For years, people have been told that data is valuable.
That line is everywhere now. Companies say it. Investors say it. Governments say it. AI teams say it. But for most people, the value of data has always been something they hear about from a distance. Their data helps platforms grow. It helps algorithms improve. It helps products become smarter. Yet the person or community that created the data rarely sees much of that value come back.
That is the strange thing about data ownership today. It often sounds powerful, but in practice it can be passive. You may own your data in some legal or technical sense, but that does not mean it works for you. It does not mean it earns. It does not mean you are credited when it improves a model, trains an AI system, or becomes part of a product someone else sells.
OpenLedger is built around a different idea: data should not just be something people own. It should be something they can actively monetize.
That difference matters.
Owning something and earning from something are not the same. A person can own a piece of land and do nothing with it. But if that land grows crops, hosts a business, or produces rent, it becomes active. It participates in an economy. Data has mostly been stuck in the first category. It exists. It is stored. It is collected. It is protected sometimes. But it rarely becomes an income-generating asset for the person who created it.
AI is making this problem harder to ignore.
Modern AI systems are hungry for data. They learn from documents, code, conversations, images, labels, research, feedback, professional knowledge, and countless small human contributions. A single comment may not seem important. A single correction may feel ordinary. But when millions of these pieces are gathered together, they become the raw material for systems that can write, reason, search, summarize, predict, and act.
The issue is not that data has no value. The issue is that the value usually moves away from its source.
A writer publishes useful explanations. A developer posts code. A doctor contributes medical knowledge. A community spends years answering niche questions. A researcher organizes information that others rely on. Later, an AI model may benefit from all of that. The model becomes useful. A product is built around it. Revenue appears somewhere at the top of the chain.
But the original contributors are often invisible.
OpenLedger is trying to make that chain visible.
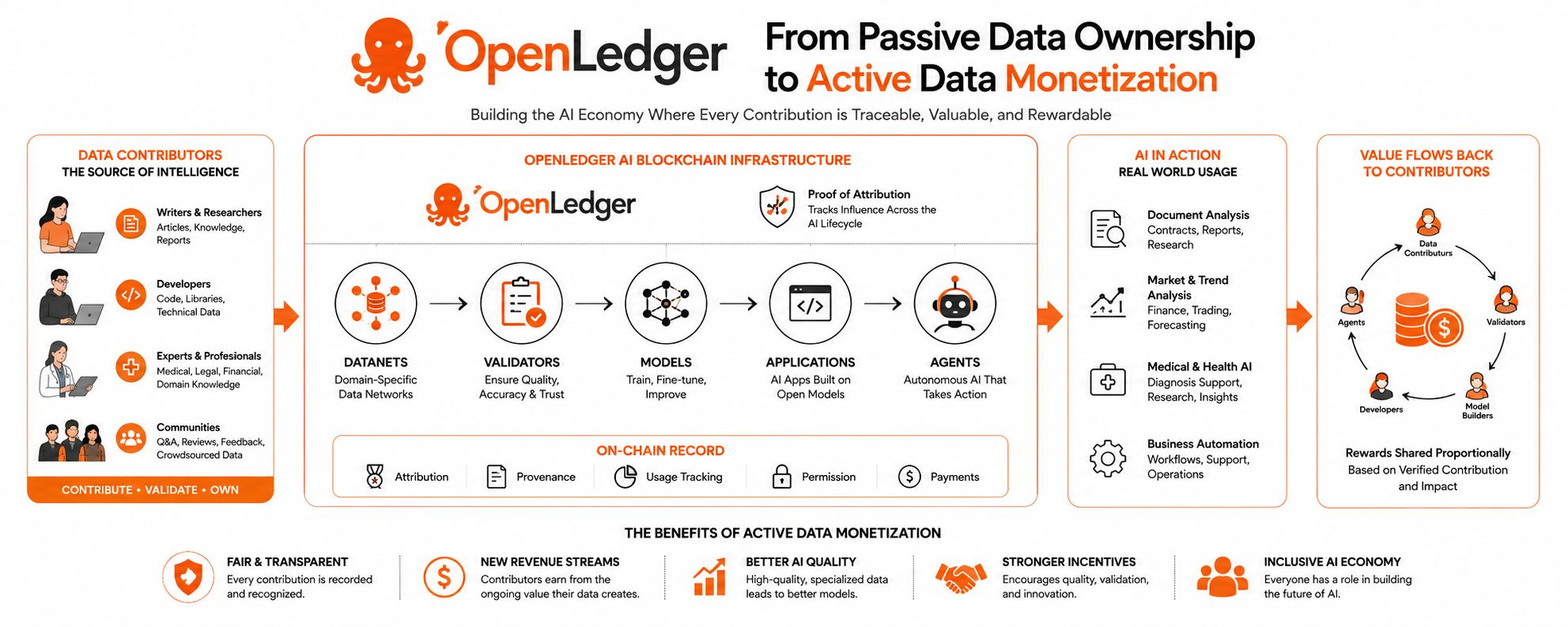
At its core, OpenLedger is an AI-focused blockchain designed to connect data, models, applications, and agents in a way that makes contribution traceable and rewardable. That may sound technical, but the basic idea is simple: when data helps create value, the system should be able to recognize where that value came from.
