I have a simple test I apply to AI tokens before spending time on them. I try to find one thing the token structurally must do for the network to function. Not something it can do, not something a whitepaper says it will do someday, something it has to do right now for the system to work. Most AI tokens fail that test immediately. $OPEN passed it three times and that is what made me keep reading.
What I keep coming back to is this. Most AI token demand is speculative because the token is not embedded in actual AI activity. OpenLedger embedded OPEN into three layers of its network simultaneously, and whether that design holds at production scale is the genuinely interesting question.
Start with gas. Every transaction on the OpenLedger network requires OPEN to process. This is not optional participation or a governance bonus. Data submissions, model training, agent deployments,
on-chain attributions all of it requires the token to move. That baseline demand scales directly with network activity. When more models are trained, more OPEN moves. The relationship is mechanical rather than narrative, and that is rarer than it sounds in this space.
The inference fee layer is where the demand logic gets more interesting. Every time a developer queries an AI model deployed on the network, they pay an inference fee in OPEN. The team's own documentation describes it as the primary fee token for running inference and building new AI models. In a network where model usage is the intended core activity, tying every query to a token payment creates a more direct demand mechanism than most AI infrastructure projects have designed. The honest question is how many inferences are actually being processed, and the publicly available data does not yet answer that clearly.
The attribution reward layer is the one I find hardest to dismiss. When a model produces an output, the Proof of Attribution system maps which training data influenced that output and routes $OPEN automatically to the contributor. Data contributors are not earning tokens for uploading files. They are earning specifically when their data gets used in a production inference.
That distinction matters because it creates an incentive for contributing genuinely useful data rather than bulk noise. Contributors who provide high impact datasets earn more. The token is the enforcement mechanism for that quality filter, which is a genuinely novel design.
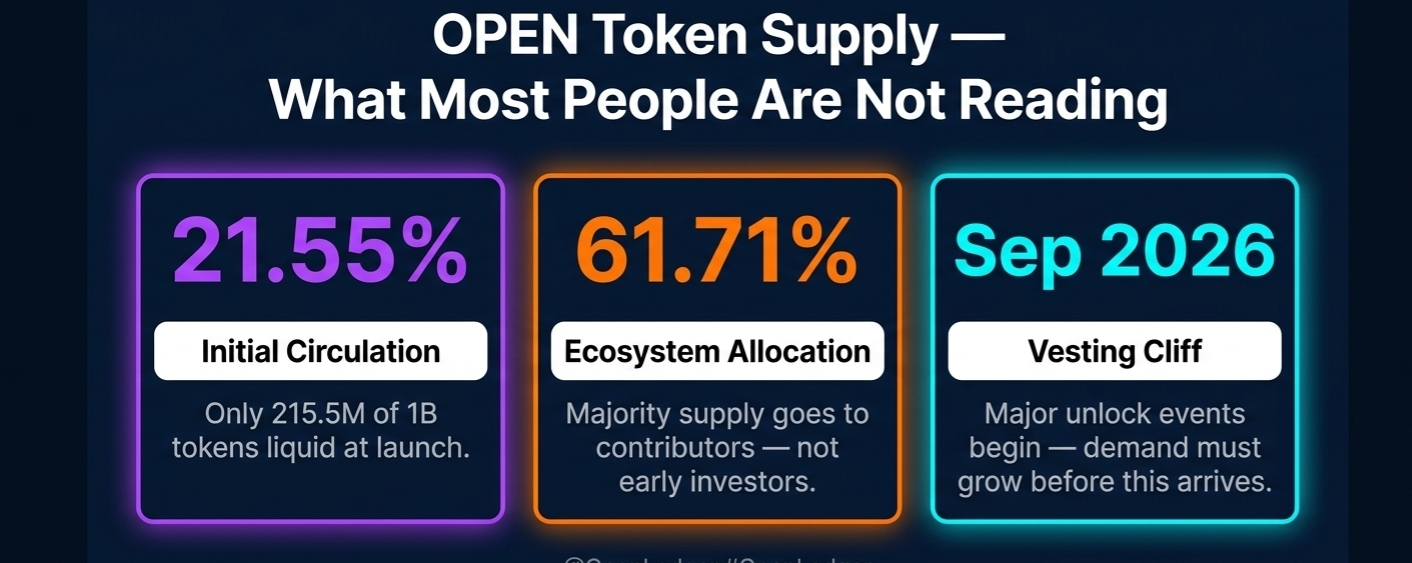
The supply architecture is where I spent most time sitting with the numbers. At TGE in September 2025, 215.5 million tokens became liquid out of a 1 billion maximum. That is 21.55 percent initial circulation. The allocation breakdown is more interesting than the headline. A total of 61.71 percent of all supply is allocated to ecosystem participants and contributors, not to early investors. The early investor allocation is 18.29 percent. Team tokens follow a 12 month lockup with 36 month linear vesting. The community orientation of the distribution is genuine rather than cosmetic, though 61.71 percent community allocation over 48 months also means sustained emission pressure that ecosystem demand needs to keep absorbing.
The buyback program announced in late 2025 added a layer the original tokenomics did not include. The OpenLedger Foundation committed 5 million dollars funded entirely by enterprise revenue to repurchase tokens from the open market. The detail that matters is the funding source. Treasury funded buybacks are accounting operations.
Revenue funded buybacks indicate the commercial side is generating real income. Whether that program continues as the team builds out OpenFin and the AI Marketplace is something I will be watching closely.
The vesting timeline is the risk I cannot argue away. Major investor and team unlock cliffs arrive around September 2026.
At that point significant new supply starts entering monthly. Whether organic demand from model inference, data attribution, and ecosystem growth absorbs that supply without sustained sell pressure is what the next 12 months will start to answer.
Now I have to argue against my own reading because the tokenomics case has real weaknesses.
The first problem is that structural demand and actual demand are different things.
Gas fees require OPEN, yes. But if the network has limited model deployments and minimal inference volume, the structural demand is theoretically sound and practically trivial. The mainnet launched in November 2025. We are several months in. The number of production grade models actually running is not clearly disclosed in public data, which makes it genuinely difficult to assess whether the inference fee layer is generating meaningful token velocity or running close to idle.
The second problem is the unlock timeline. September 2026 is close enough to matter for anyone thinking about this token on a 12 month horizon. If ecosystem demand does not visibly accelerate before that cliff, incoming supply arrives into a market that has not yet demonstrated the absorption capacity the design requires. The 5 million dollar buyback helps at the margin. It does not change the fundamental math.
The signals I am watching are specific. Whether inference volume data becomes publicly trackable on-chain, because that single number tells me whether the gas and inference fee demand is real or theoretical. Whether the buyback program is renewed after its initial deployment funded by revenue, because renewal would confirm the commercial model is generating sustainable income.
Whether model deployments grow quarter over quarter after mainnet stabilization. And whether the team discloses any metrics around actual Proof of Attribution payouts, because attribution events happening at scale would be the clearest signal that the token design is working as intended rather than existing cleanly on paper.