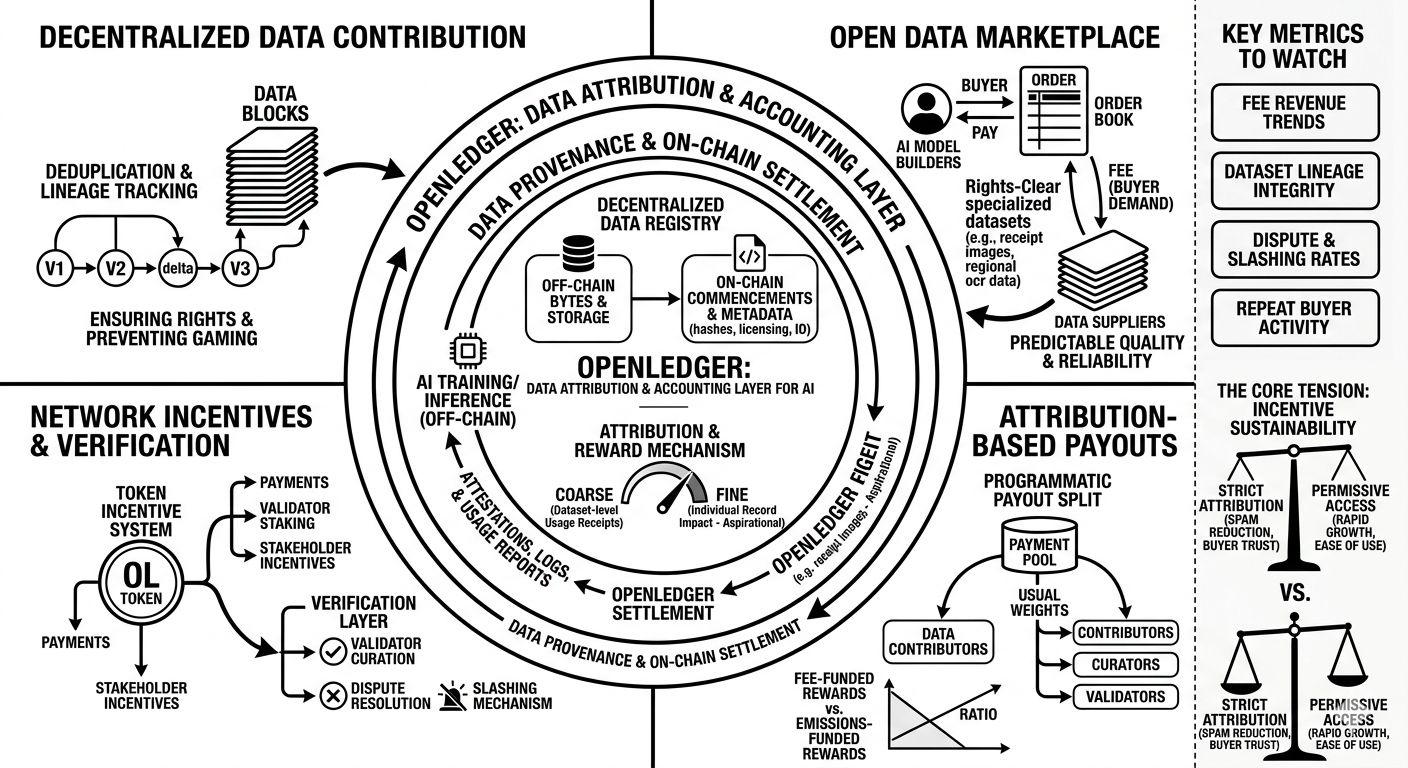
been going through openledger’s architecture diagrams and a few of the incentive writeups, and i’m noticing i keep reading it less like a “decentralized dataset dropbox” and more like an attempt to build a shared accounting layer for ai inputs. what caught my attention is that openledger talks a lot about attribution and contributor payouts as if those are the protocol’s core outputs, not just a nice-to-have. and that immediately raises the question: can attribution be made robust enough that buyers don’t treat it as optional?
