

I spent three weeks labeling a dataset once.
Domain-specific annotations.
Edge cases that needed actual judgment to classify correctly.
The kind of work that genuinely improves a model in a narrow field.
When the fine-tuned version shipped, the improvement was obvious.
I received nothing.
Not because anyone was malicious.
Because there was no mechanism connecting what I contributed to what the model eventually produced.
The influence existed.
The trail didn't.
That part stayed with me longer than I expected.
Not even the payment.
The absence of proof.
I couldn't show that my annotations shaped any specific output.
The model learned from the data.
The data disappeared into training.
And I was left with no claim on what came out the other side.
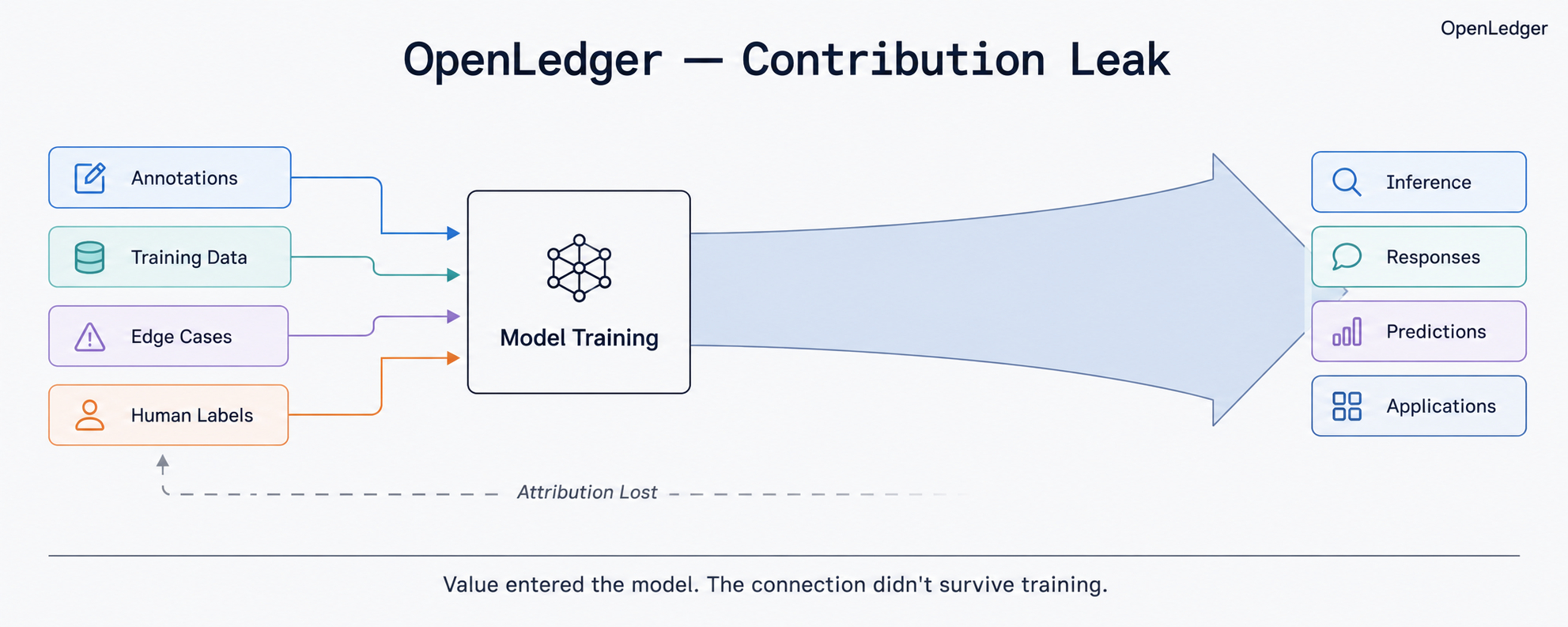
I keep thinking of that as contribution leak.
Value created at the input.
Value captured at the output.
Nothing routing the connection back to the person who made the output possible.
That's how most AI training still works.
Datasets get aggregated.
Models get trained.
Inference runs at scale.
Somewhere inside every response is the fingerprint of contributors whose work shaped the model.
Most of them never see where the value went after the upload finished.
The people who understand this best usually stop contributing openly first.
They keep their strongest datasets private.
Or they contribute anyway knowing the upside disappears the moment training starts.
That's the part that quietly weakens open AI systems over time.
The highest-quality contributors are usually the least willing to work for invisible upside forever.
Proof of Attribution is OpenLedger's attempt to close that leak.
Not socially.
Mechanically.
PoA traces which training data influenced which outputs and routes attribution rewards back through the network when inference happens.
The connection usually disappears after training.
PoA keeps it attached.
