
我有个做数据标注的朋友,去年接了个AI公司的兼职,活儿听起来不复杂:看模型生成的几段文字,打打分,写几句理由。时薪三十块,他还觉得挺划算。
吭哧吭哧干了两周,忽然收到一封通知——他的反馈被判定为“质量不合格”。不光后面的钱不给了,连之前发下来的工资都得退回去一部分。
他整个人是懵的。谁判定的?标准是什么?哪怕给个申诉入口也行吧?对方的回复又冷又硬:内部算法自动评估,不可申诉。
他后来跟我喝酒的时候苦笑了一句:“我还以为是我在教AI,搞了半天,是AI在教我做人。”

当时我听完,只觉得那家公司不地道。直到我翻 @OpenLedger 白皮书,在第12页看到RLHF那一节,那种熟悉的、不舒服的感觉又顺着脊背爬了上来。
白皮书上写得很明确:提供高质量反馈的用户,会获得质押奖励;而那些试图操纵系统的,则会面临质押罚没。
高质量反馈——奖励。操纵系统——罚没。
可谁来定义什么是“高质量”?什么是“操纵”?这道要命的填空题,白皮书一个字都没填。
这让我觉得,这里藏着一个你无法申诉的裁判,而它的名字就叫“系统”。
RLHF,也就是基于人类反馈的强化学习,是眼下对齐AI模型的主流路子。白皮书第12页把奖励函数的公式摆出来了,看着挺像回事:奖励等于一系列权重乘上验证者给出的分数,再减去一些损失项。而这个分数,据说是基于正确性和可解释性打的。
那么,这个手握打分板的“验证者”到底是谁?白皮书没有明确定义,就那么含糊地悬在那儿。
顺着上下文去猜,验证者可能是质押了OPEN的节点,可能是专门挑出来的评审委员会,也可能是所有社区成员一起投票。可不管披着哪张皮,都绕不开一个让人头皮发麻的核心问题:谁来给这些判卷老师打分?

