Been thinking about something that doesnt get talked about enough in crypto.
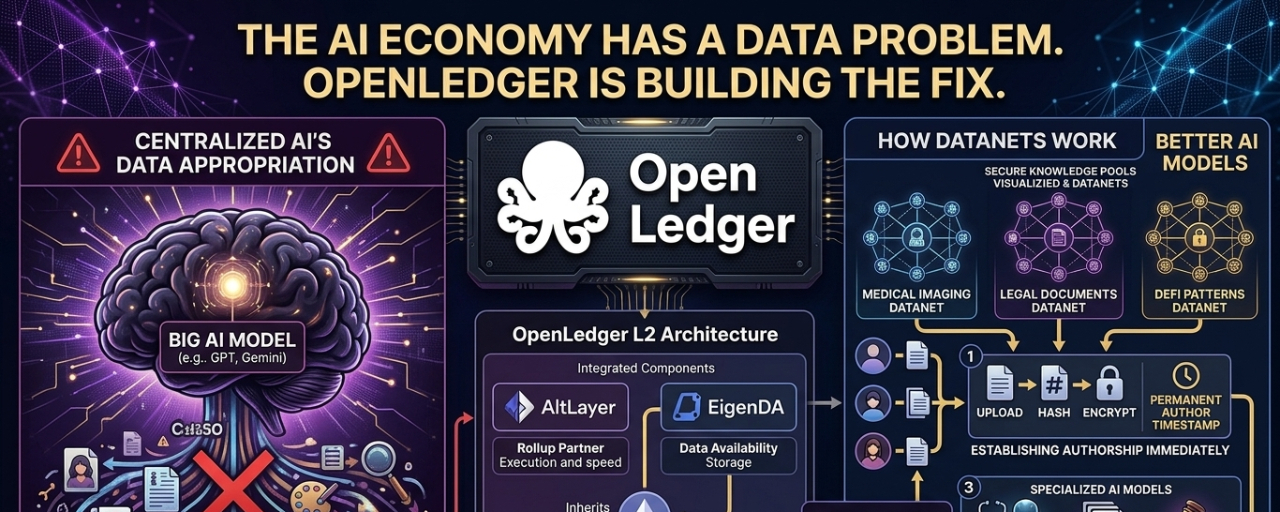
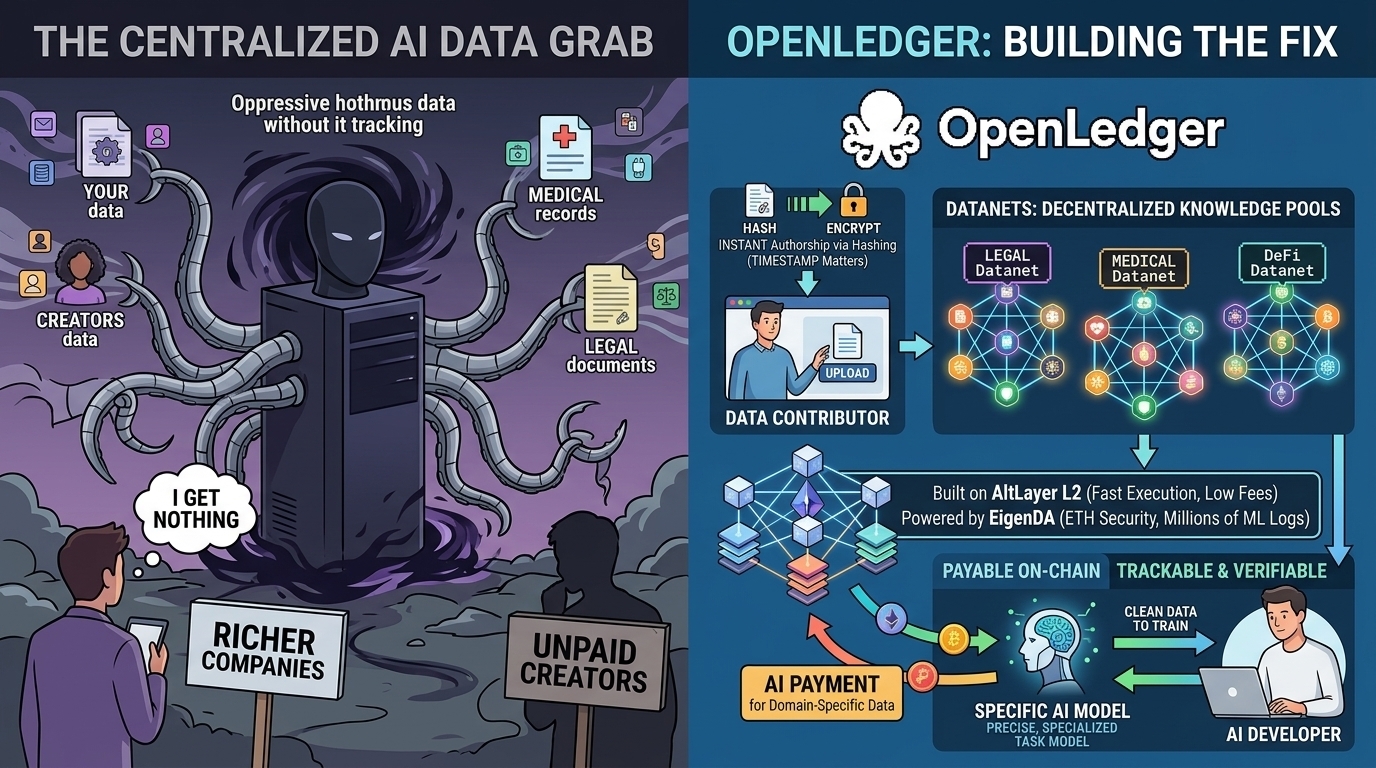
Every major AI model you have used was trained on data that wasnt theirs. Your data. Creators data. Medical records. Legal documents. All of it pulled into training pipelines without tracking, without consent, and definitely without payment.
The model gets smarter. The company gets richer. The people who actually created the data get nothing.
Thats not a theory. Thats just how centralized AI works right now and nobody is talking about it.
OpenLedger is built to change that.
What OpenLedger Actually Is
Most projects calling themselves AI plus blockchain are just GPU rental with a token on top.
OpenLedger is structurally diffrent. Its a Layer 2 blockchain built specifically for one thing. Making data ownership trackable, verifiable and payable on chain.
