AI infrastructure used to sound boring. When people said infrastructure, I used to think about roads, ports, power lines, or maybe cloud servers if the conversation was more technical. It was the invisible layer that only became noticeable when it failed. Then AI changed the meaning of the word. Suddenly infrastructure became exciting. GPUs became a market story. Compute became a scarcity narrative. Data centers started sounding like the new oil fields. For a while, I believed the same thing most people believed: that the biggest bottleneck in AI was simply power, speed, and scale.
But the more I watch AI move from demos into real commercial use, the less convinced I am that intelligence is the hardest problem. A model writing a weak poem or giving a bad summary is one thing. A model influencing loan decisions, assisting with compliance, helping agents move capital, supporting legal drafts, screening identities, or shaping financial workflows is something else entirely. Once AI starts touching serious decisions, the question changes. People stop asking how fast the model is. They start asking something much more uncomfortable: who is responsible when the output causes damage?
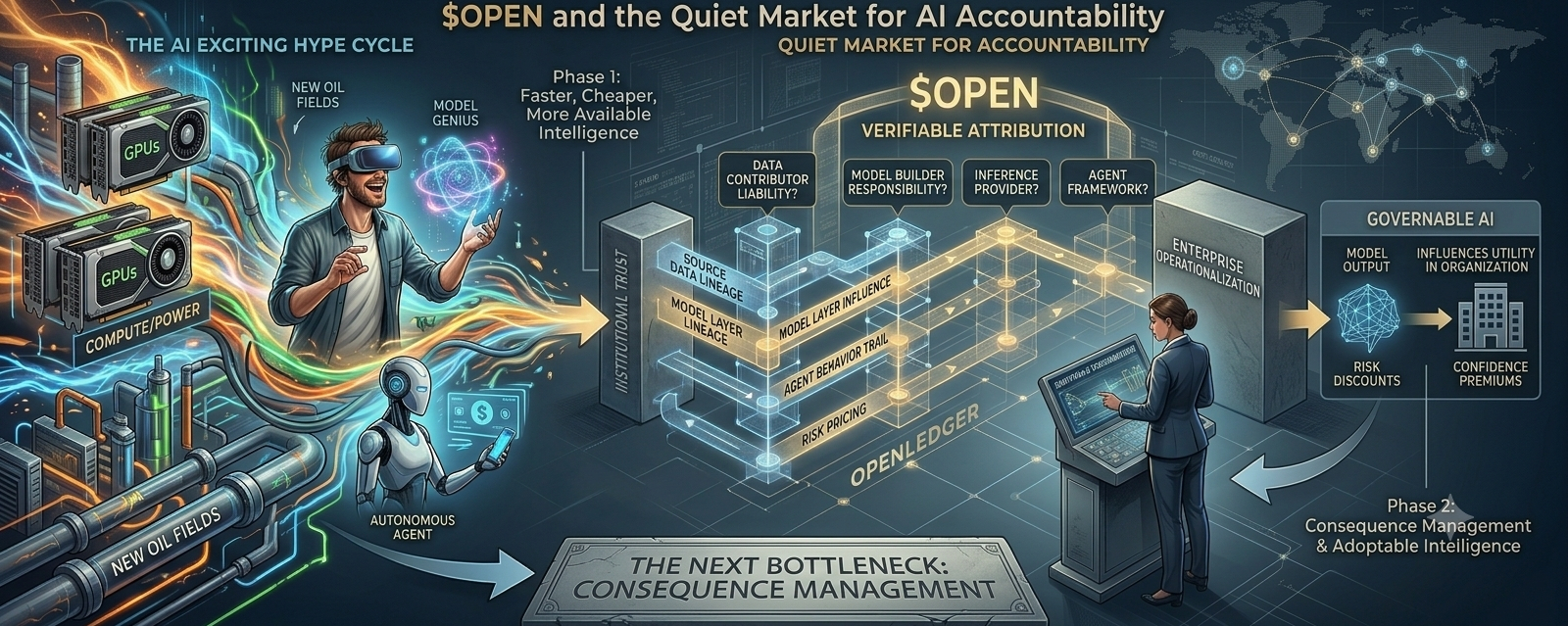
That question still feels missing from most crypto AI conversations. A lot of projects talk about agents, models, data, compute, and rewards, but far fewer talk about accountability in a way that feels serious. OpenLedger usually gets described as AI infrastructure, and that label is not wrong, but I think it may be too small. The more interesting angle is not just that OpenLedger could reward contributors or create better attribution. The bigger idea is that attribution may become a liability map for AI systems that actually matter.
That distinction matters. Attribution sounds friendly when it is framed as fairness. It sounds like contributors getting paid for the value they helped create. That is a strong narrative, but it may only be the first layer. In real-world AI systems, attribution could become something much heavier. It could help explain where an output came from, which data shaped it, which model layer influenced it, and where responsibility may sit when something breaks. In that version of the story, OPEN is not only attached to rewards. It is attached to trust, risk, and consequence management.
This is where I think a lot of the early autonomous agent hype moved too quickly. People imagined agents making payments, negotiating services, buying compute, managing workflows, and moving through Web3 like independent economic actors. That future may still come, but the market often skipped the uncomfortable middle part. If an agent makes a bad decision because it was shaped by flawed data, manipulated inputs, or weak source logic, who takes the hit? The data contributor? The model builder? The inference provider? The agent framework? The end user? The answer gets messy very quickly.