如果验证者本身也是靠质押量选出来的,那不就又滑回之前聊过的“一元一票”陷阱里去了?大户控制的验证者,完全可以故意给竞争对手的反馈打低分,把人家的质押金罚没得干干净净,顺手还清掉一个对手。
如果验证者是算法自动判定的,那这个算法有没有偏见?谁写的代码?代码上哪儿审计去?白皮书第7页信誓旦旦地说,OpenLedger提供的是“透明、可追溯、可问责”。可偏偏到了RLHF的奖惩环节,这三个词突然像蒙了一层毛玻璃,怎么也看不清。
聊到这儿,$OPEN 代币身上又多了一重新身份:它既是糖果,也是鞭子。
第18页列的“关键用途”里,有一项就是模型优化和对齐,说白了就是RLHF环节的奖励。第12页也白纸黑字说了,高质量反馈能拿到质押激励。这是OPEN作为正激励的那张笑脸。
可同一段话里还藏着另一张冷脸:试图操纵系统的,质押的OPEN会被直接扣走。
也就是说,你手里的OPEN不光是你投票权的凭证,还是你参与RLHF时押上的保证金。一旦系统判定你“不老实”,钱就没了。
这就有意思了——判定过程本身,没有任何公开的标准,也没有一丁点上诉机制的影子。白皮书第17页模型生命周期那块,顺带提了一嘴“低质量贡献可能面临处罚”,可到底什么叫低质量,处罚具体怎么走流程,依然没个交代。
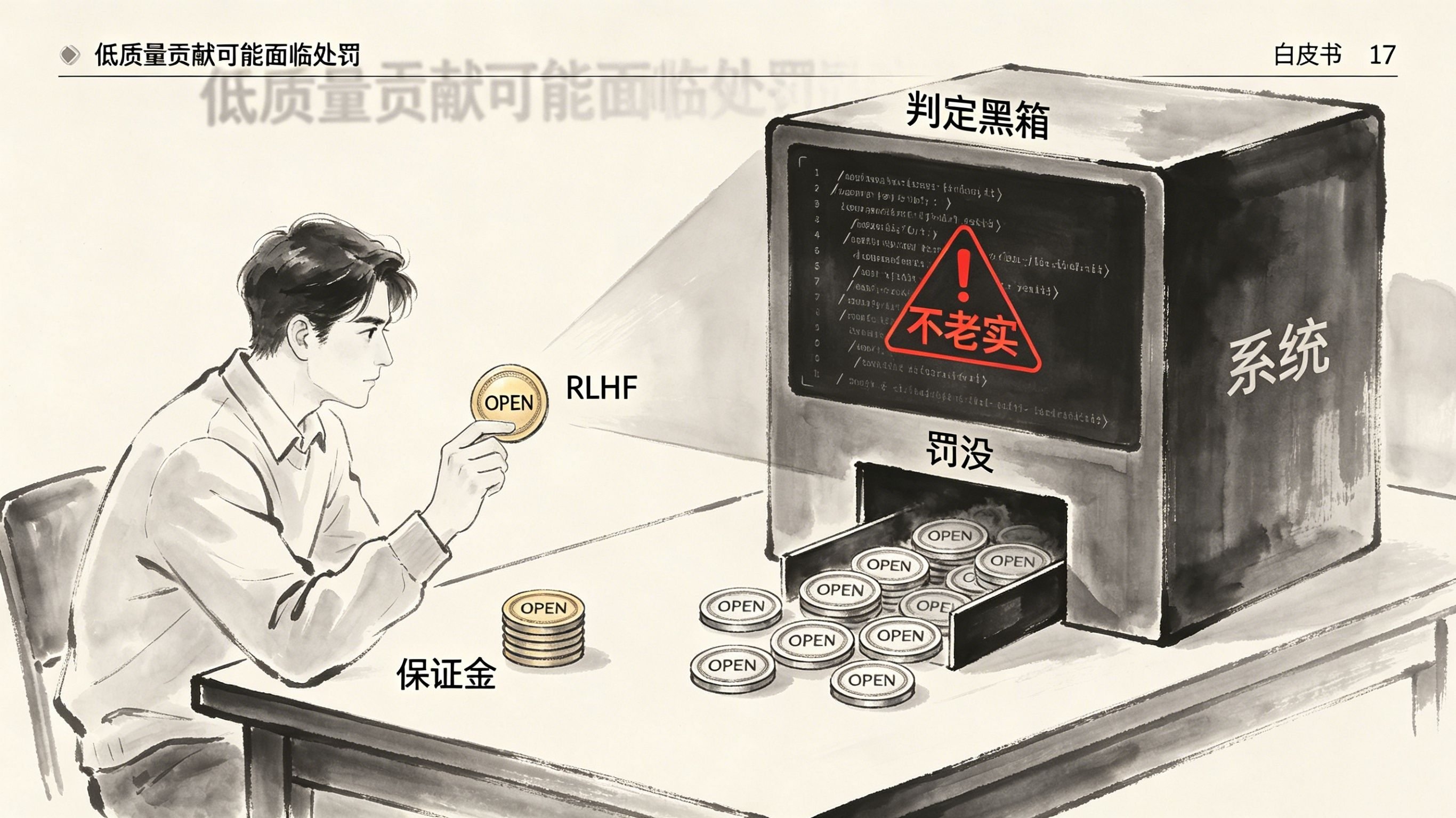
你对比一下DeFi里的清算就明白了:触发条件是明码标价的,价格跌破某个阈值,谁都能验证,没得扯皮。可这里的“低质量反馈”和“操纵系统”,骨子里是主观判断,没法用一个干净的公式来框死。
这就拧成了一个悖论:你信任系统会公正地评判你,可系统本身,正是由那些同样可能被评判的人组成的。这不就是个死循环吗。
我在白皮书里来回翻了好几遍,想找出哪怕一行关于“怎么防止验证者滥用权力”的设计。没找到。
第17页说,人类验证者提供反馈——他们自己就是裁判。那么,裁判踢假球谁来吹哨?白皮书没有设计第二层仲裁,哪怕一个雏形都没有。第20页那个“AI与区块链的协同”图画了个互相强化的漂亮闭环,可闭环里头,偏偏漏掉了“公正性保障”这块承重墙。它似乎默认了所有人都会诚诚实实地投票、诚诚实实地打分、诚诚实实地评判。
但加密行业过去十来年的历史,翻来覆去只告诉我们一件事:只要经济激励摆在那儿,就一定有人憋着劲儿去钻空子。
RLHF环节的激励是一把双刃剑。你可以老老实实提供优质反馈赚OPEN,也可以用阴招,恶意把竞争对手的反馈标记成“低质量”,帮自己人扫清障碍。后面这招要是玩成了,甚至能让对方质押的本金都被罚没,一石二鸟,干净利落。

这不是在编阴谋故事,这是博弈论的基本推演。
坦白讲,OpenLedger的RLHF设计,眼下还停留在“理想模型”的阶段。它假设所有参与者都会自发地手拉手诚实合作。可现实的泥地里,你需要的要么是一个能管住裁判的裁判,要么是一套根本不需要裁判的机制——比如拉上多个验证者交叉验证,再用加密经济的手段把诚实绑成最优策略。
这些东西,白皮书里都没有。
所以,对于琢磨着靠提供反馈赚点OPEN的普通用户,我的想法比较保守:先别往里质押太多。因为你的OPEN不只是未来的收入来源,它同时也是你暴露在风险里的本金。万一哪天系统冷不丁判定你的反馈“质量低”,你可能连底裤都保不住。而那个判定标准,到现在也没人能说清楚个一二三。

我理解,RLHF本身就是一个前沿得有些烫手的领域,学术界都还没彻底搞定“怎么确保人类反馈的质量”这道题。可作为一个要上链、要罚没真实资产的项目,OpenLedger确实欠社区一个交代。也许将来他们会端出多轮交叉验证,或者引入一段有时间锁的争议仲裁期。但在白皮书把这些东西写扎实之前,我大概只会把RLHF奖励当成一种高风险高收益的赌注来掂量。
还是那句老话,自己多做功课。有兴趣的话,不妨直接去他们社区抛个问题:万一我被误判了,我该找谁喊冤?#OpenLedger
引用章节:2.3.3 RLHF (p.12), 5.2.4 Model Inference Payments (p.19), 4.5 Model Optimization (p.17)