This is where OpenLedger’s idea of attribution becomes important.
In today’s AI world, attribution is weak. Once data is absorbed into a training process, it often loses its identity. The model may become better because of that data, but nobody can easily point back and say, “This contribution helped.” Without that link, fair payment becomes almost impossible.
OpenLedger wants to build that link into the system.
Its Proof of Attribution approach is meant to track the influence of data and other contributions across the AI lifecycle. That includes datasets, models, applications, and eventually agents. Instead of treating data as something that disappears after it is used, OpenLedger treats it as something that can keep a record, keep a connection, and potentially keep earning.
That is a major shift in how data is understood.
Passive data ownership is mostly defensive. It asks: Who can access my data? Who can copy it? Who can use it? Those questions are still important. But active data monetization asks something more forward-looking: If my data helps create value, how do I participate in that value?
That question is especially important for specialized AI.
Not every useful AI model needs to be enormous. Some of the most valuable models in the future may be smaller, more focused, and trained on high-quality data from specific fields. A legal AI model needs reliable legal data. A medical AI model needs trusted medical information. A cybersecurity model needs relevant threat data. A finance model needs structured market knowledge and domain expertise.
In these cases, quality matters more than size.
A carefully reviewed medical dataset can be more useful than millions of random web pages. A clean legal dataset can be more valuable to a legal model than a broad internet scrape. A small group of experts may produce data that is far more useful than a large amount of low-quality material.
This is why OpenLedger’s focus on specialized data networks is interesting. Its Datanets are designed to collect and organize data around specific domains. Instead of throwing all information into one giant pool, Datanets give structure to data. They make it easier to build models for real use cases, where accuracy and context matter.
That structure also changes the role of contributors.
A contributor is no longer just a user uploading information. A contributor becomes part of the supply chain of intelligence. A validator who checks data quality also plays a real role. A developer who builds or fine-tunes a model adds another layer of value. An application that uses the model creates demand. An agent that calls the model may create repeated usage.
OpenLedger’s larger vision is to connect these layers so value can move through them more fairly.
Think of it this way. If someone contributes a useful dataset, and that dataset helps train a model, and that model is used by an AI application, then the dataset did not stop being valuable after training. It may continue to support outputs again and again. In a better system, the contributor should not be paid only once, or not at all. They should have a way to share in the ongoing value their contribution helps create.
That is the promise of active data monetization.
It is not about pretending every piece of data is priceless. It is not about paying everyone for every tiny action online. That would be unrealistic. Some data is low quality. Some data is duplicated. Some data is useless. Some data should not be used. A serious monetization system has to care about quality, permission, context, and actual impact.
OpenLedger’s idea becomes meaningful only if rewards are tied to usefulness.
The strongest version of this model would reward data that improves AI performance, supports accurate outputs, or serves real demand. It would make verified, specialized, high-quality data more valuable than random volume. That matters because one of the biggest problems in AI is not simply getting more data. It is getting better data.
This is also where blockchain becomes relevant.
A blockchain does not automatically make AI better. It does not magically solve data quality or fairness. But it can help record ownership, usage, payments, and provenance in a way that is harder to hide or rewrite. For OpenLedger, the blockchain is not the main story by itself. The main story is the economic memory it can provide.
AI needs memory about where its value comes from.
Without that memory, everything becomes blurred. Data providers are forgotten. Model builders are separated from the datasets they rely on. Validators are treated like background workers. Applications capture value without showing the full chain behind them. The final product looks intelligent, but the sources of that intelligence are hidden.