The network runs through AltLayer as its rollup partner giving it fast execution and low fees. For data it uses EigenDA which inherits Ethereums security meaning the chain can handle millions of machine learning logs without slowing down.
It is not trying to be a general purpose chain. Its built for AI data infrastructure and nothing else. That focus is actually the whole point.
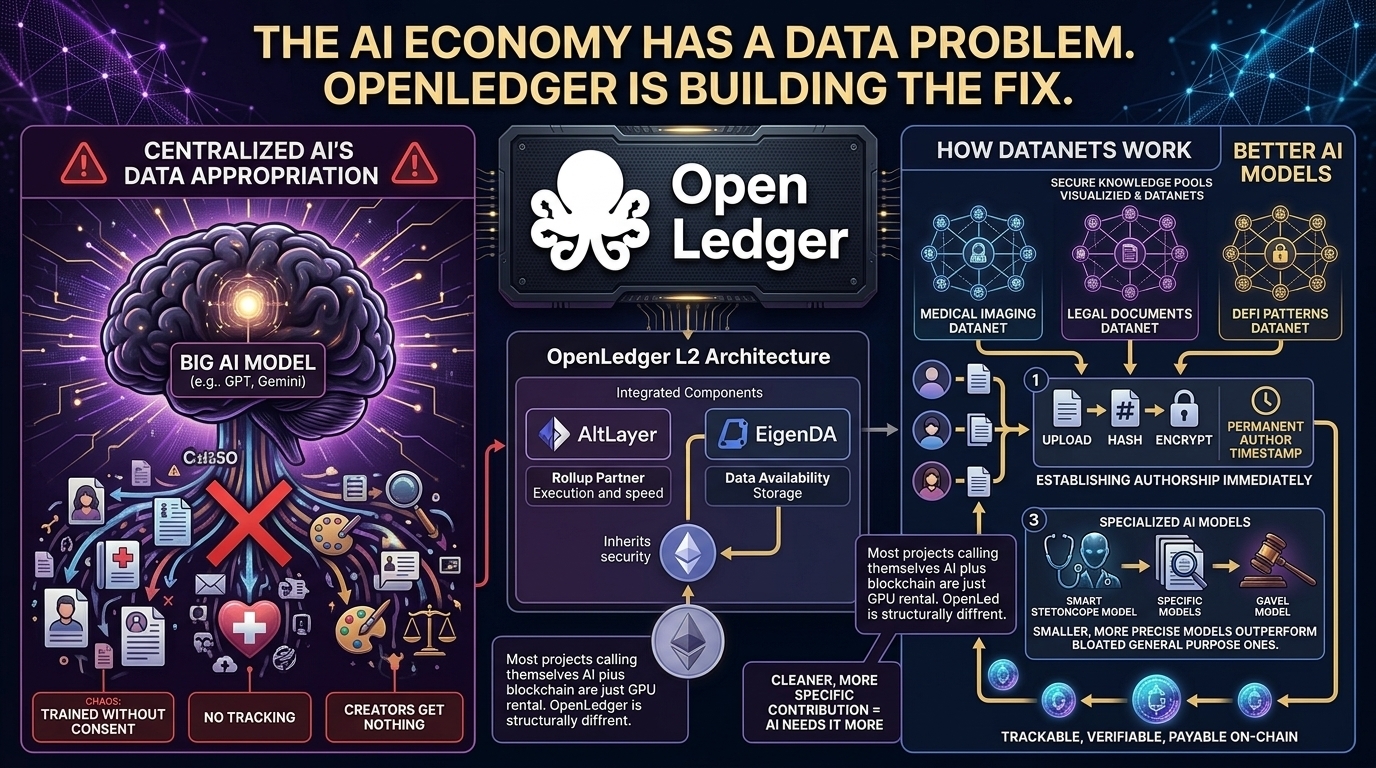
Datanets. Where the Data Lives
Instead of one giant database owned by one company OpenLedger organizes data into Datanets. Decentralized topic specific knowledge pools built and managed by $OPEN communities.
Think of a Datanet like a crowdsourced knowledge club for a specific domain. Legal documents. Medical imaging. DeFi transaction patterns. Each one is community managed and open to contributors worldwide.