Traditional software at least had a clearer structure. A company shipped the code. If something went badly wrong, accountability could usually be traced back through contracts, vendors, and product ownership. AI is different because responsibility can be spread across many layers before the final output ever reaches the user. Data comes from one place. Fine-tuning happens somewhere else. Retrieval adds new context. Another system handles inference. Another layer controls agent behavior. By the time the result appears, responsibility is no longer clean. It is scattered across the stack.
And when responsibility becomes blurry, risk becomes harder to price. Markets do not like that. Institutions like it even less. Retail users may accept mystery when a product feels powerful or magical, but enterprises do not operate that way. Banks, insurers, legal teams, compliance departments, and regulated businesses need more than impressive outputs. They need audit trails, documentation, escalation paths, source lineage, and some practical way to explain what happened when a decision gets challenged later. Nobody serious walks into a compliance meeting and says the model felt trustworthy.
That is why OpenLedger interests me more than the standard AI token discussion. If it is genuinely building infrastructure around verifiable attribution, then the real question may not be whether it helps AI scale. The better question may be whether it helps AI become governable. That is less flashy than compute. It does not sound as exciting as autonomous agents trading on-chain or models generating alpha. But boring control layers often end up mattering longer than the exciting surface layer.
Financial markets are a useful comparison. At first, speed was the obsession. Then auditability became essential. Then compliance systems, reporting layers, settlement infrastructure, and risk controls became part of the real machine. The visible trade was only one piece of the system. The invisible trust architecture made large-scale participation possible. AI may not follow the same path perfectly, but it feels like it could rhyme. Intelligence may attract attention first. Accountability may decide who actually gets adopted.
The practical reality is simple: institutions are not allergic to innovation. They are allergic to uncertainty they cannot operationalize. A procurement team considering AI integration does not care about crypto-native storytelling. They care whether the system can be explained when legal, compliance, or regulators start asking questions. And sooner or later, they always ask questions. If an AI workflow supports insurance risk assessment and produces biased outputs because part of the underlying data pipeline was flawed, nobody will be satisfied with vague answers. The organization will need to trace what happened, where the weakness entered, and how the system can be corrected.
That is where attribution stops being philosophical. It becomes operational. It becomes part of risk management. It becomes part of enterprise trust. It becomes part of whether a system is safe enough to integrate into real workflows. This is why the idea of OPEN pricing model liability does not feel exaggerated to me. I do not mean legal liability in the strict courtroom sense, at least not immediately. I mean economic liability first. Risk discounts. Confidence premiums. Counterparty trust. Integration willingness. These things get priced by markets long before legal frameworks become fully mature.
If two AI ecosystems produce similar outputs, but one can provide stronger provenance around how those outputs were shaped, the more auditable system may win even if it is slightly less glamorous. That happens all the time in serious industries. Trusted supply chains beat uncertain supply chains. Auditable financial infrastructure beats opaque alternatives. Reliable control systems quietly win budgets because they reduce uncertainty. In high-stakes environments, trust is not decoration. Trust is infrastructure.
Still, I do not think this is an easy thesis. Attribution in AI is extremely hard. Models do not work like simple ingredient lists. Training effects are diffuse. Influence is messy. Contribution weighting can become more like probabilistic storytelling than hard truth if the system is poorly designed. That matters because fake accountability may be worse than open opacity. If a system claims to explain responsibility but cannot actually withstand scrutiny, it creates a new layer of risk instead of reducing the old one.
Crypto makes the challenge even sharper. The moment attribution has economic value, people will try to game it. Spam datasets, fake contribution claims, sybil reputation games, manufactured signals, artificial trust farming—none of this is theoretical. Anyone who has watched crypto incentive systems for long enough knows what happens when rewards meet weak verification. OpenLedger’s system has to survive adversarial behavior, not just clean demos and ideal contributors. That is the real test.
There is also a deeper product question. Do enterprises actually want decentralized accountability? In theory, it sounds elegant. In practice, many institutions prefer centralized vendors because responsibility feels simpler. One provider. One contract. One support line. One escalation path. Distributed attribution only works if it becomes operationally useful, not just intellectually impressive. If it adds confusion, it will struggle. If it reduces uncertainty, it becomes valuable.
That is why OpenLedger’s challenge is bigger than technology alone. It has to make attribution feel usable. It has to turn a complex contributor network into something enterprises, developers, and AI systems can actually rely on. The market may talk about OpenLedger as AI infrastructure, but the more interesting possibility is that it becomes infrastructure for accountability. Not just who helped build the model, but how confidence, responsibility, and value move through the system.
I keep coming back to the idea that AI conversations are still stuck in phase one. Everyone is still obsessed with making intelligence faster, cheaper, and more available. That matters, but it may not be the next bottleneck. The next bottleneck may be consequence management. Intelligence without accountable lineage works fine for entertainment. It becomes much harder when money, identity, compliance, and regulated decisions enter the picture.
That is why $OPEN feels more interesting to me than a simple AI infrastructure token. It may not be competing in the category most people think. Not just compute. Not just model access. Not just data rewards. Something quieter and possibly more durable: reducing uncertainty around machine decisions. That is not the loudest thesis in the market. It is not the easiest one to sell in a hype cycle. But sometimes the most important infrastructure is the part nobody notices until the system becomes too important to fail.