a judge-bot, I don't just "contribute." I have a stake in the outcome. This turns data from a static file into a treasury bond. You trade slices of truth.
Usage-based Pricing is the killer. In TradFi AI, you pay for the dataset once. That's theft. OpenLedger says: you want to train your LLM on my medical records? Great. You pay per query, per epoch, per gradient descent. Micropayments for micro-usage. Suddenly, the cost of AI isn't fixed; it's variable, and it flows back to me.
On-chain Data Access is where the security nerds win. No more "trust us" APIs. You want the data? You ping the smart contract. The contract checks your stake, logs your request, and serves the hash. If you lie about usage, the network slashes you. Brutal. Efficient.
I look at this layer and I think: This is how you starve the crawlers. OpenAI scraped the open internet for free. On OpenLedger, the open internet fights back.
2. Funding AI Models (The Patreon for Parameters)
I hate venture capital. Not the people—the asymmetry. VCs fund AI, they own the weights, they charge us $20/month forever. Boring.
Decentralized AI Funding Pools feel like a DAO on steroids. You don't ask for permission. You post a proposal: "I will fine-tune a model for X-ray analysis." The community stakes tokens. If you deliver, you get paid. If you don't, you get rekt. It’s crowdfunding for cognition.
Model Training Incentives are the gym membership for developers. You get rewards not just for the final model, but for improving an existing one. You shave 2% off the loss function? Here’s a bounty. This creates a swarm intelligence. Thousands of devs nibbling at the edges of a model instead of one corporate team bulldozing through.
Revenue-sharing Models is the sentence that made me lean forward. When your funded model gets used by an agent in the wild, the fees get split. 50% to the dev. 30% to the funders. 20% to the data providers. I search for the exit valve—the place where the money gets trapped by a middleman. There isn't one.
This isn't charity. This is financial engineering that aligns ego with equity. You build a good model, you eat forever. You build a bad one, you starve. Darwin would love it.
3. The Agent Economy (When Code Gets a Wallet)
This is the freak show. The part that keeps me up at 3 AM.
Autonomous Agent Execution means you can deploy an AI agent that wakes up, checks the price of ETH, buys a dataset, fine-tunes itself, and offers a service—all while you sleep. No "approve transaction" pop-up. No human in the loop. Just a bot with a private key.
Terrifying? Yes. Necessary? Absolutely.
On-chain Activity Logging is the leash. Every decision the agent makes is scribbled into the immutable ledger. Did it lie? Did it cheat? Did it buy a dataset it wasn't supposed to? We can audit the mind of the machine. For the first time, we have interpretability not through math, but through forensic accounting.
Agent Monetization flips the script. We used to pay for software. Now the software pays us. I search the docs for how an agent earns revenue. It’s simple: Agent A holds a license for Model B. It offers a prediction service to App C. App C pays in stablecoins. Agent A uses that revenue to rent more data. It grows itself. It's a self-sustaining digital organism.
I sit back and realize: We aren't building tools anymore. We are building economic cells. And OpenLedger is the petri dish.
4. Data Ownership (The Veto Button)
Every web3 project claims "you own your data." I call bullshit. Usually, "ownership" means you can export a JSON file. Who cares?
User-controlled Data Rights here means something radical: the veto. You don't just control access. You control the terms of access. You can tell a model: "You can train on my data, but only for sentiment analysis. Not for facial recognition." That granularity is a political statement.
Programmable Data Licensing via smart contracts is the lawyer-in-a-box. You want my tweets from 2022? Sign this contract. It auto-verifies your identity, locks your payment, and gives you a cryptographic receipt. If you violate the license (e.g., use it for surveillance), the contract self-destructs the access. No court. No appeals.
Revocable Access Control is the kill switch. Right now, if I give my data to Google, it's gone forever. I can't take it back. On OpenLedger, I can flip a bit in a smart contract and say "revoke." Suddenly, every model using my data sees a 403 error. The training stops. The inference fails.
I search for the catch. The catch is compliance. But philosophically? This is the end of the "data is oil" metaphor. Oil is consumed. Data here is rented. And renters can be evicted.
5. Token Incentives (The Gravity of the Network)
You can't have a decentralized economy without sticky incentives. I’ve seen a thousand token models die because they pay for the wrong behavior.