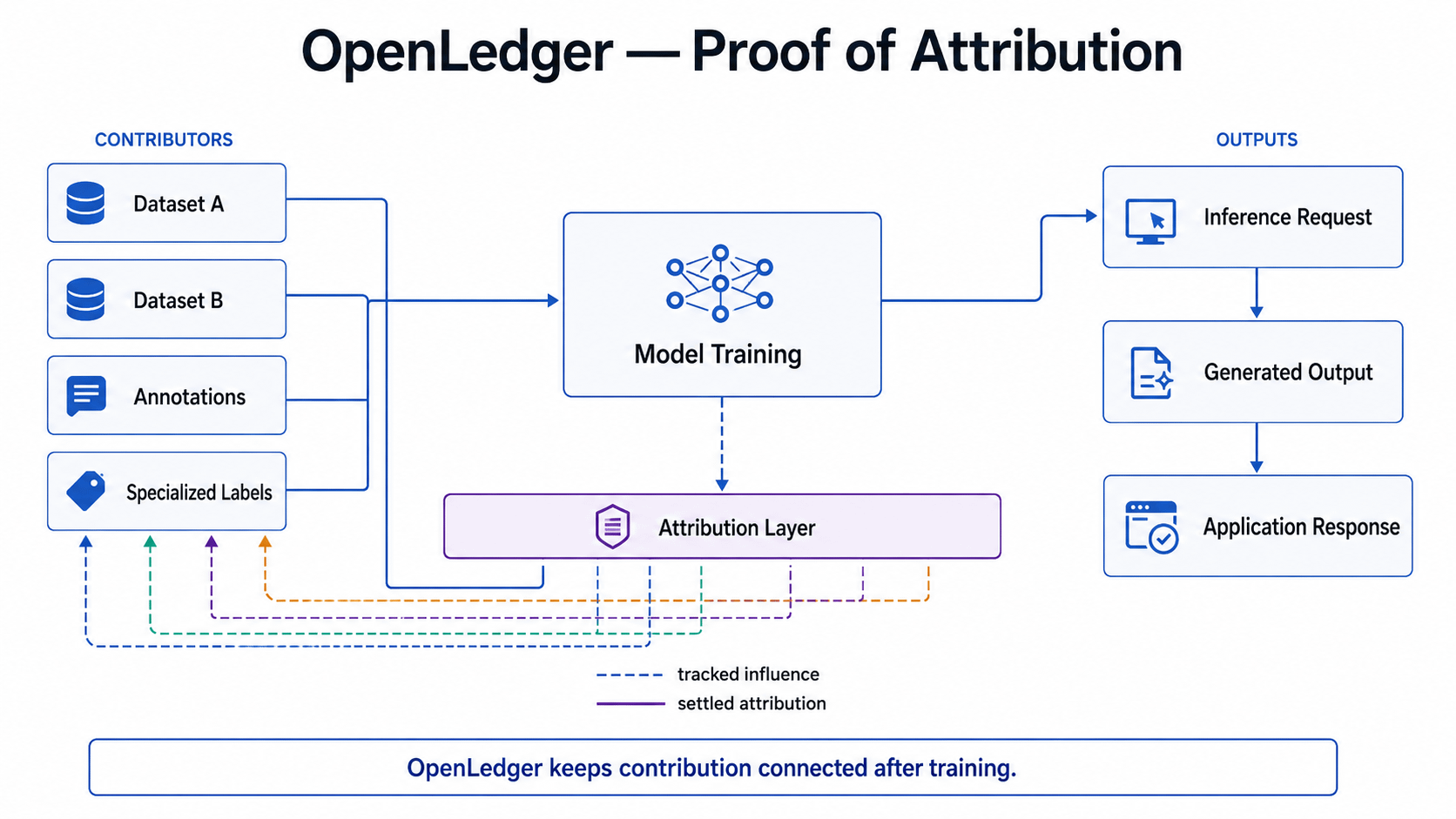
That changes the economics of contributing entirely.
If attribution actually holds, uploading useful data stops being charity.
It becomes an asset that can continue generating value after the model ships.
That's where $OPEN sits mechanically inside the system.
Inference activity triggering attribution events requires settlement through $OPEN.
The more models actually get used, the more attribution events have to settle somewhere.
More attribution flow means contributors have a reason to keep supplying high-quality data instead of withdrawing it behind private agreements.
But the real question isn't whether PoA works conceptually.
It's whether the attribution trail still holds once models reach production scale.
Small models are one thing.
Production LLMs processing millions of outputs every day are something else entirely.
If attribution becomes too expensive or too computationally heavy at scale, contribution leak still exists.
It just gets delayed.
If OpenLedger solves that cleanly, the relationship between AI models and contributors changes completely.
Because for the first time, the people improving the model would still remain connected to the value leaving it.