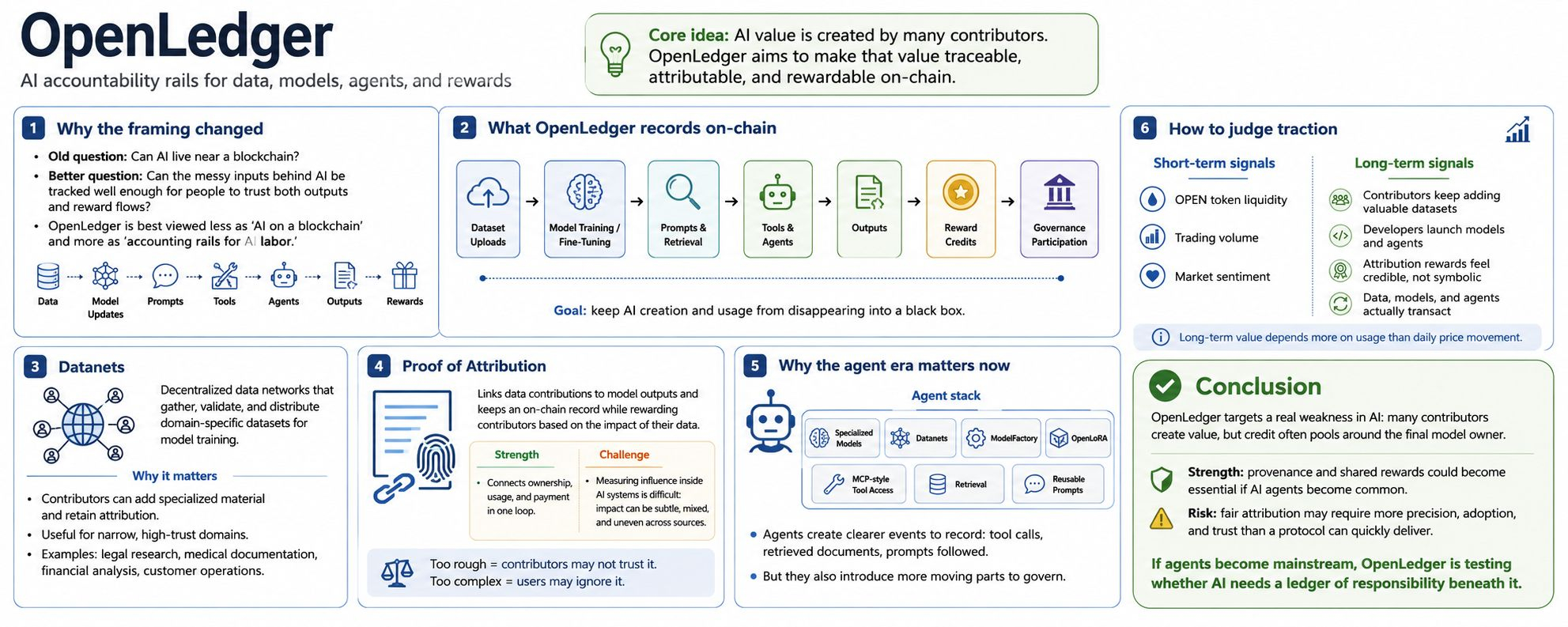

I used to think the hard part of on-chain AI was proving that a model could live near a blockchain at all. My view has shifted because with OpenLedger the better question is whether the messy inputs behind AI can be tracked well enough that people trust both the output and the reward path. Those inputs include data and model changes and prompts and tools and later agents. OpenLedger describes itself as AI-blockchain infrastructure for training and deploying specialized models through community-owned datasets where uploads and model training and reward credits and governance participation are recorded on-chain.