Data Contribution Rewards aren't just "here's a token for uploading a CSV." No. You get rewards based on how much your data is used. If your dataset becomes the bedrock for the top 10 models, you get a perpetual royalty. This incentivizes quality, not quantity. Suddenly, spamming garbage data hurts you because it dilutes your reputation.
Validator Participation Incentives are for the nerds running nodes. But here, "validating" doesn't just mean ordering transactions. It means validating data provenance. Did that medical dataset actually come from a licensed hospital? Validators stake their own tokens to attest to truth. If they lie, they burn.
Network Growth Subsidy is the slow drip. Instead of a massive ICO dump, tokens are emitted continuously to users who actually use the system—querying models, hosting data, running agents. This creates a flywheel. Usage creates token value. Token value attracts more usage.
I look at the inflation schedule. It's not exponential. It's asymptotic. They are trying to build a civilization, not a casino.
6. Transparency (The Glass Cage)
I hate black boxes. I hate "proprietary algorithms." OpenLedger forces the industry to get naked.
Immutable Training Records mean that every batch, every epoch, every hyperparameter tuning is logged on-chain. Want to know if GPT-5 was trained on copyrighted books? You can trace the hashes back to the original dataset contracts. If the dataset wasn't licensed, the entire model is invalid. That's a nuclear deterrent.
Auditability of AI Models goes a step further. You can literally run a model through a verifier contract that says: "Given input X, did the model's output Y come from the claimed training path?" If the answer is no, the model gets delisted from the marketplace.
Anti-data manipulation system is the immune system. If someone tries to poison a dataset (e.g., hiding malicious code in training samples), the network's consensus mechanism flags the anomaly. Why? Because validators are economically incentivized to find fraud.
I search for a way to cheat. The only way is to control 51% of the validators. And given the staking requirements, that's nation-state territory. For a regular corporation? Impossible. The transparency is a feature, not a bug.
7. Dev Infrastructure (Stop Building Airplanes)
I’m a lazy developer. I don't want to learn a new language for every chain. OpenLedger gets this.
AI SDK/API Layer feels like Stripe for intelligence. Three lines of code to query a decentralized model. Five lines to upload a dataset and set a price. They abstract the blockchain away until you need to see it.
Decentralized Compute Integration is the engine room. They don't reinvent the wheel. They plug into Filecoin for storage, Akash for compute, EigenLayer for restaking. This is a modular strategy. If one compute provider fails, the network routes around it. No single point of failure.
Plug-and-play AI Modules are the Lego bricks. Want an embedding model? Drag and drop. Want a recommendation engine? There's a module for that. The composability means a solo dev can build what used to require a team of 20.
I spend an hour playing with the testnet SDK. It's not perfect—latency is high—but it's real. This isn't a keynote slide. It's code that compiles.
8. Model Marketplace (The App Store for Brains)
Centralized model hubs (looking at you, Hugging Face) are great for sharing. Terrible for commerce.
Model Tokenization turns a neural network into a tradeable asset. You don't just download the weights. You buy a token that represents the right to inference. This creates scarcity. If only 10,000 inference tokens exist for a high-quality model, and demand is high, the price appreciates. Models become collectibles that actually do work.
Performance-based Ranking kills the popularity contest. No more "most downloads" as a metric. The ranking is algorithmic: accuracy, latency, cost-efficiency, and honesty (how often does the model hallucinate?). Validators run benchmarks continuously. The ranking updates hourly.
Licensing Marketplace is the legal layer. Want to use a model in a commercial app? Buy a commercial license smart contract. Want just academic use? Cheaper license. Want to sublicense it to your customers? There's a royalty split built in.
I look at this and realize: We are watching the birth of software licensing 2.0. No EULAs. No lawyers. Just code.
9. Composability (The Money Legos of AI)
This is where I get philosophical. Composability is the secret sauce of DeFi. OpenLedger applies it to intelligence.
Modular AI Stack means data, models, and agents are independent. You can swap out the data source without retraining the model. You can swap the model without rebuilding the agent. It's like a UNIX pipe for AI. cat data.csv | model infer | agent execute.
Cross-app interoperability is the network effect. If I license a dataset on App A, that license is valid on App B, because the license is a smart contract, not a database entry. The data flows wherever the contract allows.
Composable Revenue Streams is the magic. An agent can earn revenue from query fees, data licensing fees, model sublicensing fees, and validator rewards—all flowing into the same wallet, all traceable on the same ledger.