When you contribute data your upload gets hashed and encrypted imediately. Permanently establishing authorship before anything else happens. That timestamp matters more than most people realize.
AI developers then pull from one or multiple Datanets to train smaller more precise models built for specific industries. These specialized models consistently outperform bloated general purpose ones on domain tasks.
The cleaner and more specific your contribution the more an AI model actually needs it.
Thats where the the money comes from.
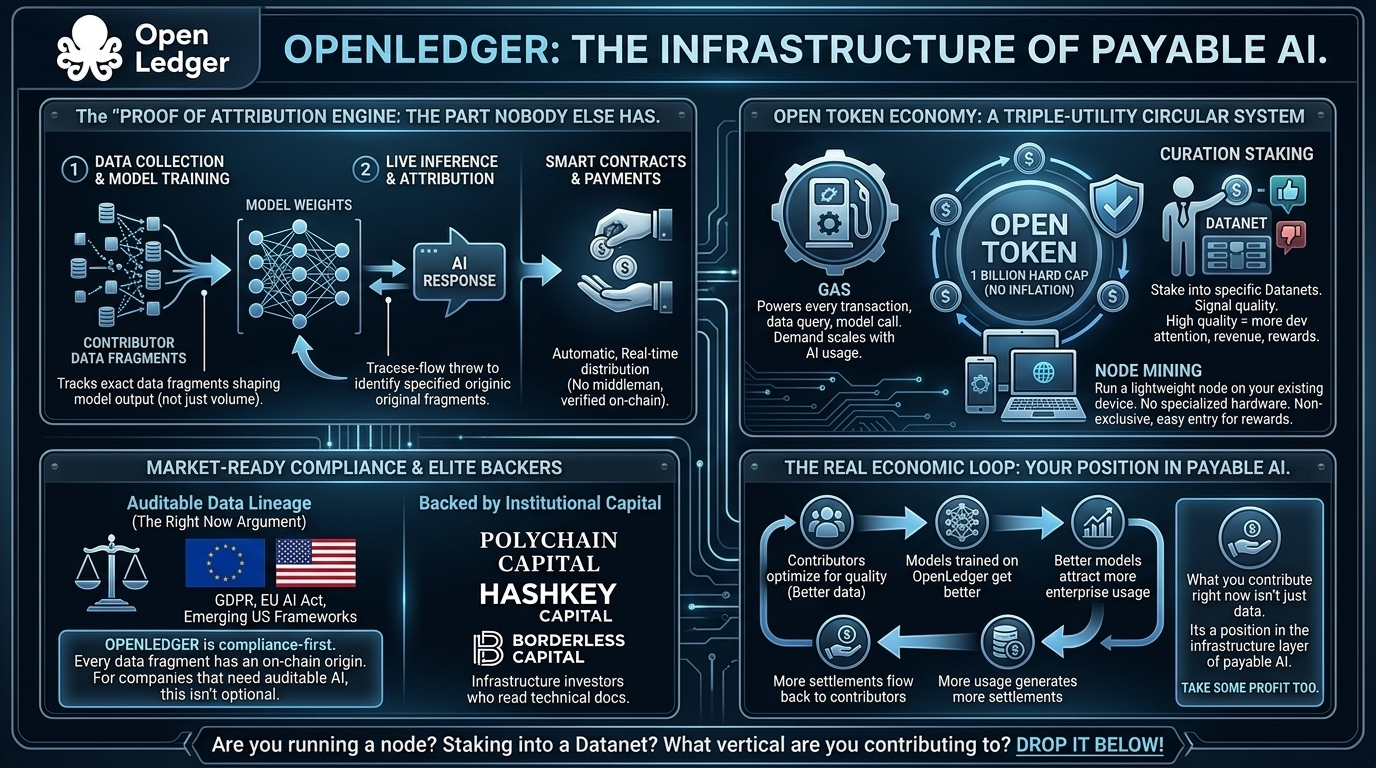
Proof of Attribution. The Part Nobody Else Has
This is what i keep coming back to.
Every other data monetization project pays contributors based on volume. How much you uploaded. How many times you showed up. OpenLedger does something technically harder and economically smarter.
Its Proof of Attribution engine tracks exactly which data fragments actually influenced a models output. Not just during training but during live inference too. Every time an application triggers an AI response the mechanism traces back through the models weights and identifies which contributors data shaped that specific output.
Smart contracts then execute automatically distributing payments directly to those data owners in real time.
No middleman calculating your share. No quarterly payouts. No trust us on the math. Its verified and settled on chain the moment a model runs.
Replicating that attribution infrastructure from scratch would take years. Thats a real moat.
The $OPEN Token. How the Economy Works
Hard cap. 1 billion tokens. No inflation creeping up on you later.
OPEN runs three jobs inside the network at the same time.
Gas. Every transaction, data query and model call runs on OPEN. As AI usage scales gas demand scales with it.