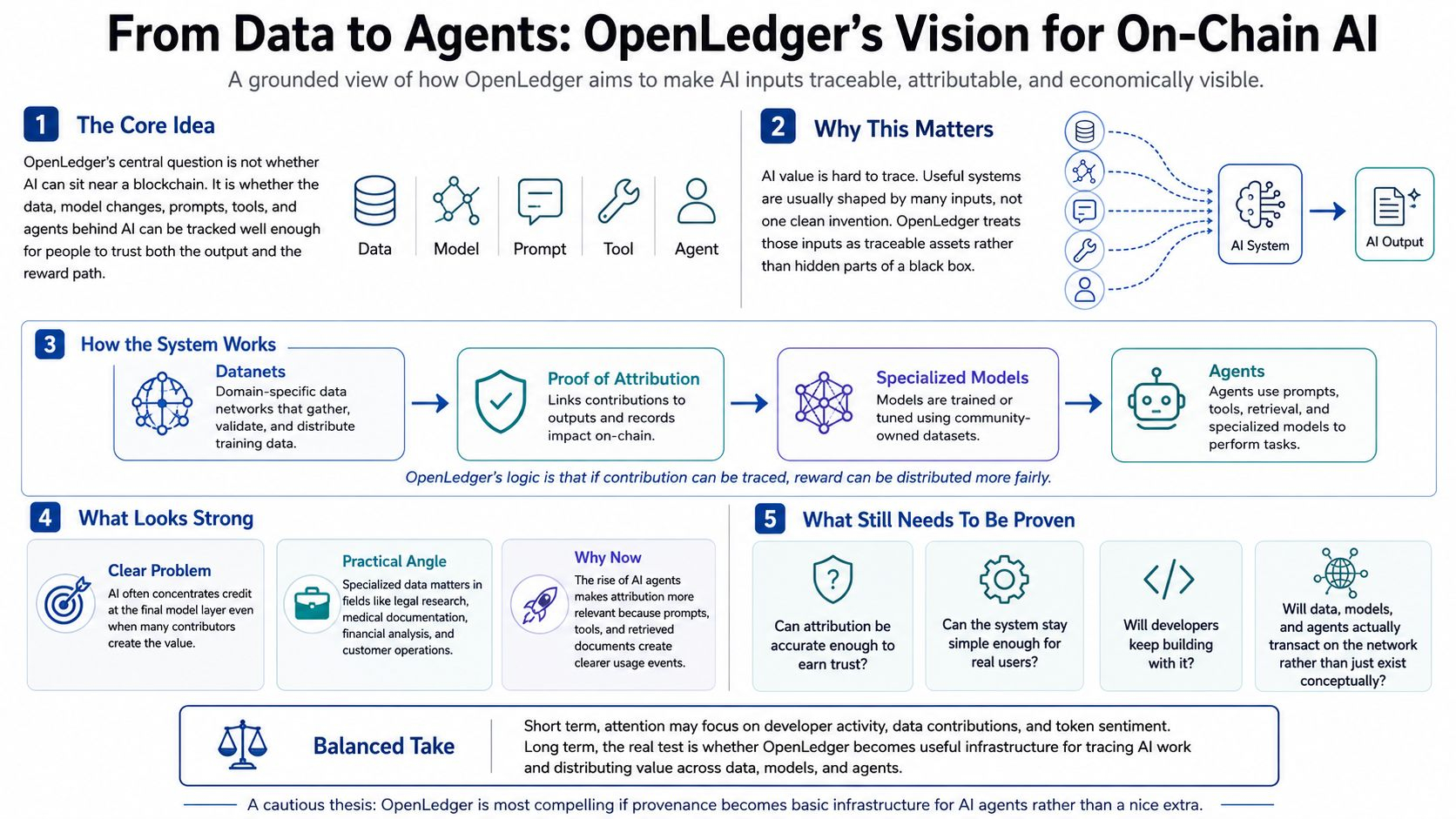
That framing matters because AI value is hard to trace. A useful model rarely comes from one clean invention because it is usually shaped by collected data and labeling work and fine-tuning and prompts and tool connections and documents retrieved at the moment of use. OpenLedger’s deeper thesis is that these pieces should not disappear into a black box. They should become traceable assets. I find it helpful to look at the project less as AI on a blockchain and more as accounting rails for AI labor.
The clearest part of the design is Datanets. In OpenLedger’s docs Datanets are decentralized data networks that gather and validate and distribute domain-specific datasets for model training. The point is not just to store data. It is to create a structure where contributors can add specialized material and retain attribution. That is a sensible place to start because general models are already strong for broad tasks while many valuable uses still depend on narrow and reliable data. Legal research and medical documentation and financial analysis and customer operations all become more useful when the model understands a specific setting.
Proof of Attribution tries to turn that idea into an economic system. OpenLedger says it links data contributions to model outputs and keeps an on-chain record while rewarding contributors based on the impact of their data. That is the elegant part because it connects ownership and usage and payment in one loop. It is also where I see the hardest assumption. Measuring influence inside AI systems is not simple. A dataset can help a model in subtle ways and an output may draw on many sources unevenly. If attribution becomes too rough then contributors may not trust it. If it becomes too complex then users may ignore it.
The agent angle is why this feels more relevant now than it might have five years ago. Back then the question was whether decentralized data could improve model training. Today AI systems retrieve live context and call tools and follow prompts and carry out tasks. OpenLedger’s own agent writing describes a stack built from specialized models and Datanets and ModelFactory and OpenLoRA and MCP-style tool access and retrieval systems with prompts treated as reusable behavior logic. What surprises me is that the agent story makes attribution more practical and more demanding at the same time. When an agent uses a tool or pulls a document or follows a prompt there is a clearer event to record. There are also more moving parts to govern.
From a market perspective I would not judge OpenLedger only by whether people like the phrase AI blockchain because that phrase is too broad. I would watch for signs that contributors keep adding valuable datasets and developers use the tooling to launch models or agents and the attribution system creates rewards that feel credible rather than symbolic. The OPEN token is already tracked publicly through market data sites that list circulating supply and market cap and trading volume. That means short-term participants will watch liquidity and sentiment. The longer-term case depends less on daily price movement and more on whether OpenLedger becomes a place where data and models and agents actually transact.
The strength of the project is that it points at a real weakness in AI because value is created by many contributors while credit often pools around the final model owner. The risk is that solving that fairly may require more precision and adoption and trust than a protocol can quickly deliver. My conclusion is cautious but interested. OpenLedger’s vision is strongest if agents become common enough that provenance is not a nice extra but basic infrastructure. If that happens then the project is testing whether AI needs a ledger of responsibility beneath it.