I search for the limit. The limit is gas costs. But with L2s and data availability sampling, even that is shrinking. The Lego tower keeps growing.
10. Reducing AI Monopoly (The Great Decoupling)
Let me be blunt. OpenAI, Google, Anthropic—they are feudal lords. They own the land (compute), the seeds (data), and the crops (models).
Decentralized Data Control seizes the means of production. Your data stays on your node, under your key. The models come to the data, not the other way around. This reverses the power gradient.
Open AI Infrastructure Access means no API keys that can be revoked. No rate limits because a CEO had a bad day. The infrastructure is a public good, maintained by stakers, governed by token holders.
Compute Democratization is the hardest nut to crack. Nvidia owns the shovels. OpenLedger doesn't pretend to solve this. But they reduce reliance by aggregating disparate compute sources. Consumer GPUs. Data center leftovers. Edge devices. It's not perfect, but it's resilient.
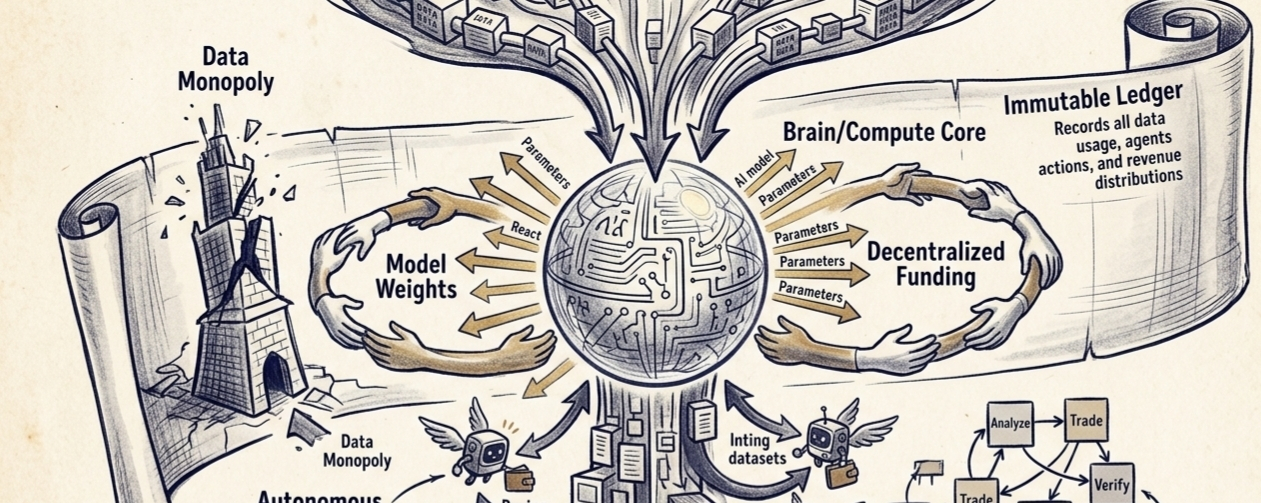
I look at the three layers—Data, Model, Agent—and I realize: This is a parallel economy. Not a competitor to Big AI. An alternative. And alternatives are dangerous.
The Deep Summary (What I Actually Think)
OpenLedger isn't a blockchain project. It's a political movement disguised as infrastructure.
Most people see "AI on blockchain" and yawn. They shouldn't. Because OpenLedger solves the three fundamental contradictions of the AI age:
The Data Paradox: The more valuable data becomes, the less people want to share it. OpenLedger solves this by turning sharing into leasing. You don't lose your data. You rent it. And you get paid. The Model Monoculture: Today, we have five models. Tomorrow, we need five million. OpenLedger incentivizes niche, specialized, highly-auditable models over monolithic black boxes. The Agent Alignment Problem: How do you trust a bot with your money? You don't. You trust the ledger that records every decision the bot makes.
I've been in this space long enough to smell vaporware. This isn't vapor. It's wetware—the messy, organic, chaotic collision of markets and minds.
Will it work? I don't know. The UX needs work. The compute costs are real. But the direction is correct.
For the first time in a long time, I'm not just watching. I'm searching for a place to stake. Because when the data wakes up, it won't ask for permission.
It'll ask for a contract.
And OpenLedger is writing the terms.