OpenLedger is trying to bring those sources back into view.
This becomes even more important as AI agents become more common. Agents are not just chatbots. They can take actions, call tools, use models, make decisions, and interact with other systems. In the future, an AI agent might use a specialized model to review a contract, analyze a market, check a medical document, or complete a business workflow.
When that happens, there may be many layers behind a single answer.
The agent uses an application.
The application uses a model.
The model depends on a dataset.
The dataset was contributed and validated by people.
The final user pays for the result.
If that whole chain can be tracked, then value can be shared across it. If it cannot be tracked, the money will likely stay with whoever owns the final interface.
That is the difference OpenLedger is trying to make.
Of course, the idea is easier to describe than to execute. Attribution in AI is complicated. A model may be influenced by thousands or millions of data points. It is not always obvious which one mattered. People may try to game the reward system. Poor-quality data may be uploaded for profit. Validators may disagree. Token rewards may fluctuate. Developers may only participate if the tools are easy and the demand is real.
So OpenLedger should not be viewed as a finished solution to every problem in AI monetization. It is better understood as an attempt to build infrastructure for a problem that is becoming more urgent.
That problem is simple: AI is creating huge value from human and community contributions, but the economic system around those contributions is still weak.
The old internet trained people to give data away in exchange for convenience. Free platforms, free tools, free accounts, free reach. The hidden cost was that user activity became the fuel for large businesses. AI takes that pattern further because it does not only use data to target ads or recommend content. It uses data to build intelligence.
That makes the question of compensation much bigger.
If a community spends years building a knowledge base, should an AI company be able to absorb that knowledge without returning anything? If experts contribute high-quality information, should they have a way to earn from the models that depend on it? If data becomes a productive asset, should ownership include the right to participate in future value?
OpenLedger’s answer is yes.
Not in a loud or simplistic way. The idea is not that every internet user will suddenly become rich from their data. That kind of promise would be empty. The more realistic idea is that high-value data, especially specialized and verified data, can become part of a working marketplace. It can be contributed with clearer ownership. It can be used in model training. It can be tracked. It can earn when it helps create value.
That would be a meaningful improvement over the current system.
It would also create better incentives. If people are rewarded for useful, reliable data, they have a reason to provide better material. If validators are rewarded for keeping quality high, models can become more trustworthy. If developers can access cleaner datasets with clearer rights, they can build more focused AI tools. If users can see where model intelligence comes from, trust may improve.
The real opportunity is not only financial. It is structural.
OpenLedger is trying to redesign the relationship between data and value. In the old model, data moved upward into platforms. In the new model, data could move through networks. It could remain connected to its source. It could support models, applications, and agents while still carrying attribution. It could become less like raw material that gets consumed and more like an asset that keeps participating.
That is why the shift from passive ownership to active monetization matters.
Passive ownership leaves contributors on the edge of the AI economy. Active monetization brings them closer to the center. It says that the people who create useful inputs should not disappear once those inputs become profitable. It says that intelligence has a supply chain, and that supply chain deserves to be visible.
OpenLedger may or may not become the dominant infrastructure for this shift. That will depend on adoption, usability, trust, data quality, developer activity, and whether the economics work in practice. But the problem it is addressing is real.
AI is forcing the world to rethink what data is.
It is no longer just something stored in databases. It is no longer just something platforms collect. It is no longer just a privacy concern or a compliance issue. In the age of AI, data is productive. It teaches. It improves systems. It shapes outputs. It creates commercial value.
And when something creates value, people eventually ask who should benefit from it.
OpenLedger’s vision is built around that question. It imagines a future where data contributors, model builders, validators, developers, and agents are part of a shared economy rather than disconnected pieces of a hidden pipeline. It tries to give AI a clearer record of contribution and a better way to reward the people behind it.
That is the deeper meaning of active data monetization.
It is not just about turning data into money. It is about making contribution visible. It is about giving useful knowledge a path to participate in the systems it helps build. It is about moving away from extraction and toward a more accountable AI economy.
For a long time, people created the internet’s knowledge layer without much control over how it was used.
OpenLedger is part of a new conversation: what happens if that knowledge does not just sit there, get scraped, and disappear into models?
What happens if it can be traced?
What happens if it can earn?
What happens if the people who help create AI’s intelligence are no longer treated as invisible?
That is where the shift begins.