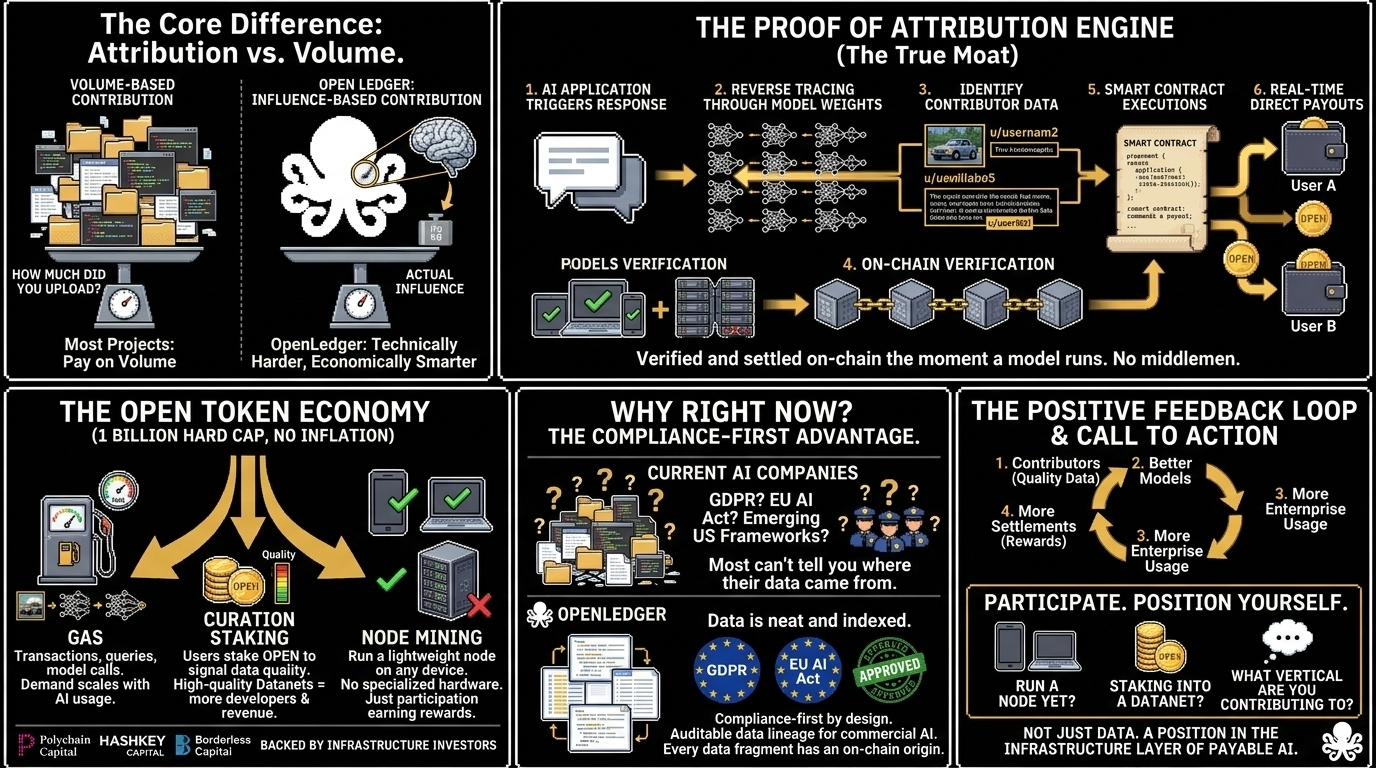
Curation staking. Users stake OPEN into specific Datanets to signal data quality. High quality Datanets attract more developers generate more revenue and distribute more back to stakers. Low quality contributions dont get banned. They just stop earrning.
Node mining. Anyone can download the app and run a lightweight node on their existing device. No specialized hardware. No big upfront cost. Just participation earning rewards.
Backed by Polychain Capital, HashKey Capital and Borderless Capital. These are infrastructure investors who read technical docs before writing checks.
Why Right Now Makes Sense
The enterprise AI market is running into a wall.
Regulatory pressure on data provenance is accelerating everywhere. GDPR. The EU AI Act. Emerging US frameworks. All of them moving toward requiring auditable data lineage for commercial AI systems.
Most AI companies currently cannot tell you where their training data came from. That is becoming a legal problem not just an ethics conversation.
OpenLedger is compliance first by design. Every data fragment has an on chain origin. Every attribution is verifiable. For companies that need auditable AI and increasingly they all do this isnt optional anymore.
The Part I Keep Getting Stuck On
Once contributors understand what the system rewards they optimize toward it.
Better data. More specific contributions. Cleaner datasets for high value Datanets.
And as more quality data flows in the models trained on OpenLedger get better. Better models attract more enterprise usage. More usage generates more settlements. More settlements flow back to contributors.
Thats not hype. Thats a real economic loop with a technical mechanism behind it.
What you contribute right now isnt just data.
Its a position in the infrastructure layer of payable AI.
Take some profit too.

ps : Running a node yet. Staking into a Datanet. What vertical are you contributing to, drop it below
$OPEN #OpenLedger @OpenLedger #open