most people think openledger is just another ai + crypto token where you upload data and earn rewards. honestly, that’s the fastest way to file it away. but if you take their long-term network design seriously, the bet is more specific: connect off-chain model training / inference to on-chain settlement so that “data provenance + payment routing” becomes composable across many model builders and apps (instead of one centralized platform doing private ledgers and payouts behind the scenes).
the pieces that feel most important to me right now:
decentralized data contribution system (the registry is the product)
openledger seems to separate the bytes from the commitments: data sits off-chain, while on-chain you store hashes/roots, metadata, licensing, and contribution identities. that part is sane. the tricky part is the contribution pipeline: versioning, deduplication, and rights management. data isn’t static, and a lot of value is in the “delta” (new labels, corrected annotations, refreshed distributions). i’m curious how openledger represents lineage over time—if you can’t track dataset evolution cleanly, attribution becomes a mess later.attribution + reward mechanism (coarse vs fine attribution)
and this is the part i keep thinking about. there’s an attractive but unrealistic version where every individual record has measurable marginal impact on model quality. then there’s the version that might actually ship: dataset-level attribution based on usage receipts (“this run used dataset A v7 and dataset B v2”), with payouts split according to some declared weights. the coarse version is still useful, but it makes enforcement and anti-gaming the whole ballgame. if someone repackages the same dataset ten ways, or subtly overlaps tranches, do they get paid ten times? dedup and similarity checks become economic security work, not just data hygiene.marketplace dynamics (who pays, and for what outcome)
openledger’s economics only really stabilize if buyers pay fees for data/model access, not if contributors are mostly rewarded by emissions. a realistic example: a small dev team building an on-device ocr model for retail receipts might need a steady stream of region-specific receipt images plus ground-truth text. centralized sources exist, but they tend to be opaque on provenance, and the pricing is basically “take it or leave it.” openledger’s promise is that buyers can source from many contributors, with clearer rights and a programmatic payout split. i can see why that’s appealing, but buyers will demand reliability: consistent formatting, predictable quality, and low legal risk.token incentives + verification/scalability layer (where “trust” sneaks back in)
tokens are doing multiple jobs: paying contributors, incentivizing validators/curators, and settling usage-based rewards. the verification path matters a lot here. training and inference happen off-chain, so the chain only sees attestations: signed manifests, metered usage logs, maybe third-party audits. if openledger ends up depending on a small set of metering providers to produce “truth,” it may still work, but it changes the decentralization story. also, micro-royalties per inference don’t feel practical without batching—so you’re probably looking at off-chain accounting with periodic on-chain settlement.
zooming out: who actually creates value? it’s contributors who can deliver scarce, rights-clear data; curators who keep spam and poisoning out; and buyers who bring external fee revenue. openledger assumes ai demand will keep fragmenting into specialized models that need continuous data refreshes. plausible, but not guaranteed—some teams may lean harder on synthetic data or closed partnerships, which reduces the addressable “open marketplace” spend.
the tension is incentive sustainability. if early rewards are emissions-heavy, the network can grow supply without real demand discipline. that’s when you see spam uploads, duplicated corpora, low-effort labeling, and “wash usage” where activity is simulated to capture rewards. and if attribution can’t be audited cheaply at scale, serious buyers might route around it: they’ll buy data, but won’t report usage honestly unless it’s enforced.
no perfect conclusion. i’m still trying to decide if openledger can become a durable coordination layer, or if it’s mainly a token-incentivized attempt to front-run a demand curve that may arrive later (or not).
watching:
fee-funded rewards vs emissions-funded rewards (trend over quarters)
dedup/similarity metrics and dataset lineage integrity over time
dispute rates and whether slashing/enforcement is actually used
repeat buyers paying for multiple training cycles (not just pilots)
if openledger had to compromise, would it rather be strict (and risk friction) or permissive (and risk spam)? i’m not sure there’s a middle path that holds up once real money shows up.